第一阶段
你好 python
阶段、章节、小节
初识python
底层:C++ 性能
上层:python 简单高效
什么是编程语言
人类语言翻译成计算机能够听懂的语言→人类与计算机进行交流
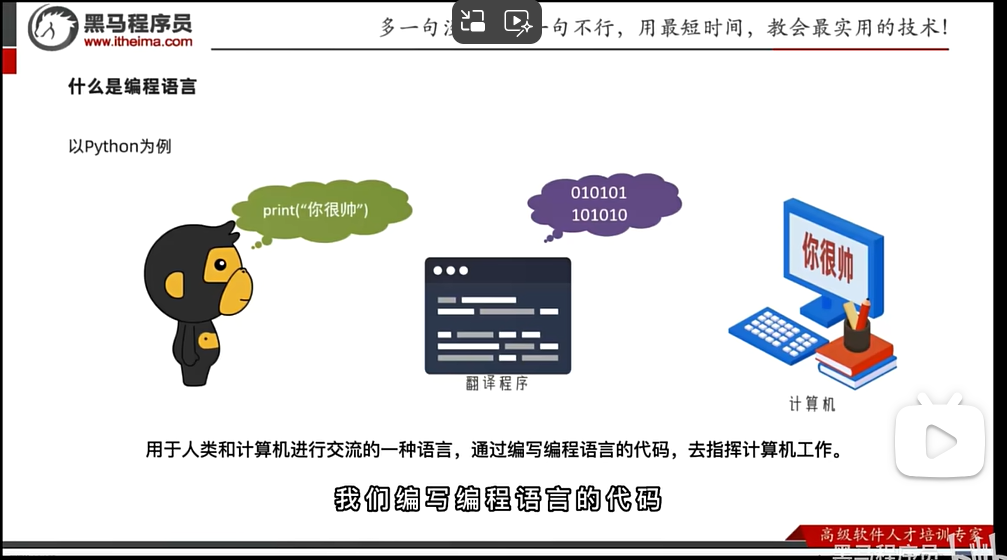
计算机只认识0和1的二进制
由程序(解释器or翻译器)将代码翻译为二进制→计算机get了
(思考:为什么存在十进制呢?)
为什么不直接把中文翻译为二进制?
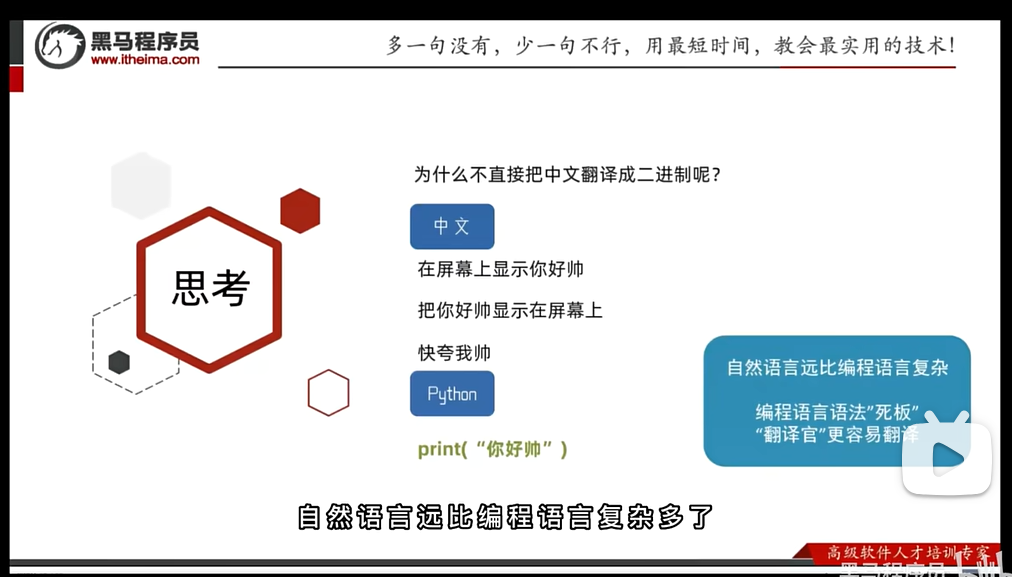
人类的语言有不同的语气、表达,翻译起来更为复杂。
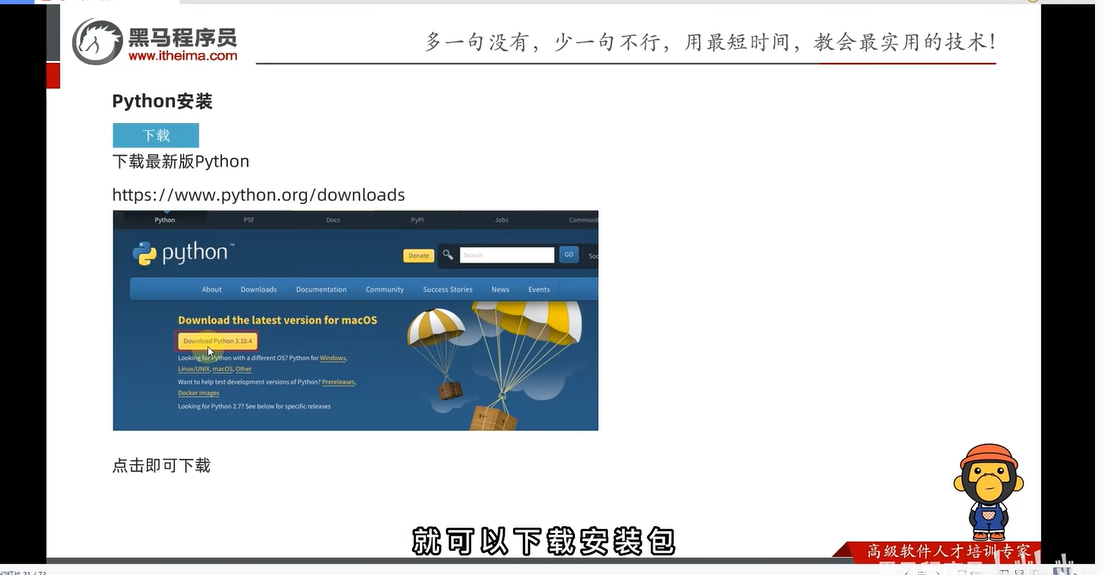
Python环境安装
Python官方网站地址:python.org
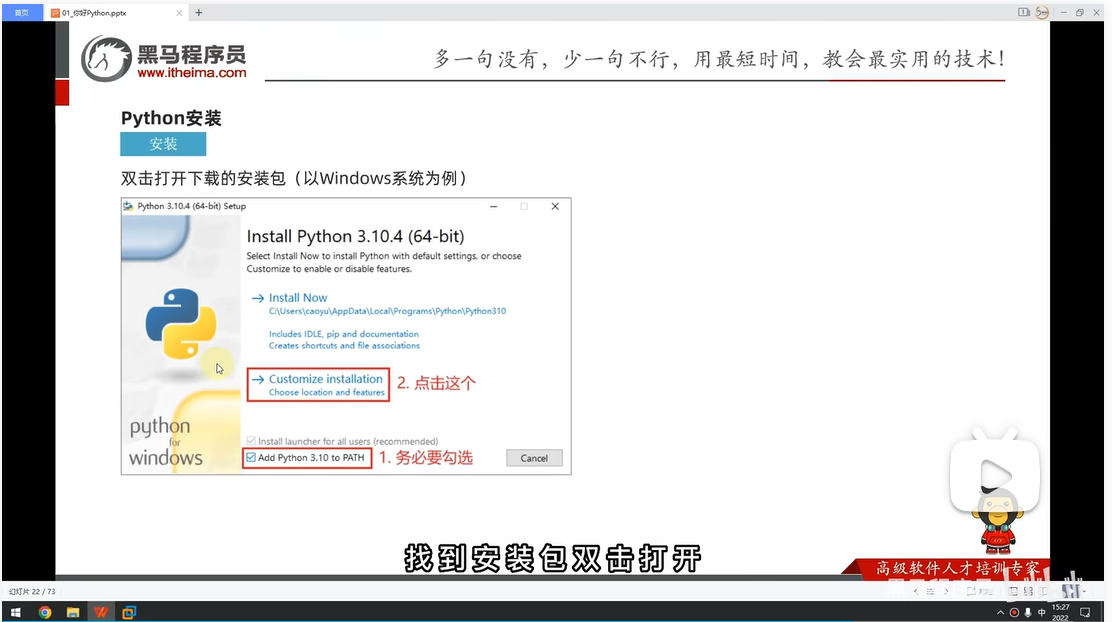
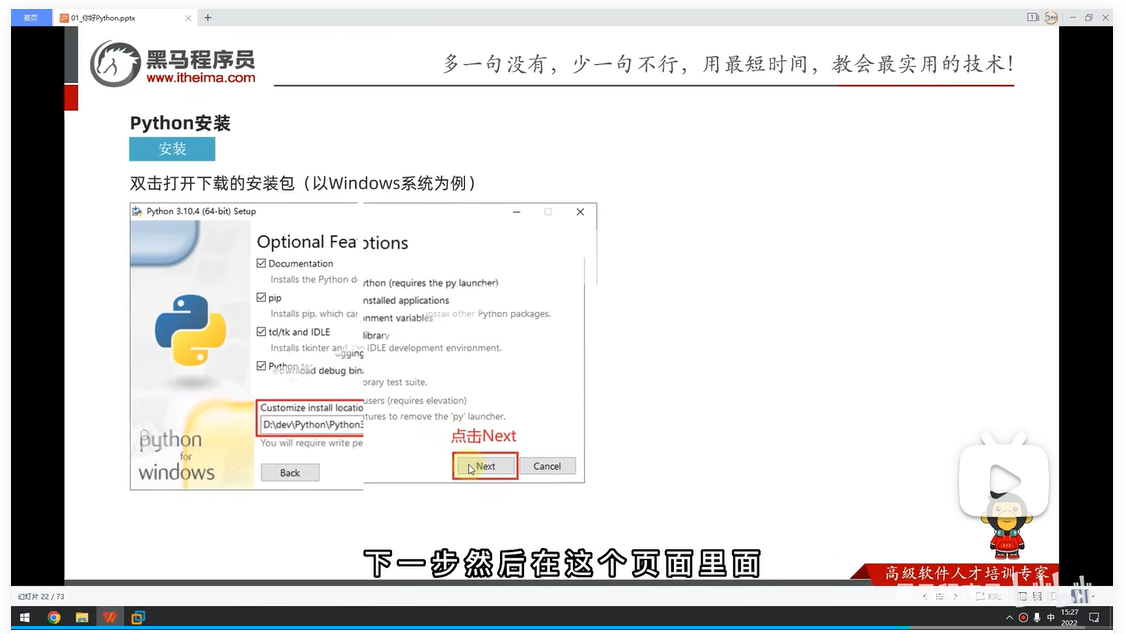
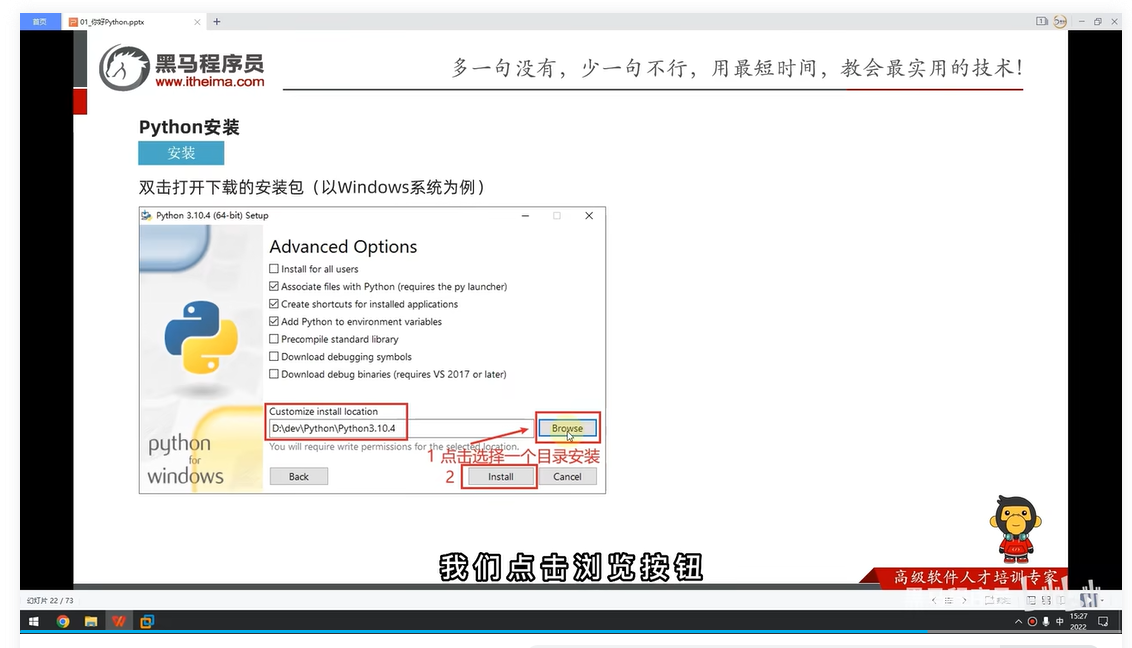
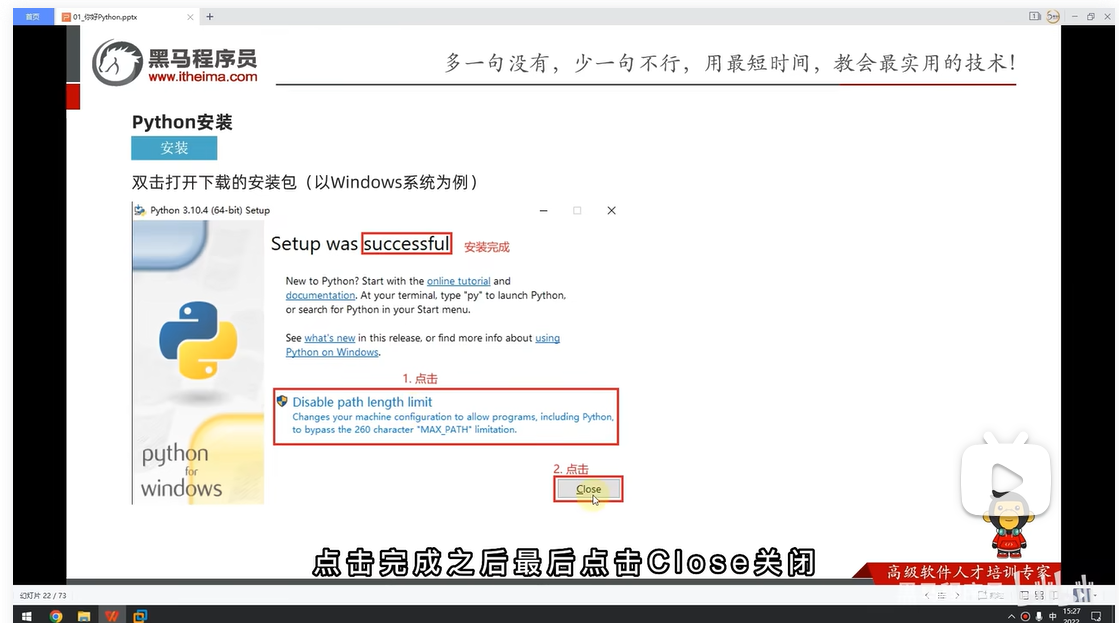
安装完成,验证安装:win-cmd-python
第一个Python程序
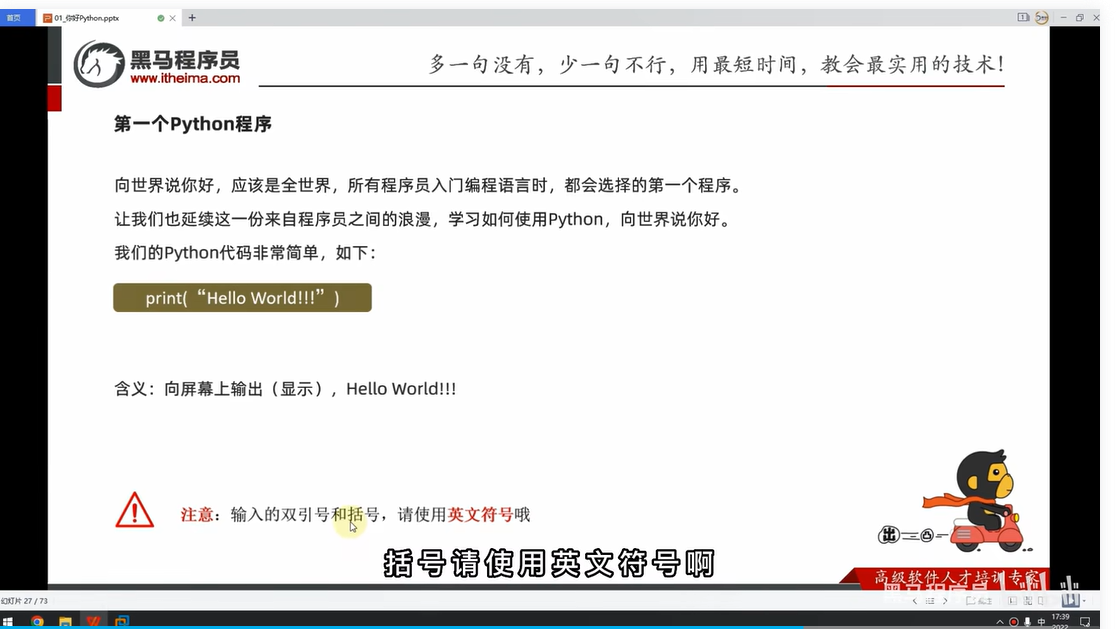
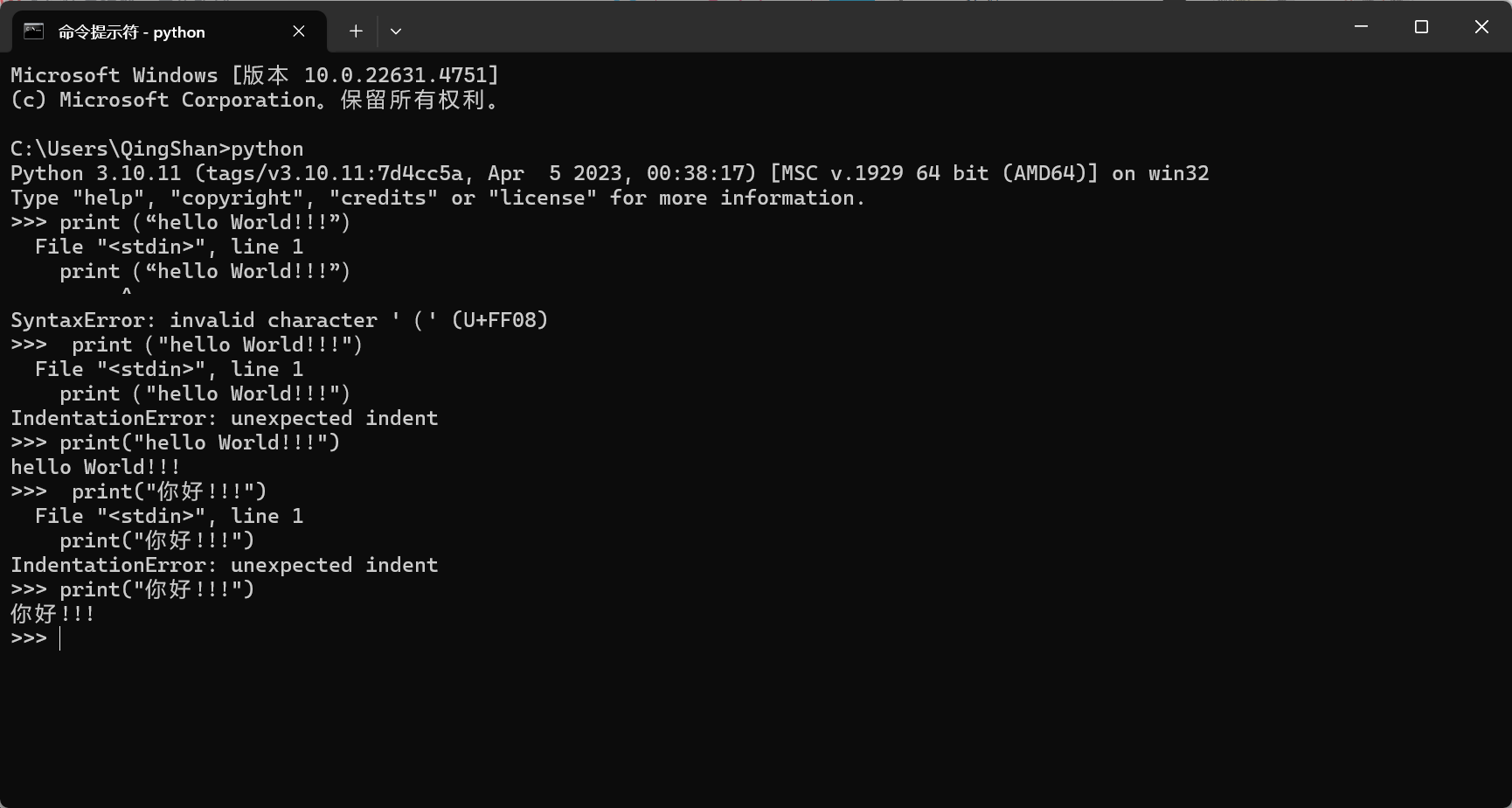
cmd→python→出现三个向右的箭头,表示可以写代码→回车是运行程序
命令指示符:win+r
python解释器
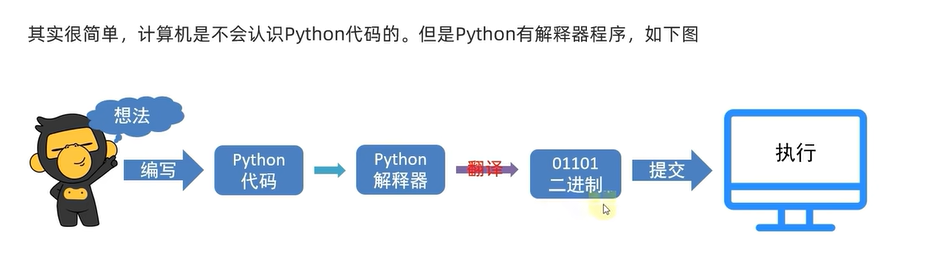
因为计算机只能读懂0和1,配置环境,本质上就是安装python解释器程序
python解释器:计算机程序,用来翻译python代码,并提交给计算机执行。
解译器功能:1.翻译代码 2.提交给计算机运行
python解译器的位置:
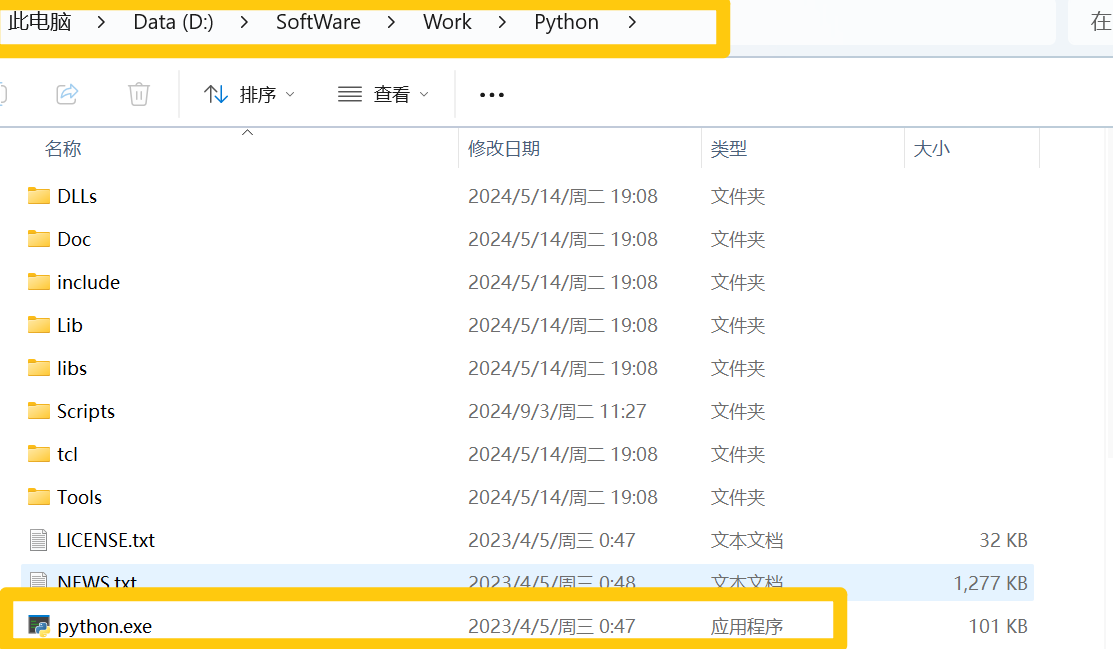
.py文件是什么?python语言的代码文件,里面记录了python的代码。
python开发环境
python开发环境
(也就是在哪写)

下载
www.jetbrains.com
community社区版
PyCharm文件管理
pycharm是以工程做基本的管理单位的

venv:虚拟环境
base conda:人工智能相关的包
custom envrionment 自定义环境
(为什么在.venv界面下,新建文件会出现一个外部库?)
鼠标滚轮改变字号:
pycharm常用快捷键:

python基础语法
字面量
含义:在代码中,被写下来的固定的值
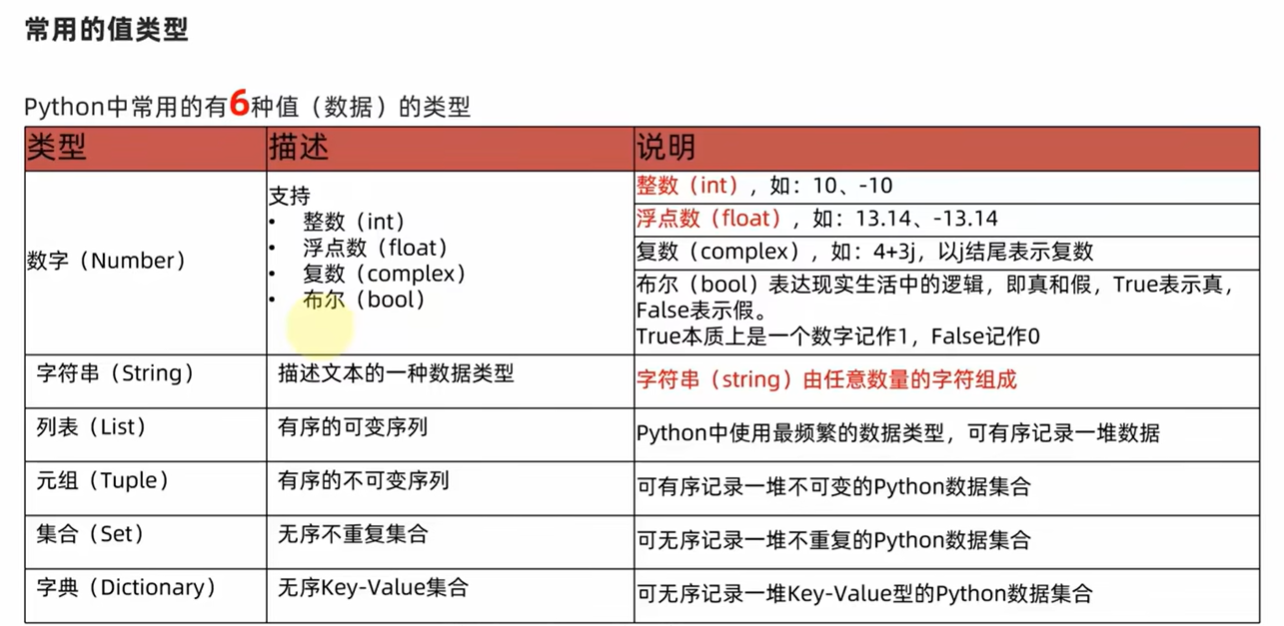
整数(int) 现实写法一致
浮点数(float) 现实写法一致
字符串(string)字符串需用双引号””包围
注释
含义:对代码解释说明的文字
分类:单行注释 #
多行注释:一对三个双引号 “”” 多行注释”””

变量
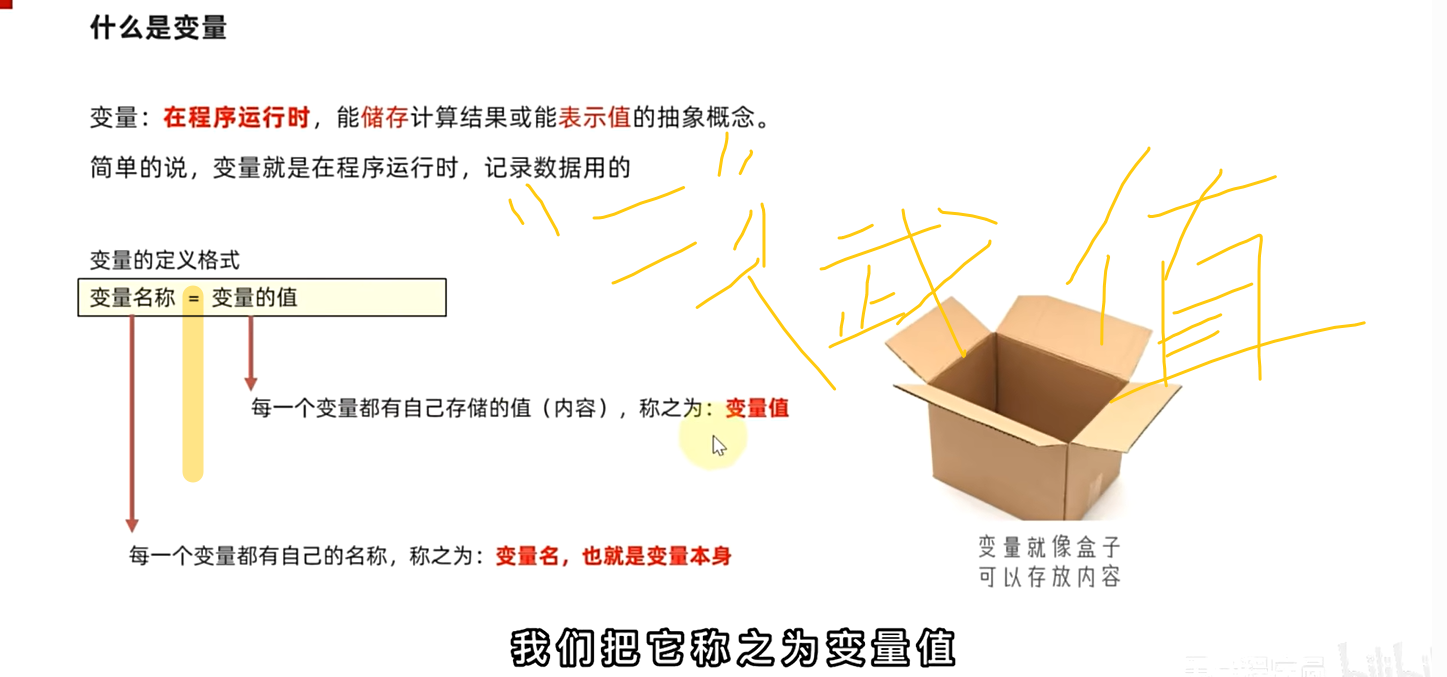
1.变量就是在程序运行时,记录数据用的
2.特征是变量的值可以改变
3.格式:变量名称=变量值
4.print可以输出多份内容
5.做减法(+、-、*、/)(变量记录数据,可以重复使用它,尤其是数据量极大时,能够减少工作量)
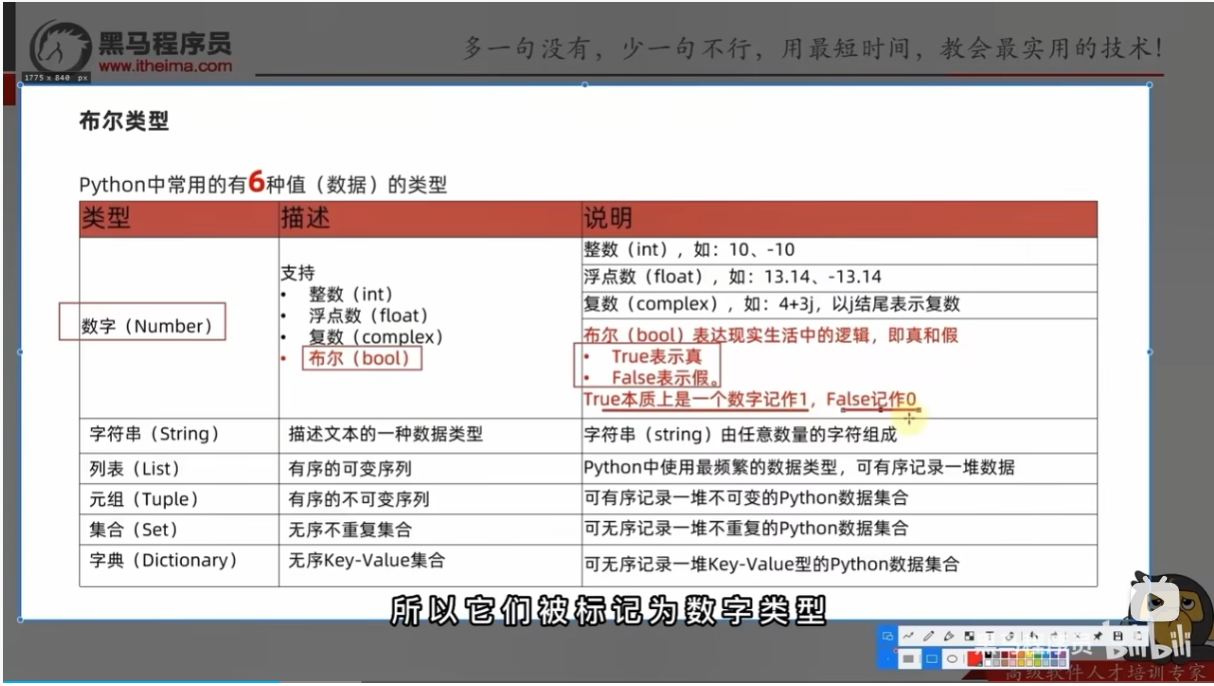
数据类型
三类数据类型:string (str)、int、float
type()语句得到数据的类型
1.print(type()),直接输出类型信息
2.用变量存储type()的结果(返回值)
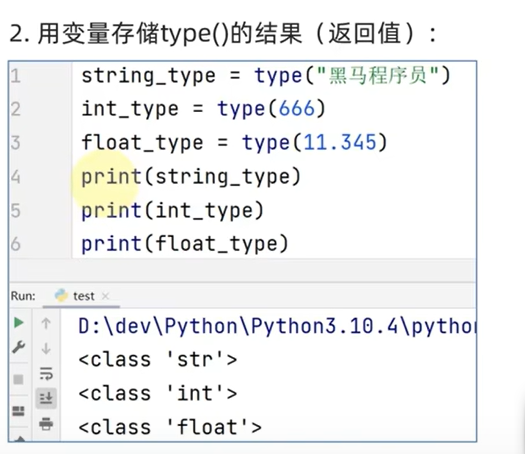
3.查看变量中存储的数据类型

数据类型转换
# 将数字类型转换成字符串
num_str = str(666)
print(type(num_str), num_str)
float_str = str(13.14)
print(type(float_str), float_str)
# 将字符串转换成数字
num1 = int("11")
print(type(num1), num1)
num2 = float("11.345")
print(type(num2), num2)
# 错误示例,想要将字符串转换成数字,必须要求字符串内的内容都是数字
# num3 = int("黑马程序员")
# print(type(num3), num3)
# 万物皆可转字符串,只要加上双引号就可以,但是字符串不可以转数字
# 整数转浮点数
float_num = float(11)
print(type(float_num), float_num)
# 浮点数转整数
int_num =int (11.234)
print(type(int_num), int_num)
标识符
在编程的时候所使用的一系列名字,用于给变量、类、方法命名
1.内容限定(英文、中文<不推荐>、数字<不可以用在开头>、下划线_)
2.大小写敏感
3.不可使用关键字

变量的命名规范:
1.见名知意
2.下划线命名法
3.英文字母全小写
运算符
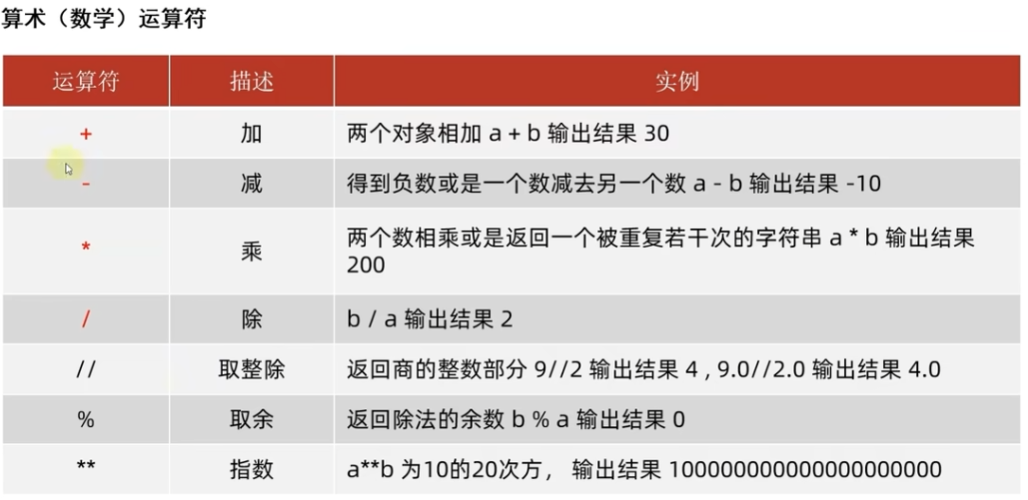
赋值运算符
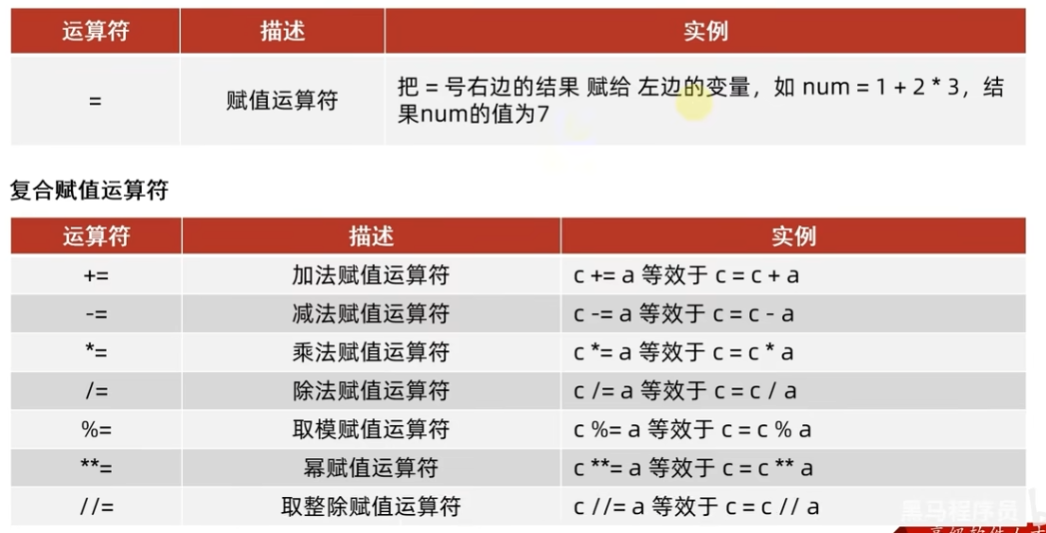
例子:
"""
演示Python中各类运算符
"""
# 算术运算符
print("1+1=" , 1+1)
print("2-1=" , 2-1)
print("3*3=" , 3*3)
print("9/3=" , 9/3)
# 整除
print("9//2=" , 9//2)
# 取余
print("13%4=" , 13%4)
# 指数
print("2**4=" , 2**4)
# 赋值运算符
num = 1*2+4
# 复合赋值运算符
# += 将右侧的值加到左侧的变量上,然后将结果重新赋值给左侧的变量
num = 1
num +=1 # num = num + 1
print("num += 1:",num)
# -= 将右侧的值减到左侧的变量上,然后将结果重新赋值给左侧的变量
num -=1 # num = num - 1
print("num -= 1:",num)
# *=
num *= 4 # num = num * 4
print("num *= 4:",num)
num /= 2 # num = num / 2
print("num /= 2:",num)
num = 3
num %= 2
print("num %= 2:",num)
num **= 2
print("num **2:",num)
num = 9
num //= 2 # 将num整除2 结果赋值给num,也就是num//2=4
print("num //2:",num)
字符串拓展
字符串的三种定义方式

如果想要定义字符串本身,是包含:单引号、双引号自身呢?如何写?
单引号定义法,可以内含双引号
双引号定义法。可以内含单引号
可以使用转移字符(左斜杠)来将引号解除效用,变成普通字符串)
-
字符串拼接
-
字符串格式化
-
格式化精度控制
-
字符串格式化方式2
-
对表达式进行格式化
字符串拼接


字符串格式化
字符串格式化

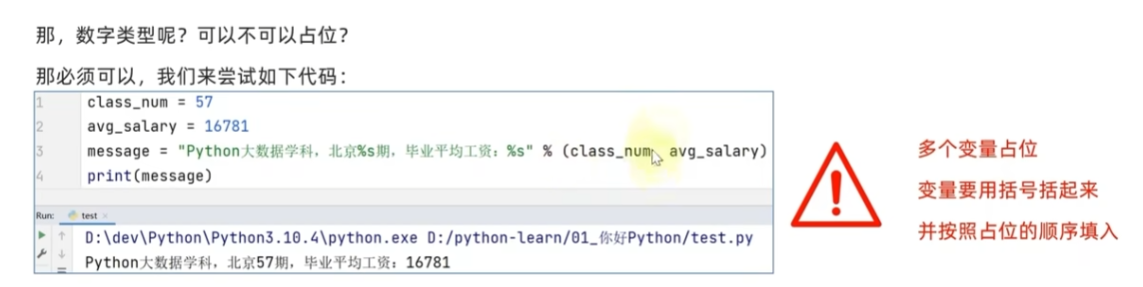
数字类型占位
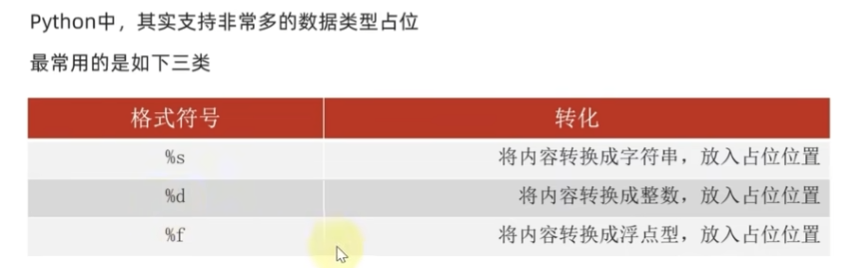
格式化的精度控制

字符串格式化的方式2
字符串格式化-快速写法
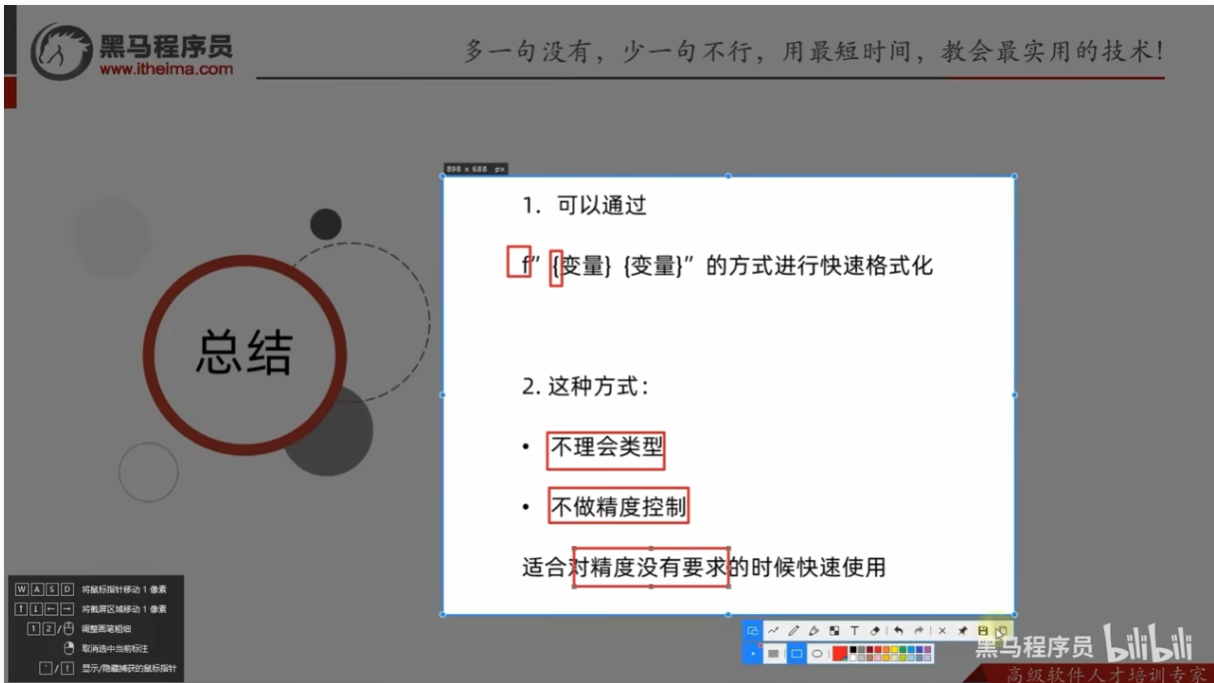
对表达式进行格式化
数据输入(input语句)

总结

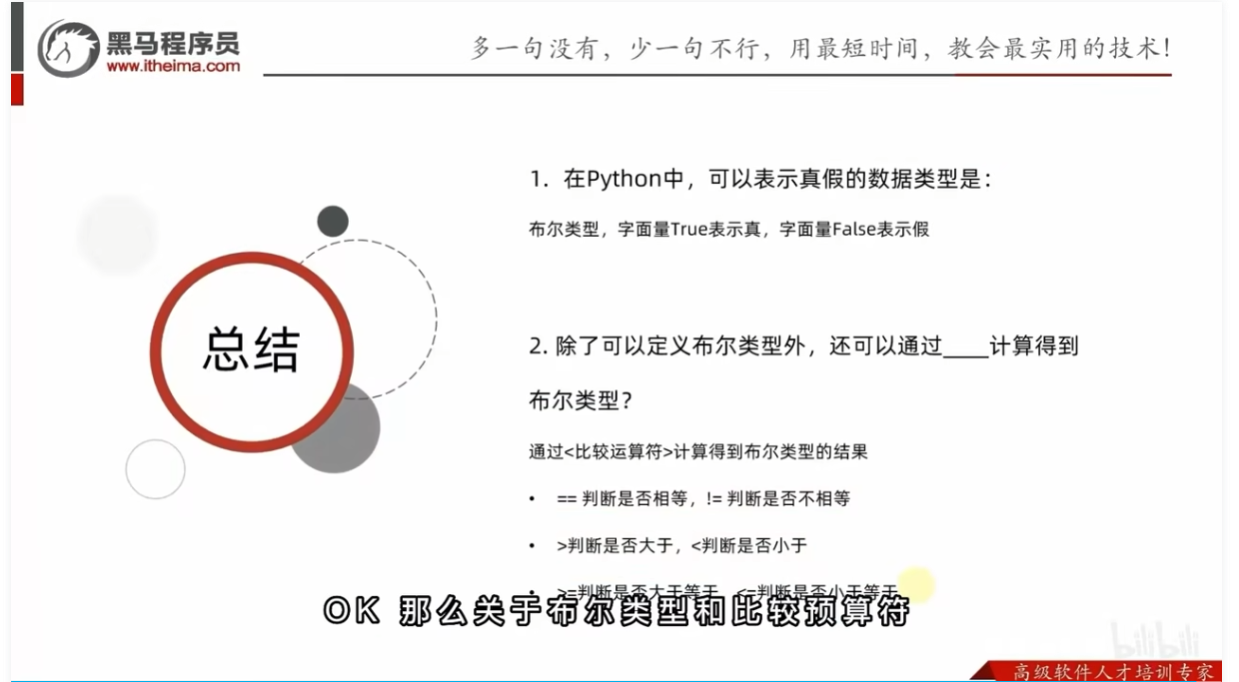
Python的判断语句
布尔类型和比较运算符
比较运算符

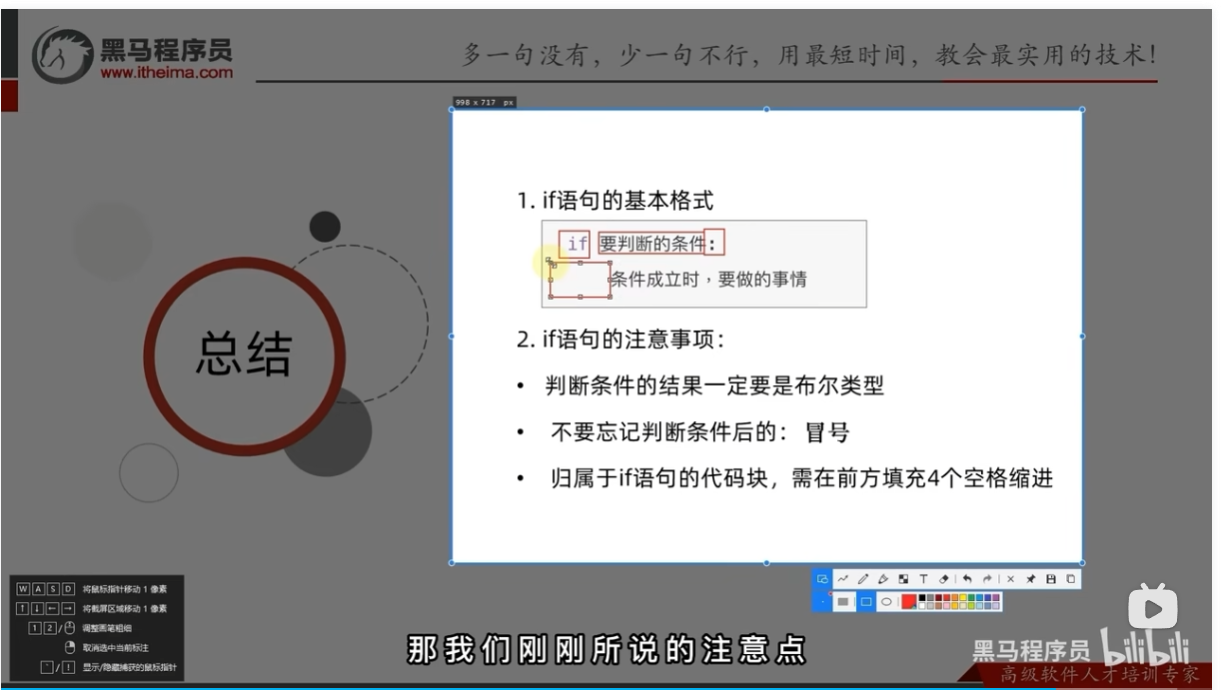
if语句的基本格式
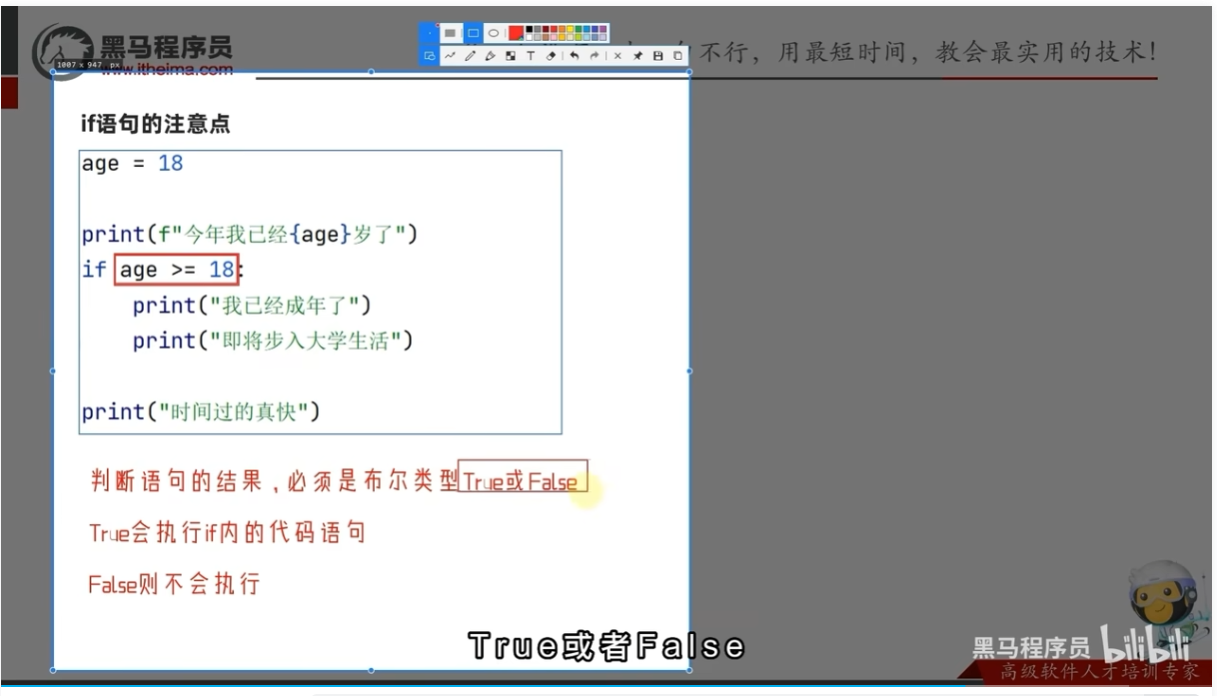
if的注意点
总结
案例
"""
成年人判断
"""
# 通过input语句,获取键盘输入,为变量age赋值(注意转换数字类型)。因为input所有输出内容都是字符串
age = int(input("请输入你的年龄:"))
# 通过if判断是否是成年人,满足条件则输出提示信息
if age >= 18:
print("欢迎来到黑马儿童游乐场,儿童免费,成人收费")
print("您已成年,游玩需要补票10元")
print("祝您游玩愉快")
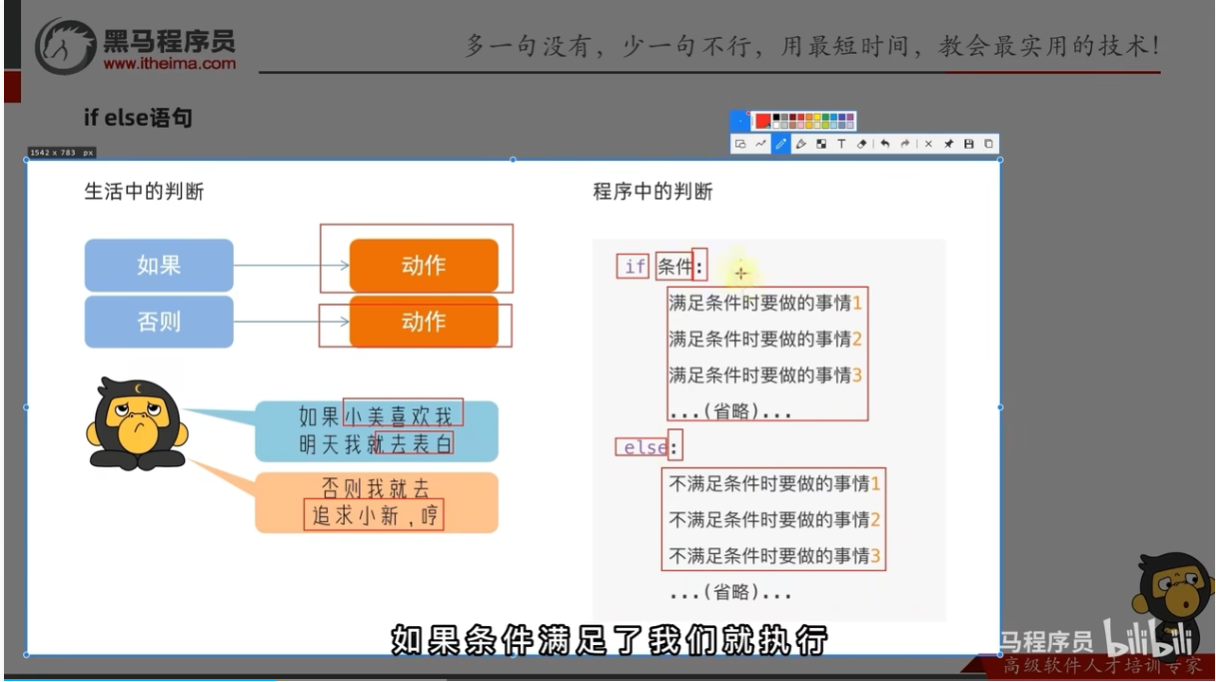
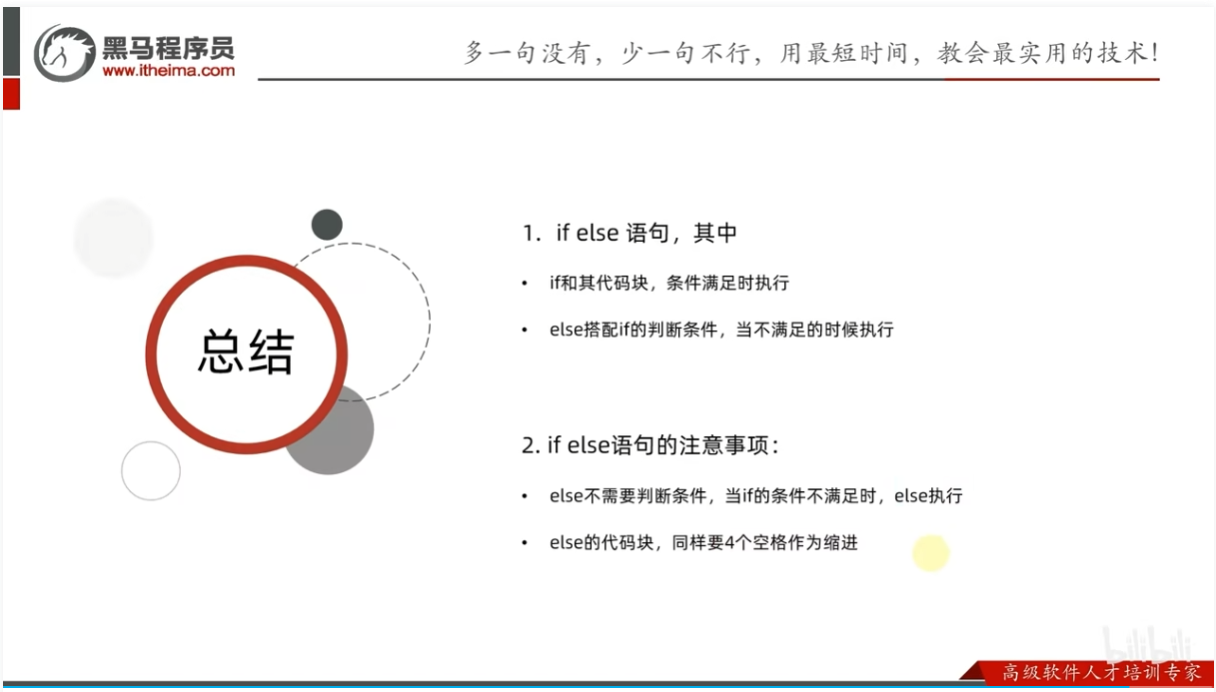
if else组合判断语句
总结
案例
"""
我要买票吗
"""
print("欢迎来到黑马动物园")
height = int(input("请输入你的身高(cm):"))
if height > 120:
print("您的身高超出120cm,游玩需要购票,10元")
else:
print("您的身高未超过120cm,可以免费游玩")
print("祝您游玩愉快")
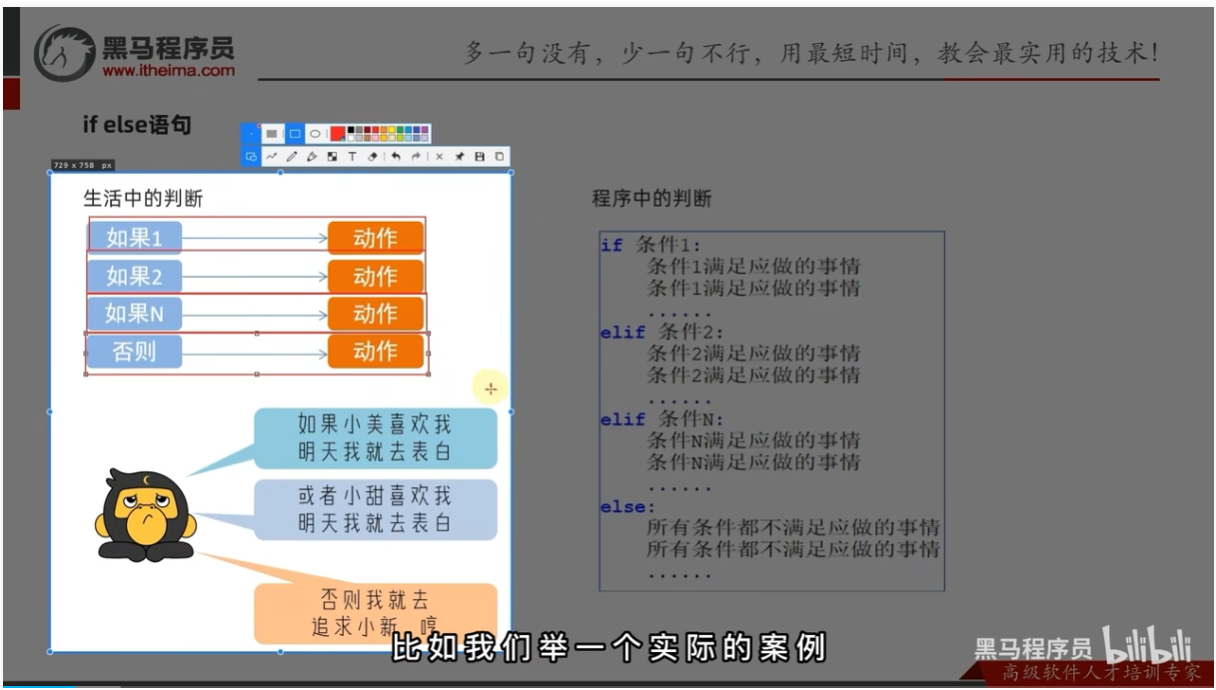
if _elif_else组合使用的语法
多个条件
课程讲解案例
"""
组合用法
"""
height = int(input("请输入你的身高(cm):"))
vip_level = int(input("请输入你的VIP等级(1-5):"))
day = int(input("请告诉我今天是几号:"))
# 通过if判断,可以使用多条件判断的语法
if height < 120:
print("身高小于120cm,可以免费")
elif vip_level >3:
print("vip级别大于3,可以免费")
elif day ==1:
print("今天是1号免费日,可以免费")
else:
print("不好意思,条件都不满足,需要买票10元")
# 节省代码量
print("欢迎来到黑马动物园")
if int(input("请输入你的身高(cm):")) < 120:
print("身高小于120cm,可以免费")
elif int(input("请输入你的VIP等级(1-5):")) > 3:
print("vip级别大于3,可以免费")
elif int(input("请告诉我今天是几号:")) == 1:
print("今天是1号免费日,可以免费")
else:
print("不好意思,条件都不满足,需要买票10元")

练习案例
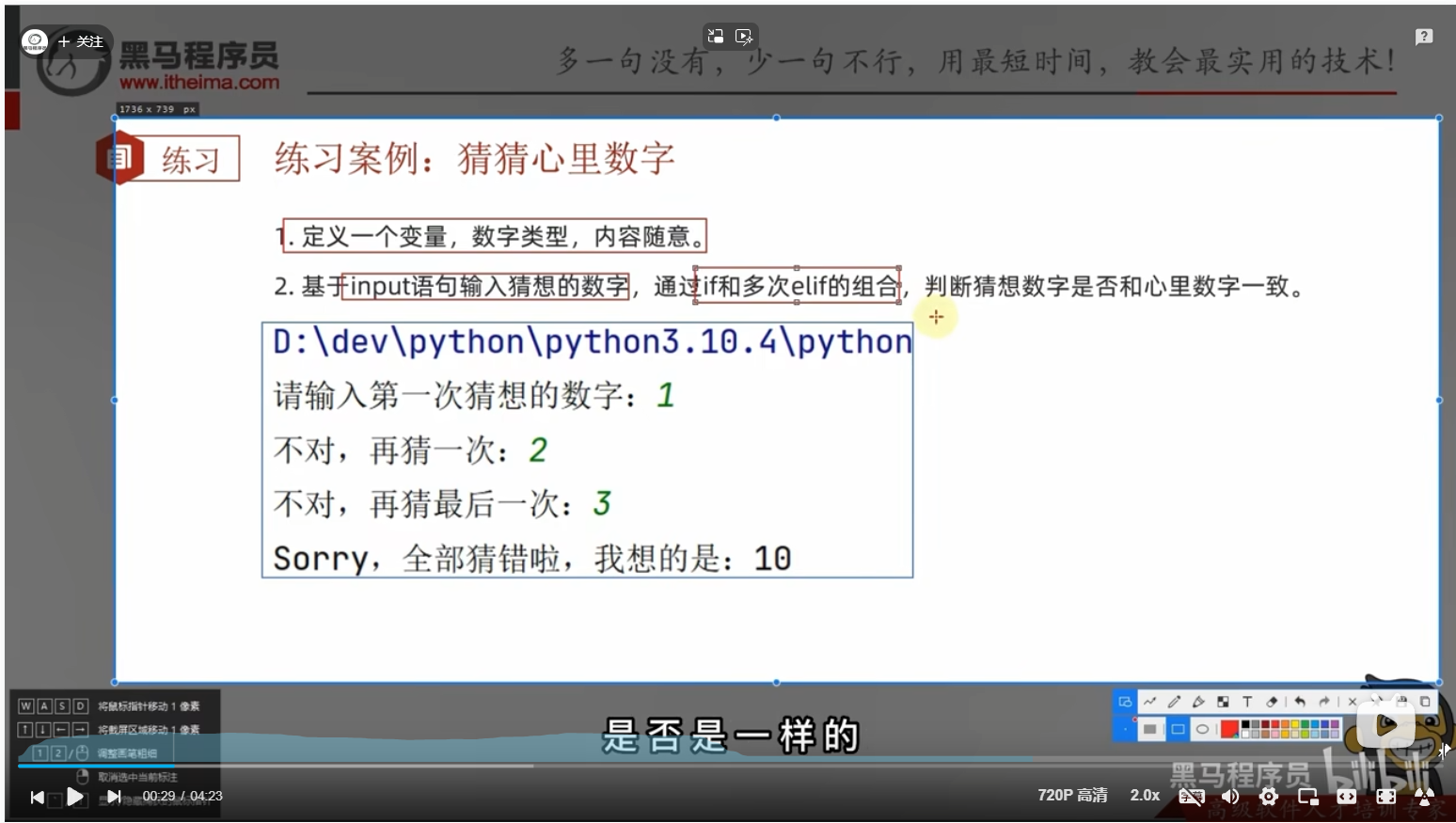
"""
猜猜心里数字
"""
# 定义一个变量
num = 6
if (int(input("请输入第一个猜想的数字:"))) == num:
print("恭喜第一次猜对了")
elif (int(input("猜错了,再猜一次:"))) == num:
print("猜对了")
elif (int(input("猜错了,再猜一次:"))) == num:
print("恭喜,最后一次猜对了")
else:
print("sorry,猜错了")
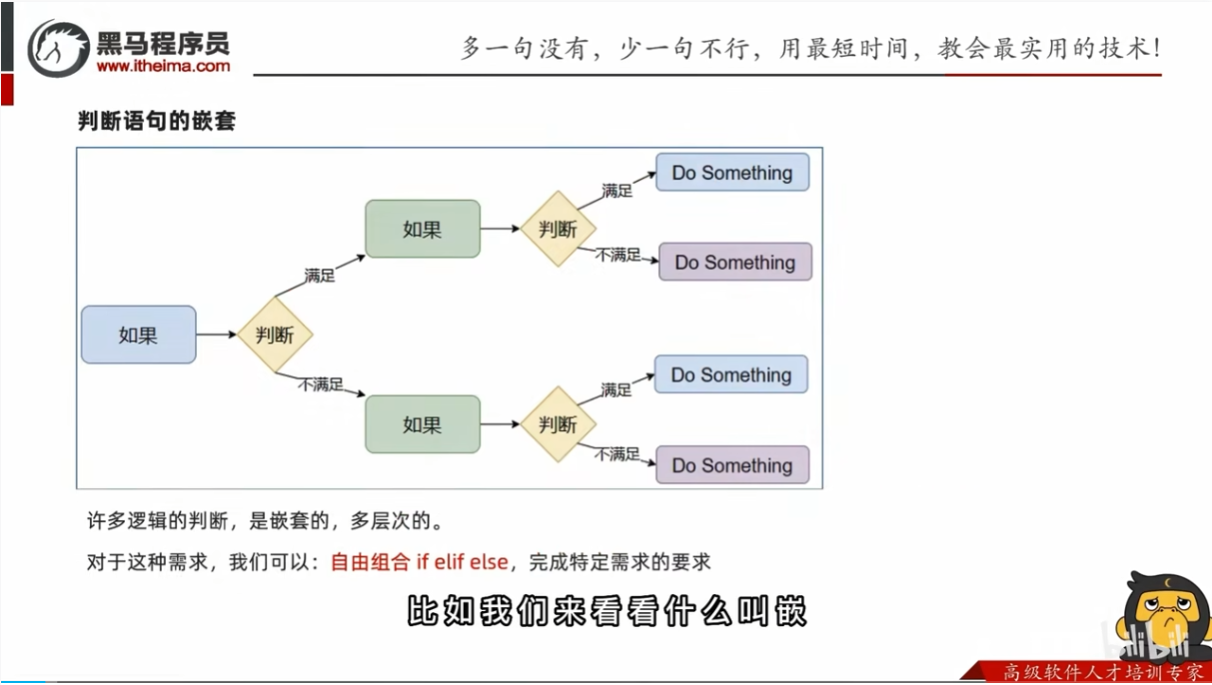
判断语句的嵌套
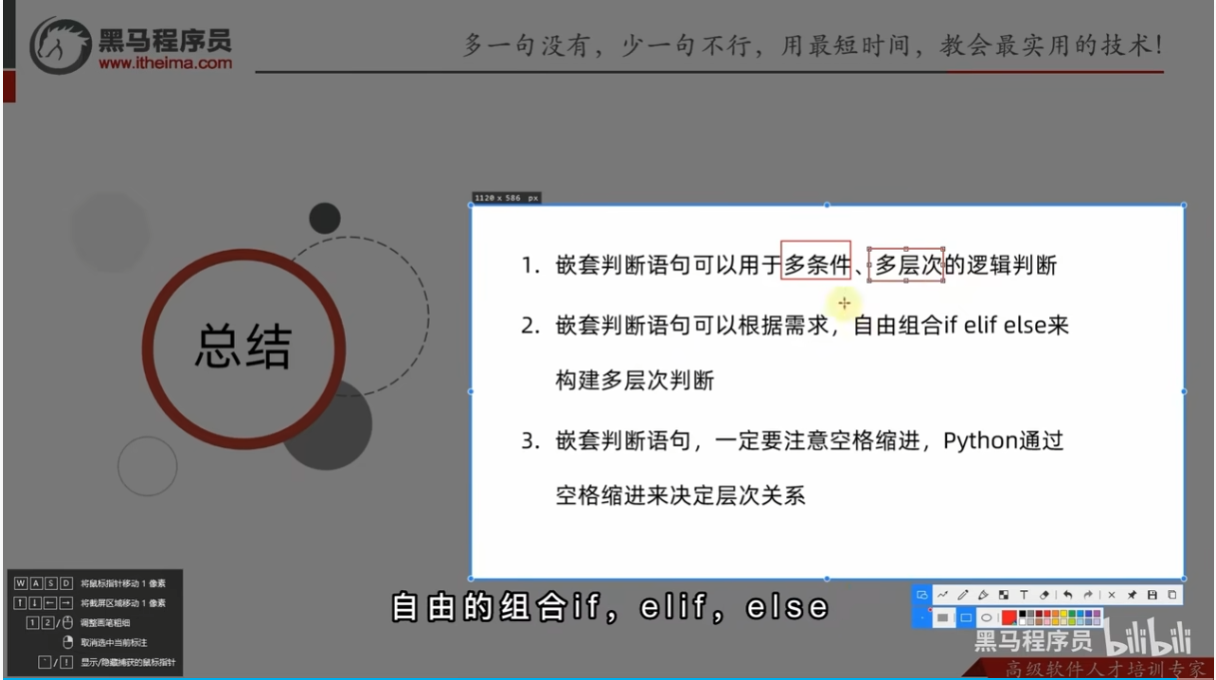
自由组合的形式,分不同层次的形式就是判断语句的嵌套了
总结
判断语句的综合案例
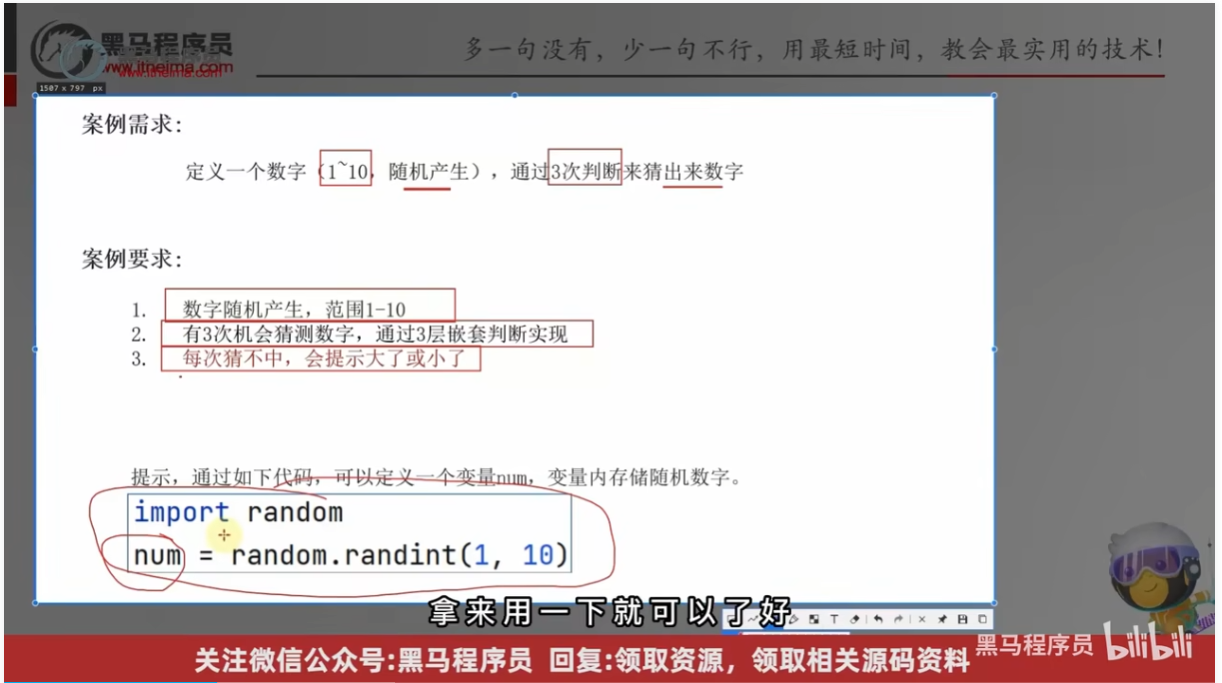
"""
终极猜数字
"""
# 1.构建一个随机的数字变量
import random
num = random.randint(1,10)
guess_num = int(input("输入你要猜测的数字:"))
# 2.通过if判断语句进行数字的猜测
if guess_num == num:
print("恭喜,第一次就猜对了")
else:
if guess_num > num:
print("你猜测的数字大了")
if guess_num < num:
print("你猜测的数字小了")
guess_num = int(input("输入你要猜测的数字:"))
if guess_num == num:
print("恭喜,第二次猜对了")
else:
if guess_num > num:
print("你猜测的数字大了")
if guess_num < num:
print("你猜测的数字小了")
guess_num = int(input("输入你要猜测的数字:"))
if guess_num == num:
print("恭喜你,第三次猜对了")
else:
print("你都猜错了" )
Python循环语句

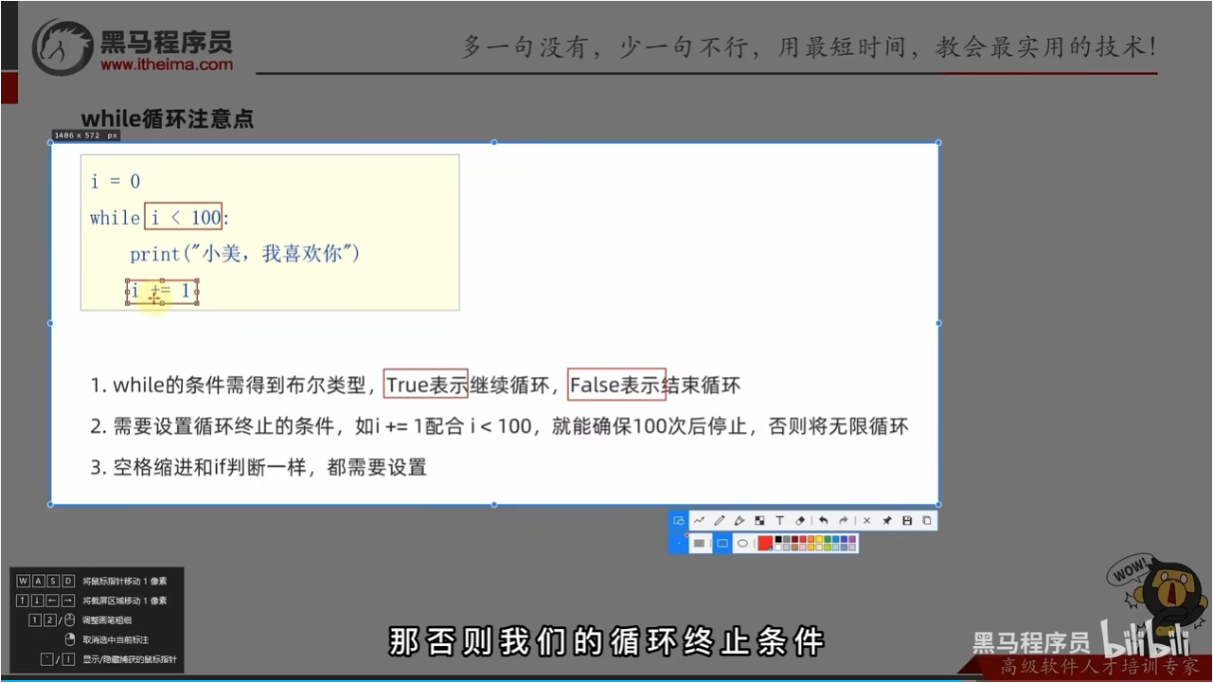
while循环的基础语法
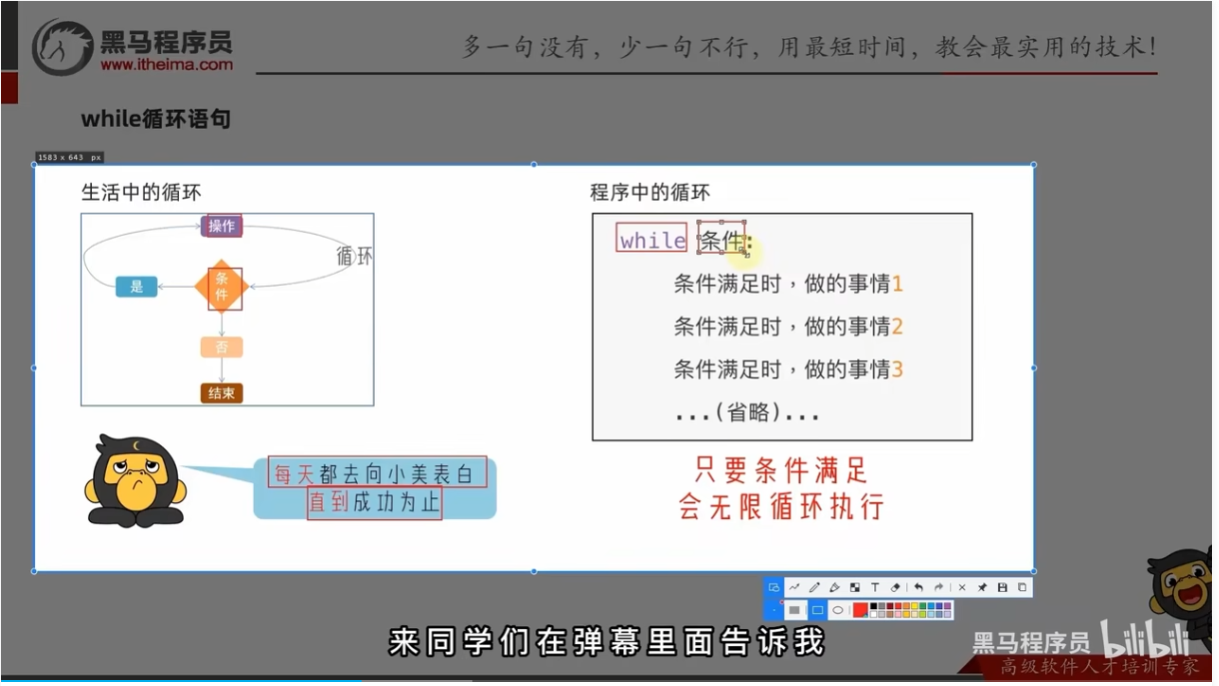
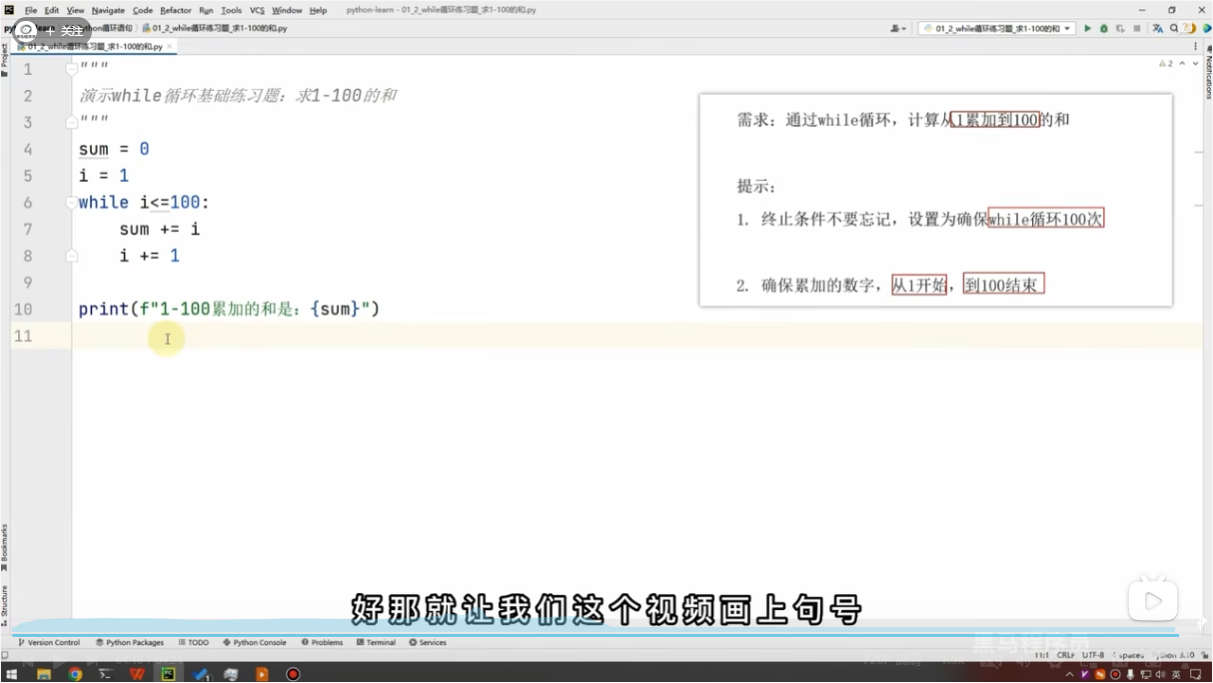
练习案例(没审好题,以为是循环列出1到100的值,但其实是求和)
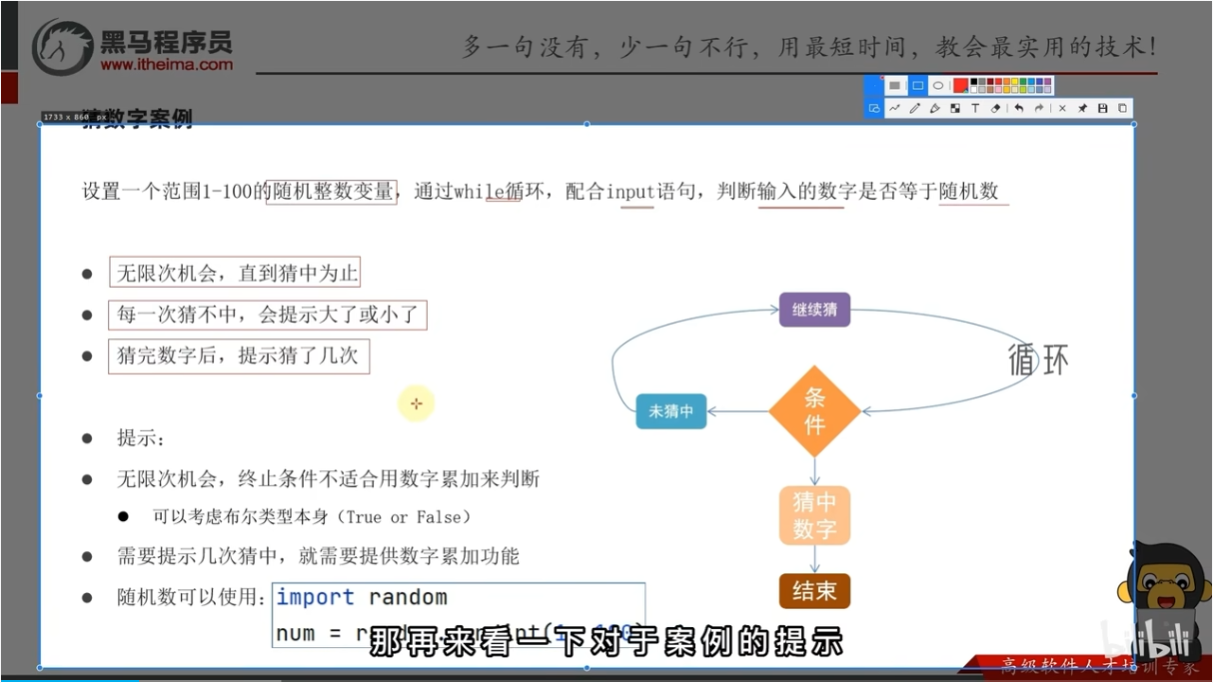
案例
"""
猜数字
"""
# 获取范围在1-100的随机数字
import random
num = random.randint(1,100)
# 定义一个变量,记录总共猜测了多少次
count = 0
# 通过一个布尔类型的变量,做循环是否继续的标记
flag = True
while flag:
guess_num=int(input("请输入你猜测的数字"))
count +=1
if guess_num == num:
print("你猜对了")
flag = False
else:
if guess_num > num:
print("你猜的大了")
else:
print("你猜的小了")
print(f"你总共猜测了{count}次")
while循环的嵌套使用
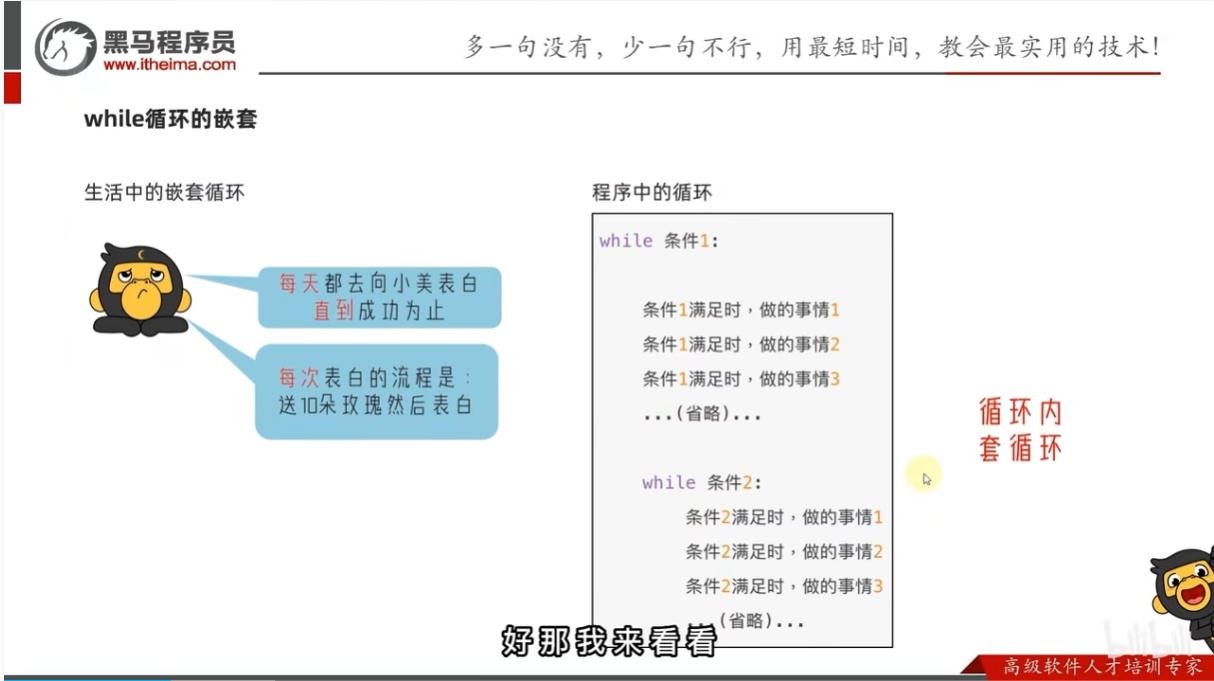
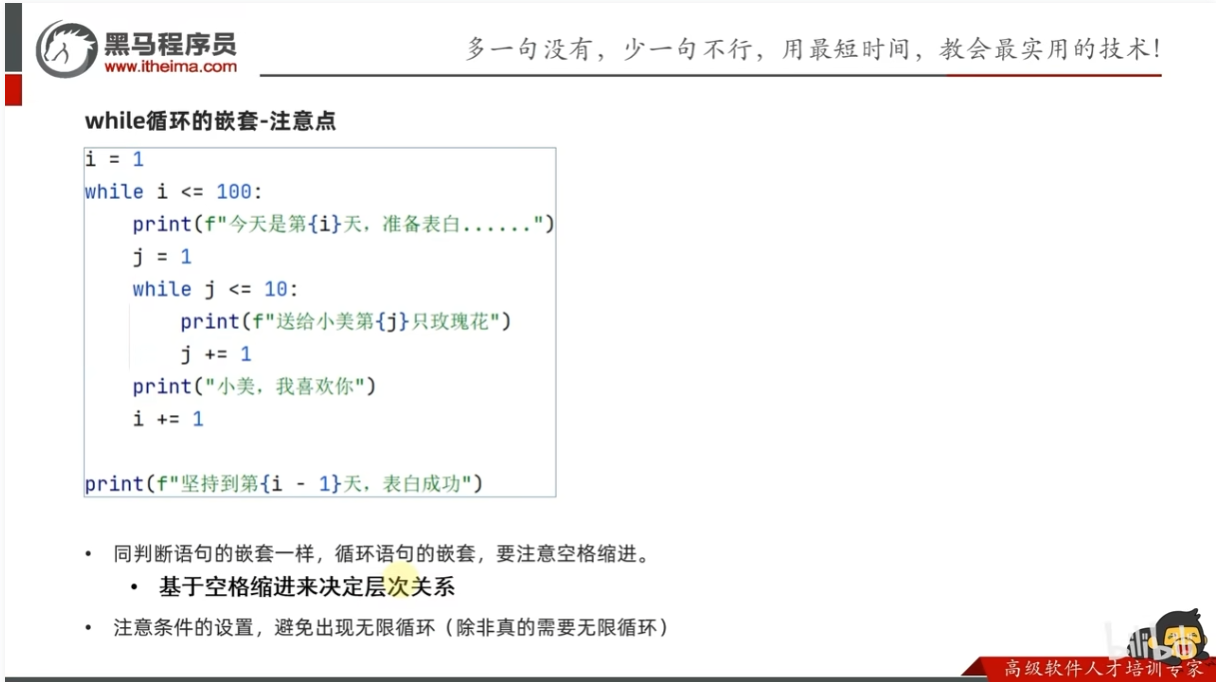
注意点
while循环案例—九九乘法表
print输出不换行

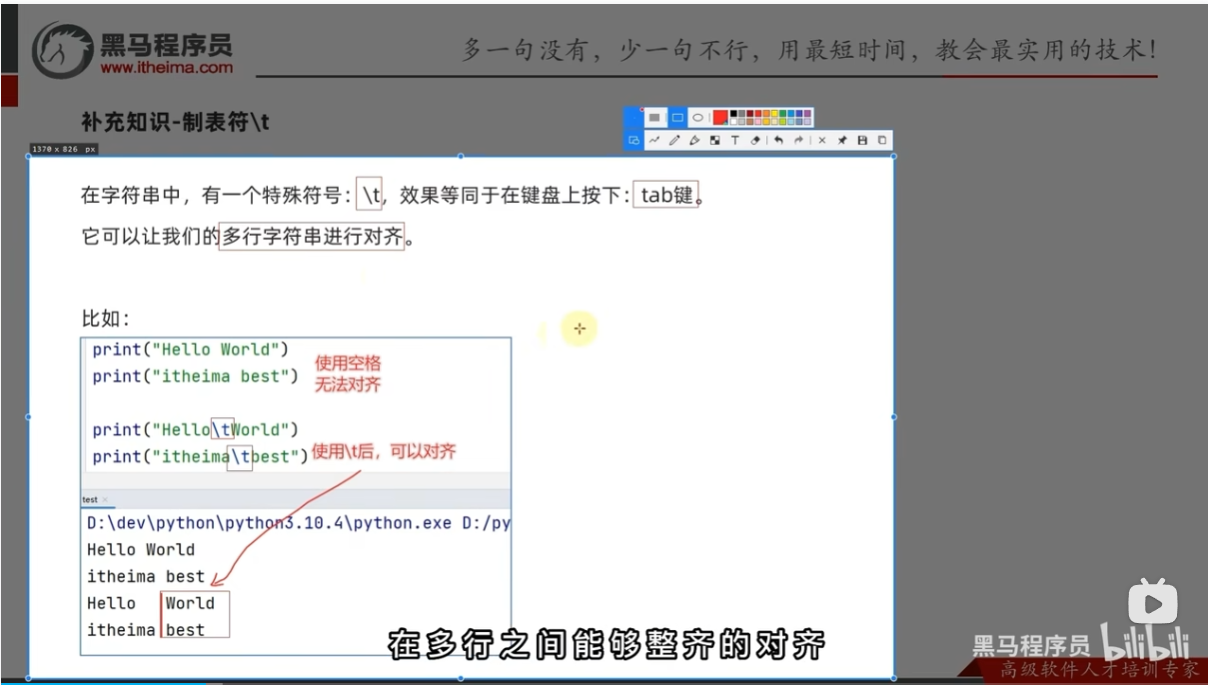
制表符
九九乘法表
# print("hello",end='')
# print("world",end='')
# print("hello\tworld")
# print("itheima\best")
"""
九九乘法口诀
"""
# 定义外层循环的控制变量
i = 1
while i <= 9:
# 定义内层循环的控制变量
j = 1
while j <= i:
print(f"{j} * {i} = {j * i}\t",end='')
j += 1
i += 1
print() # print空内容,就是输出一个换行
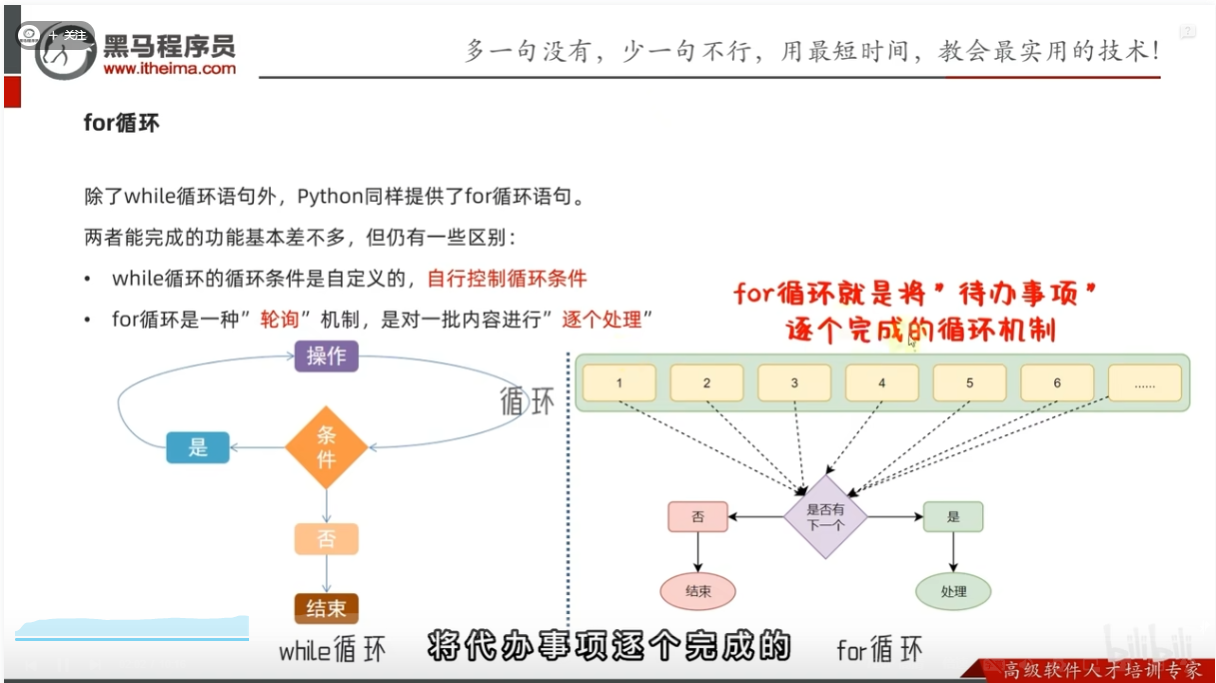
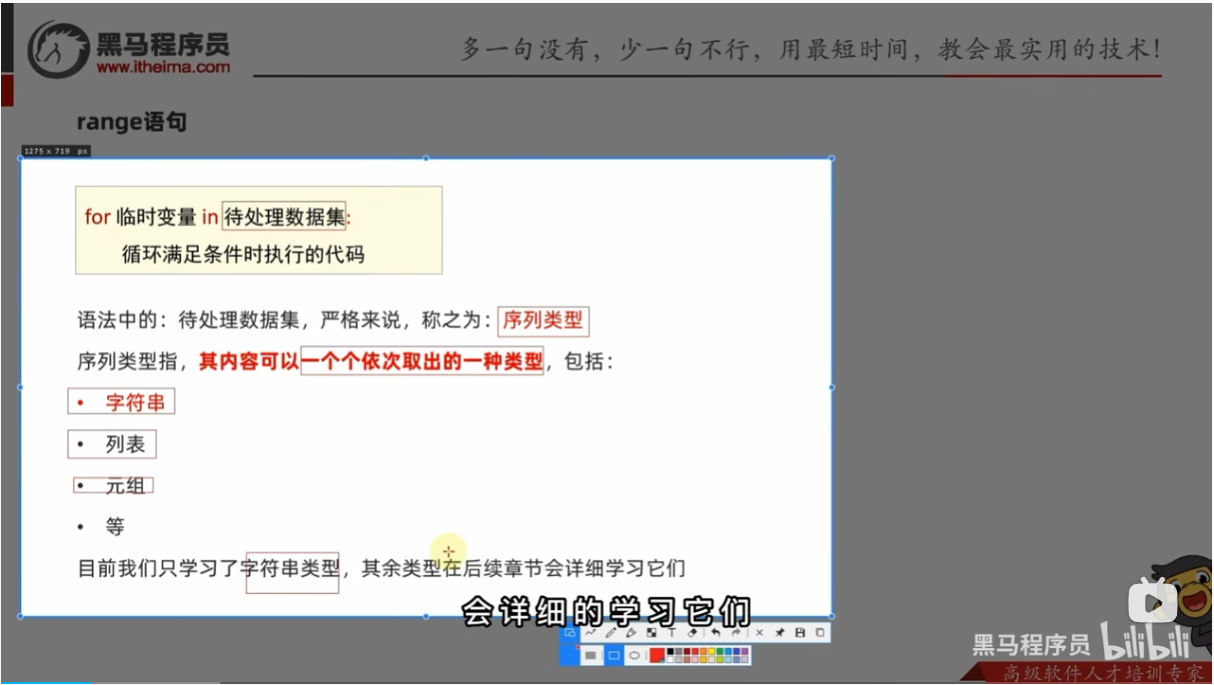
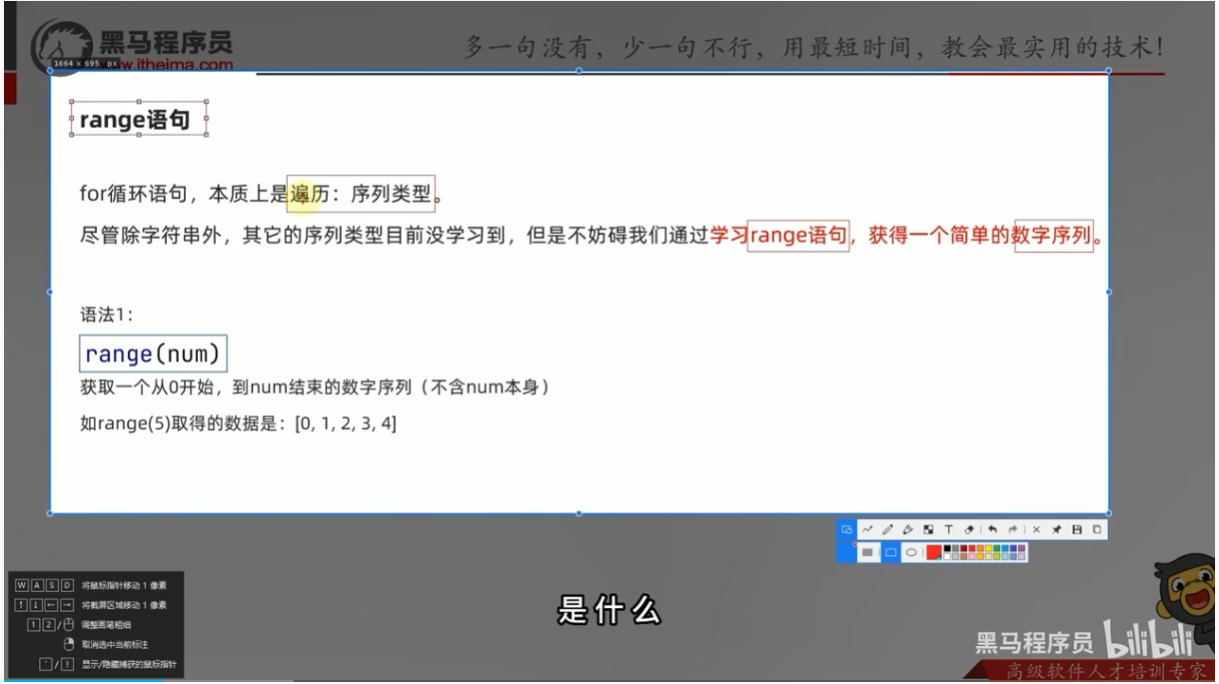
for循环的基础语法
for循环:对待办事项一个一个处理
总结
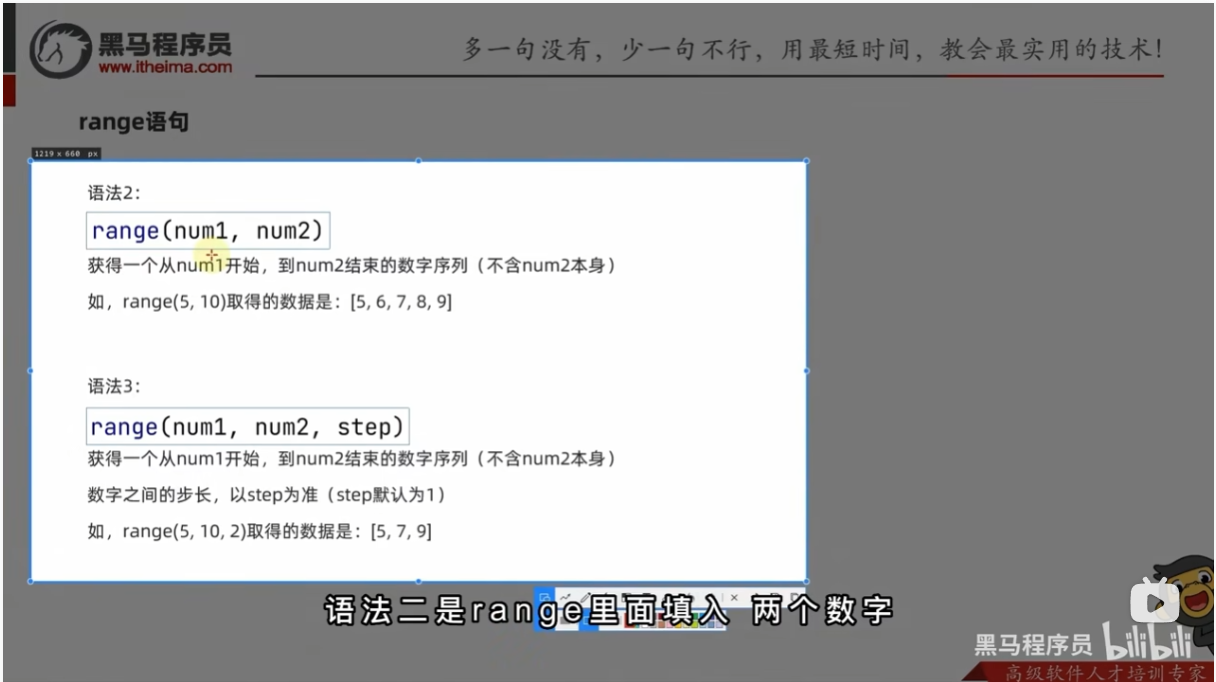
range 语句
range语句
总结
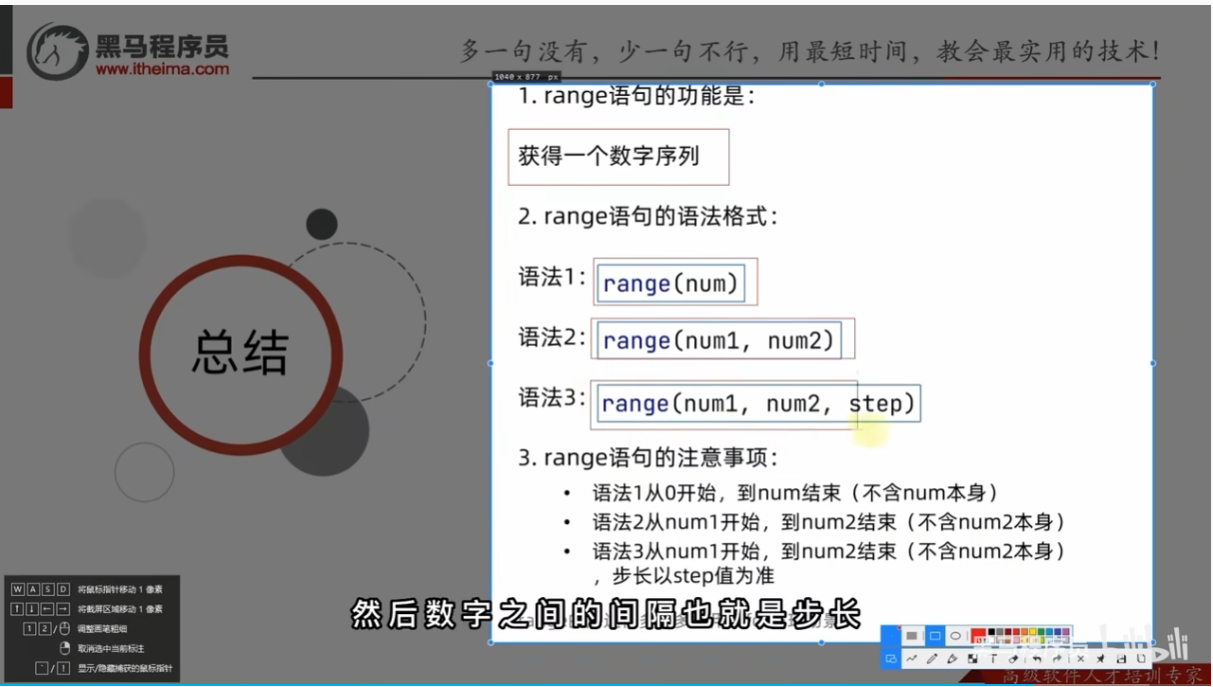
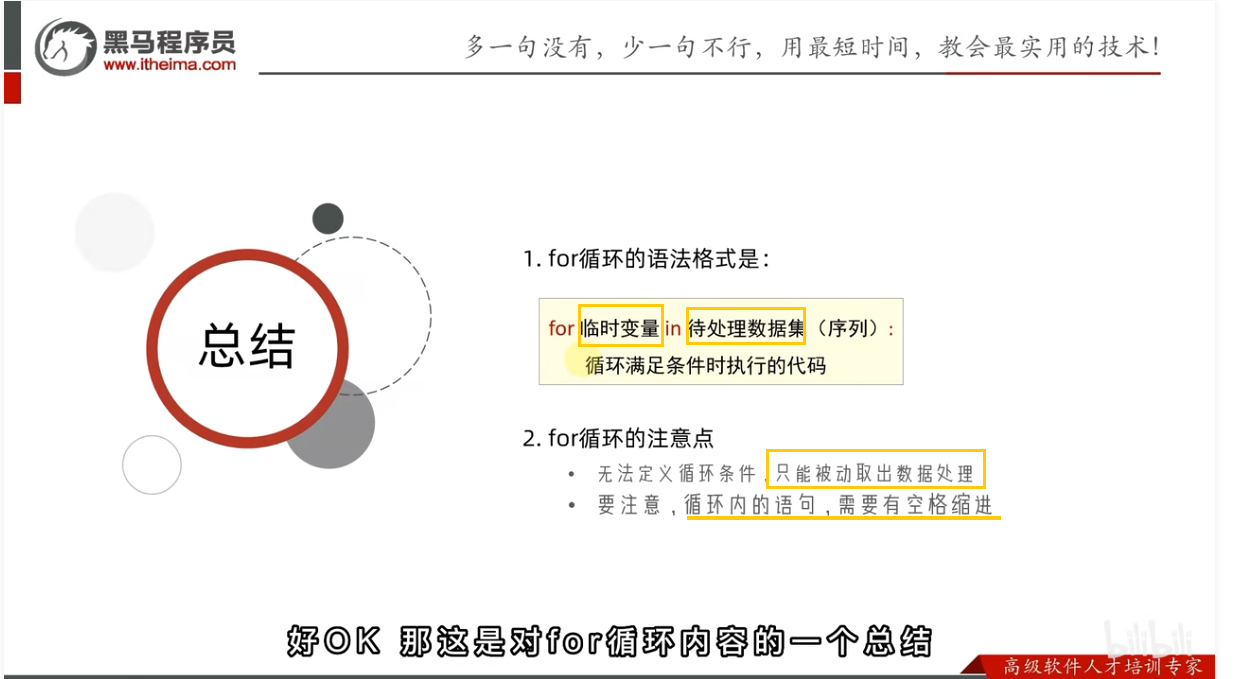
for循环临时变量作用域
总结
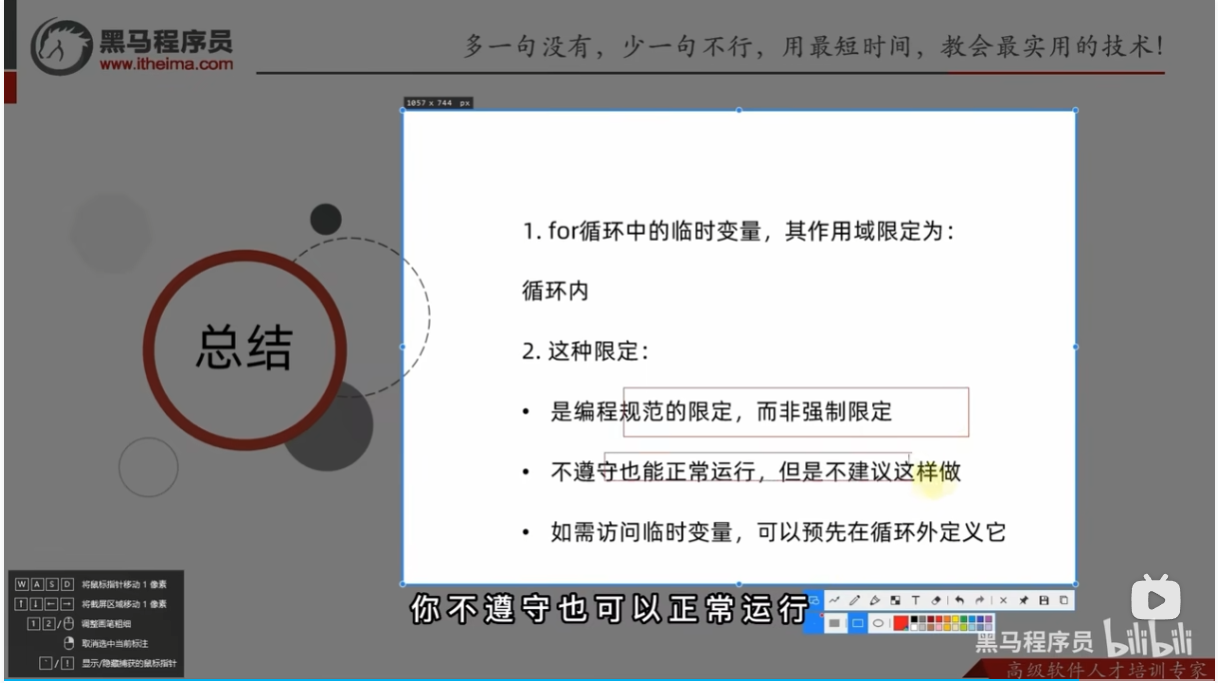
for循环的嵌套使用
"""
嵌套应用for循环
"""
# 坚持表白100天,每天都送10朵花
i = 1
for i in range(1,101):
print(f"今天是跟小美表白的第{i}天,加油坚持")
# 内层循环
for j in range(1,11):
print(f"给小美送的第{j}朵玫瑰花")
print("小美,我喜欢你")
print(f"第{i}天,表白成功")
for循环打印九九乘法表
"""
for循环打印九九乘法表
"""
# 外层循环控制行数
for i in range(1,10):
# 定义内层循环控制变量,为什么要+1呢?因为range语句,是不包含右括号旁边的数值的,在这里也就是不包含i+1
for j in range(1,i+1):
print(f"{j}*{i} = {j*i}\t",end='')
# 外层循环可以通过print输出一个回车符
print()
continue和break

continue循环

break循环

两者都只在循环内使用

循环综合案例

# 某公司,账户余额有1W元,给20名员工发工资。
# 员工编号从1到20,从编号1开始,依次领取工资,每人可领取1000元领工资时,财务判断员工的绩效分(1-10)(随机生成),如果低于5,不发工资,换下一位
# 如果工资发完了,结束发工资。
# 定义账户余额变量
money = 10000
# for循环给员工发工资,随机生成绩效
for i in range(1,21):
import random
score = random.randint(1,10)
if score < 5:
print(f"员工{i}绩效分{score},不满足,不发工资,下一位")
# continue跳过发放
continue
# 要判断余额足不足
if money >= 1000:
money -= 1000
print(f"员工{i},满足条件发放工资1000,公司账户余额{money}")
else:
print(f"余额不足,当前余额:{money}元,不足以发放工资,不发了,下个月发")
break
python函数
函数的初体验
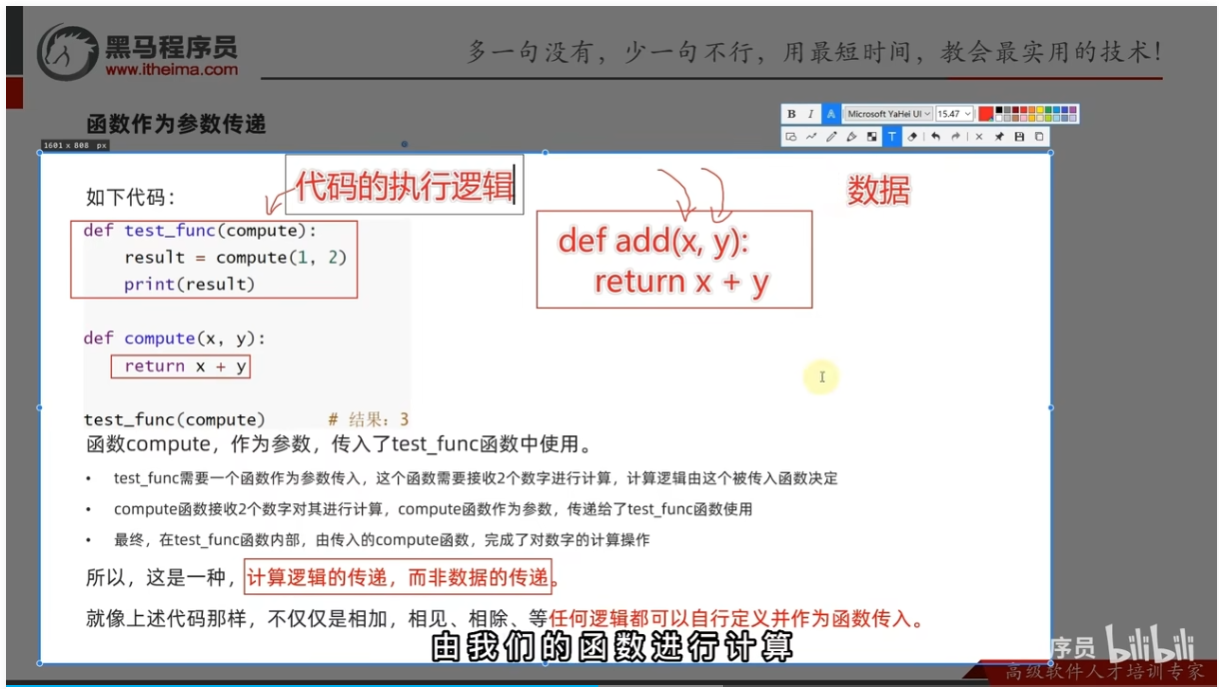
函数:可以得到一个针对特定需求、可供重复利用的代码块,提高程序复用性,减少重复性代码,提高开发效率。
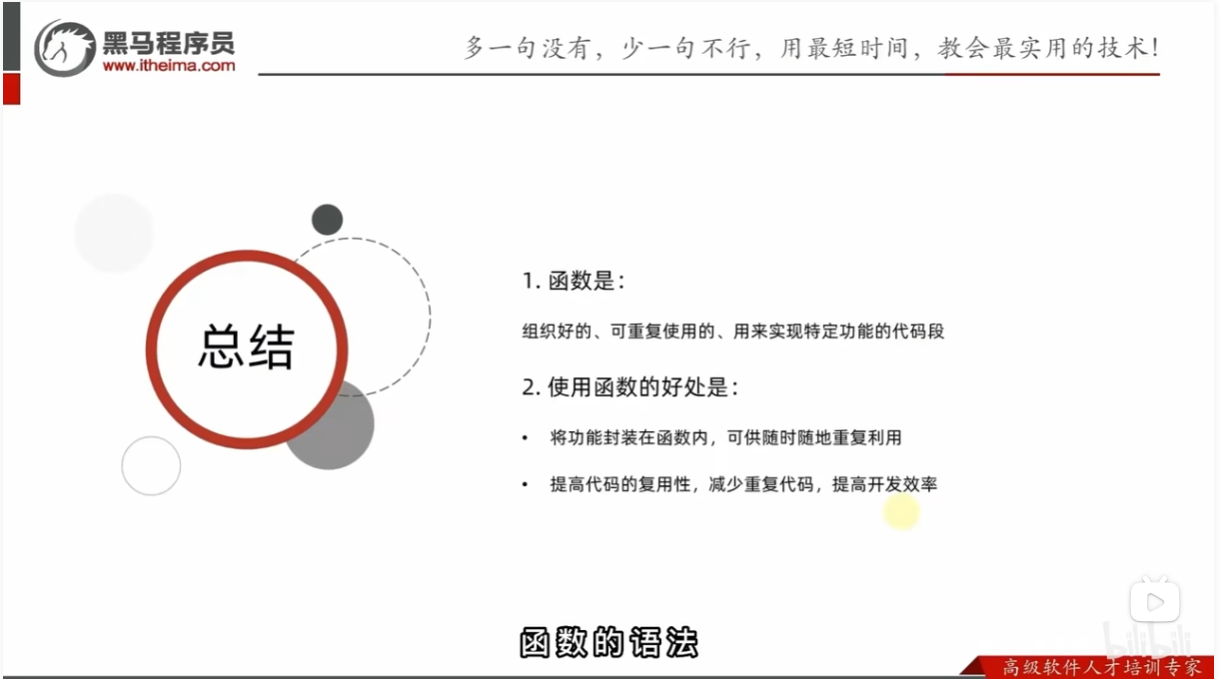
函数的基础定义语法
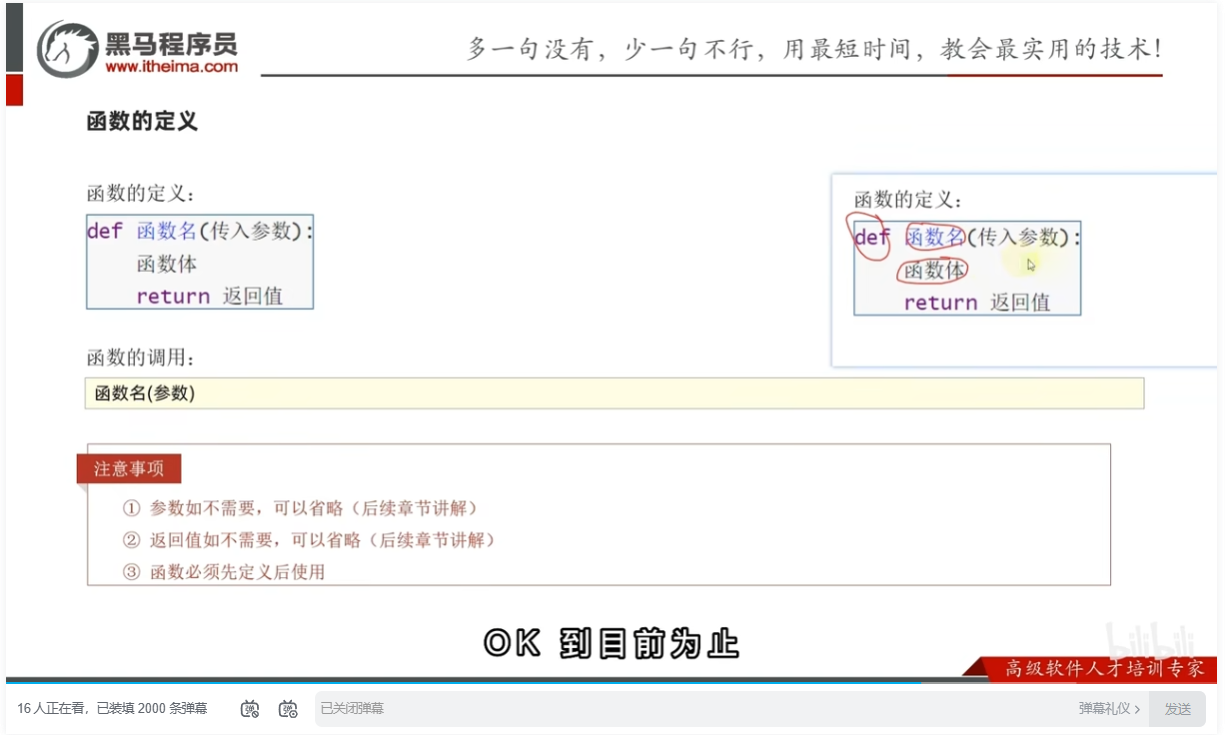
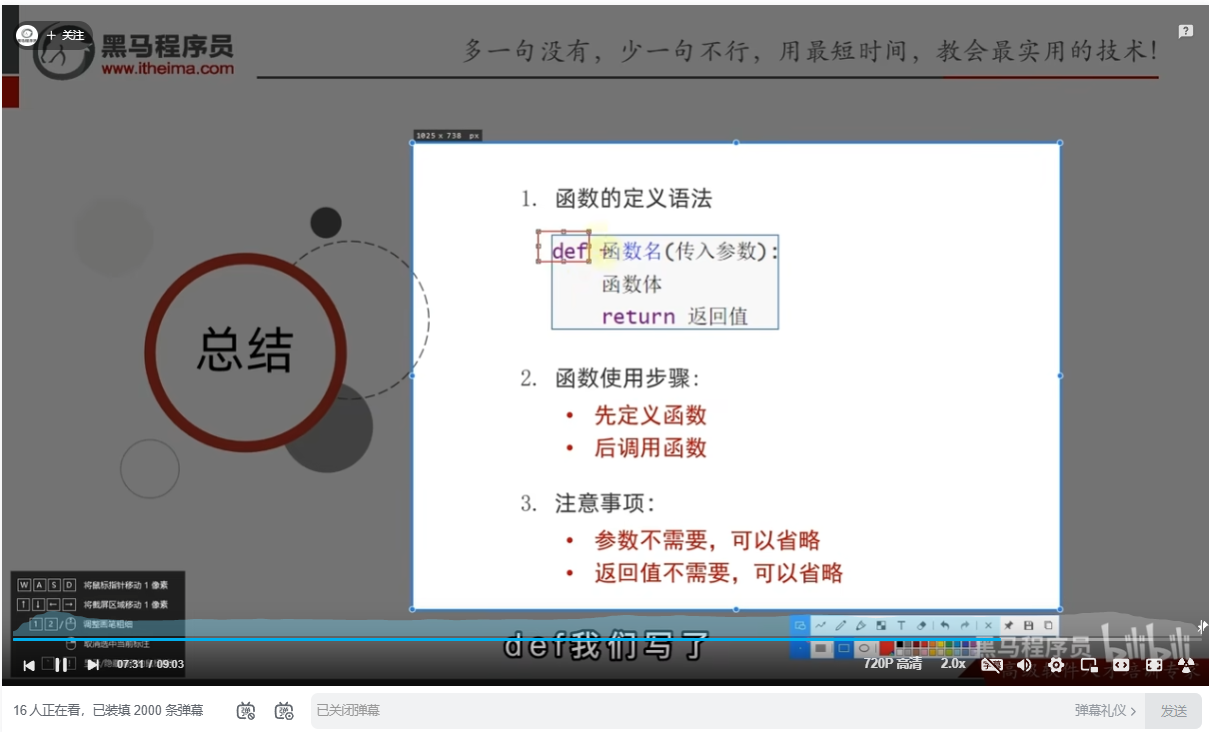
函数的传入参数
传入参数的作用

语法解析
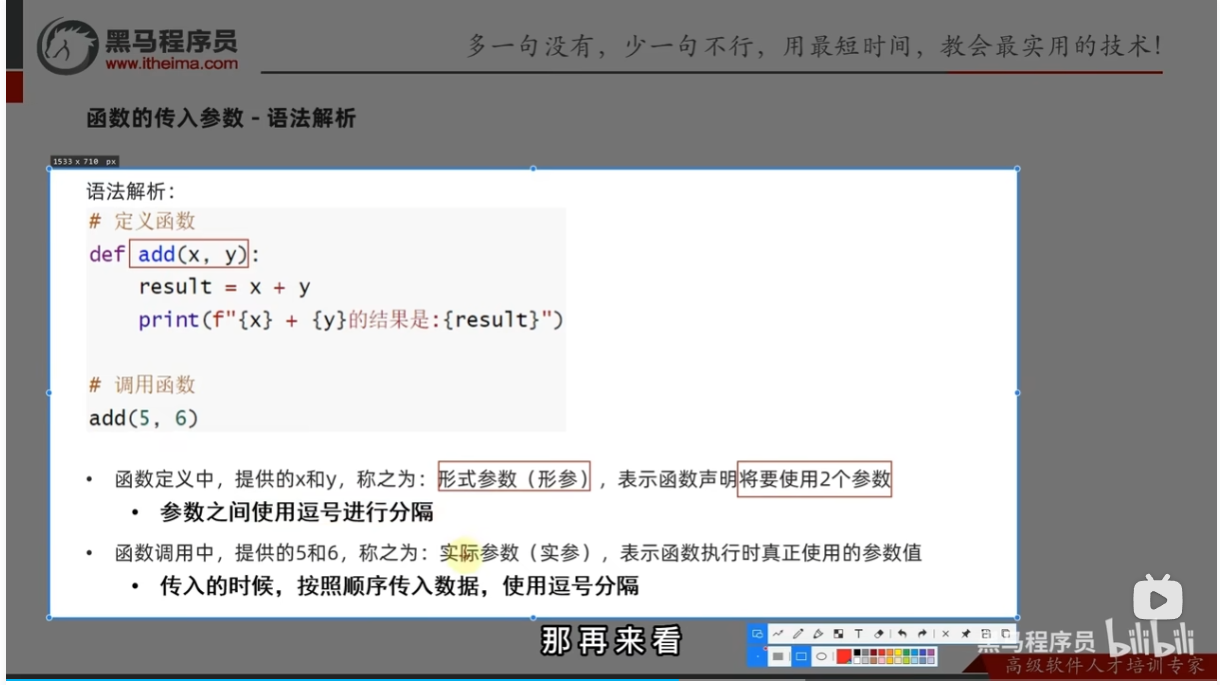
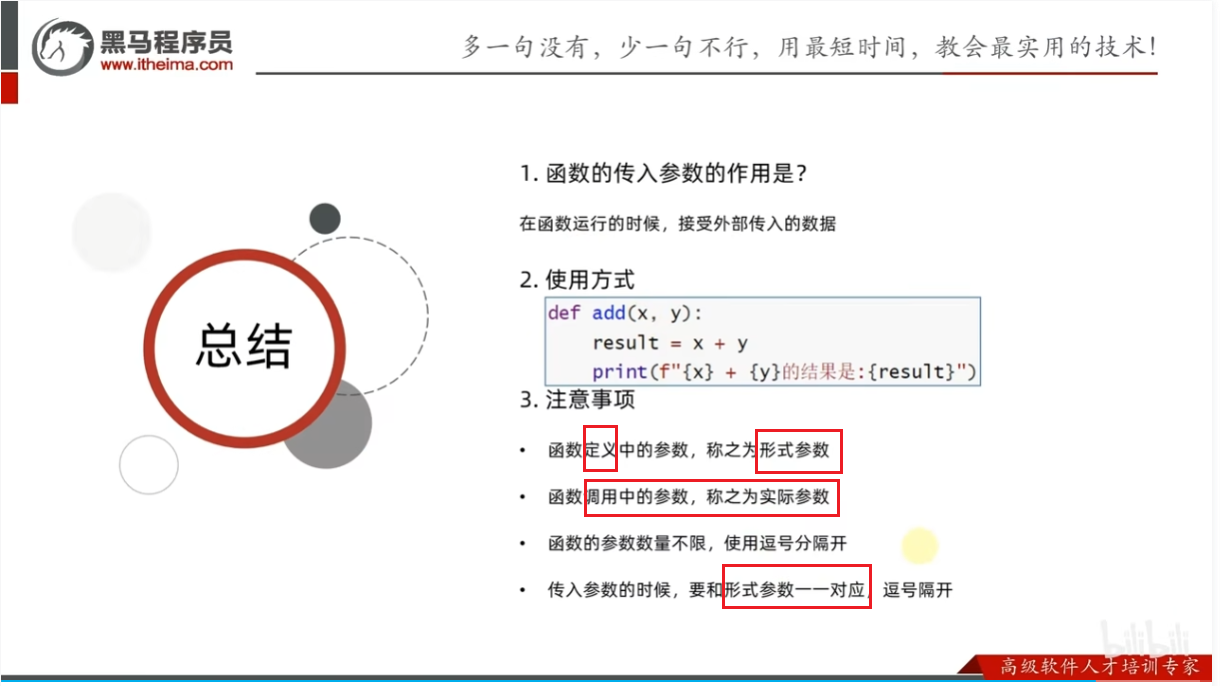
参数练习案例

"""
升级版自动查核酸
"""
def check(num):
print("欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!")
if num <= 37.3:
print(f"体温测量中,您的体温是:{num},体温正常请进")
else:
print(f"体温测量中,您的体温是:{num},需要隔离")
check(38)
函数的返回值定义语法
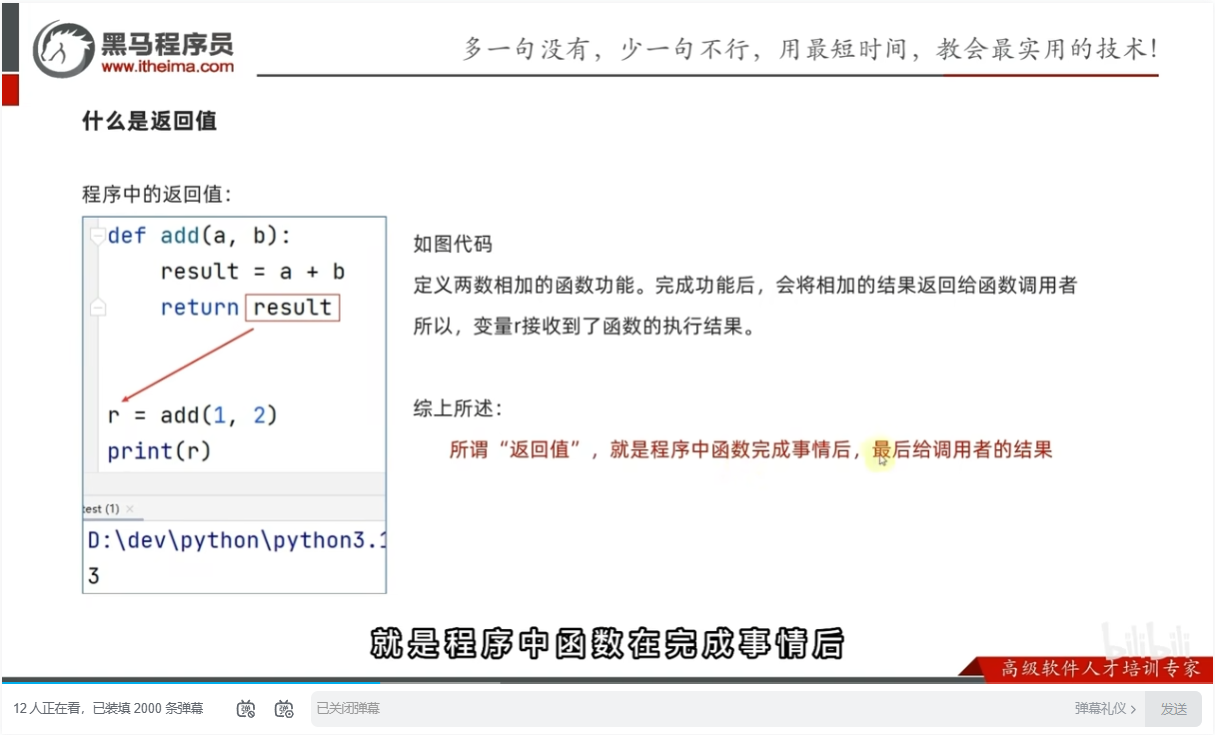
返回值语法

总结
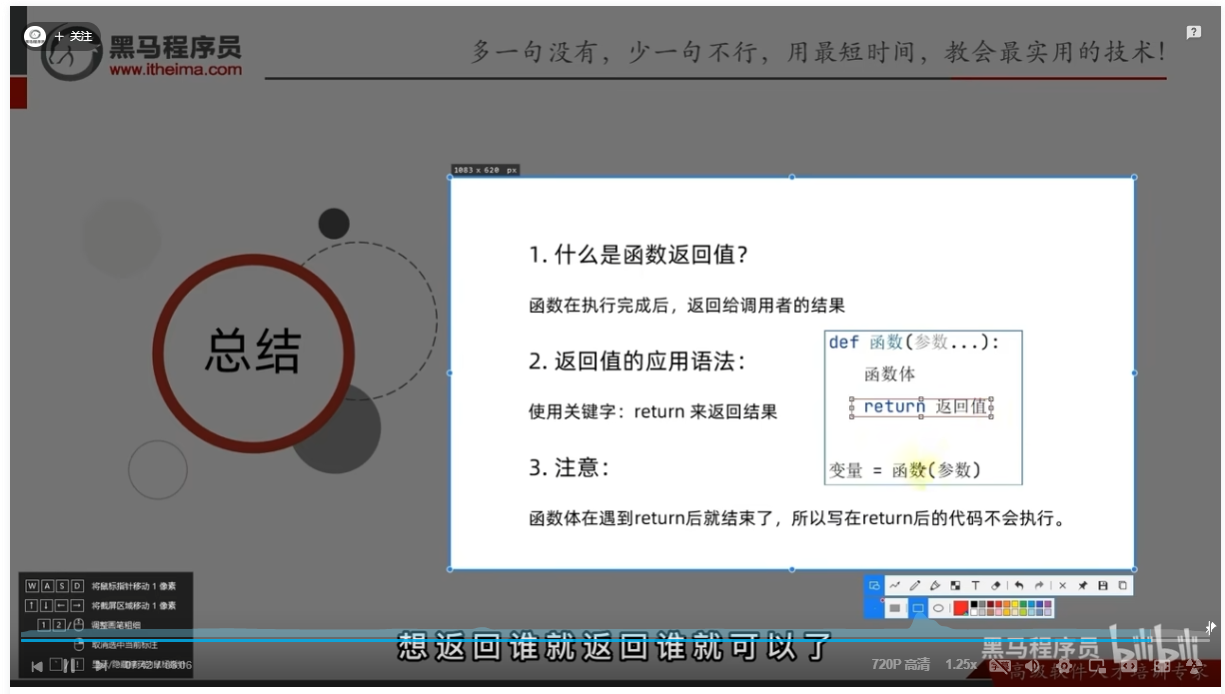
函数的返回值之None类型
None含义
None应用场景(3个)
总结
函数的说明文档

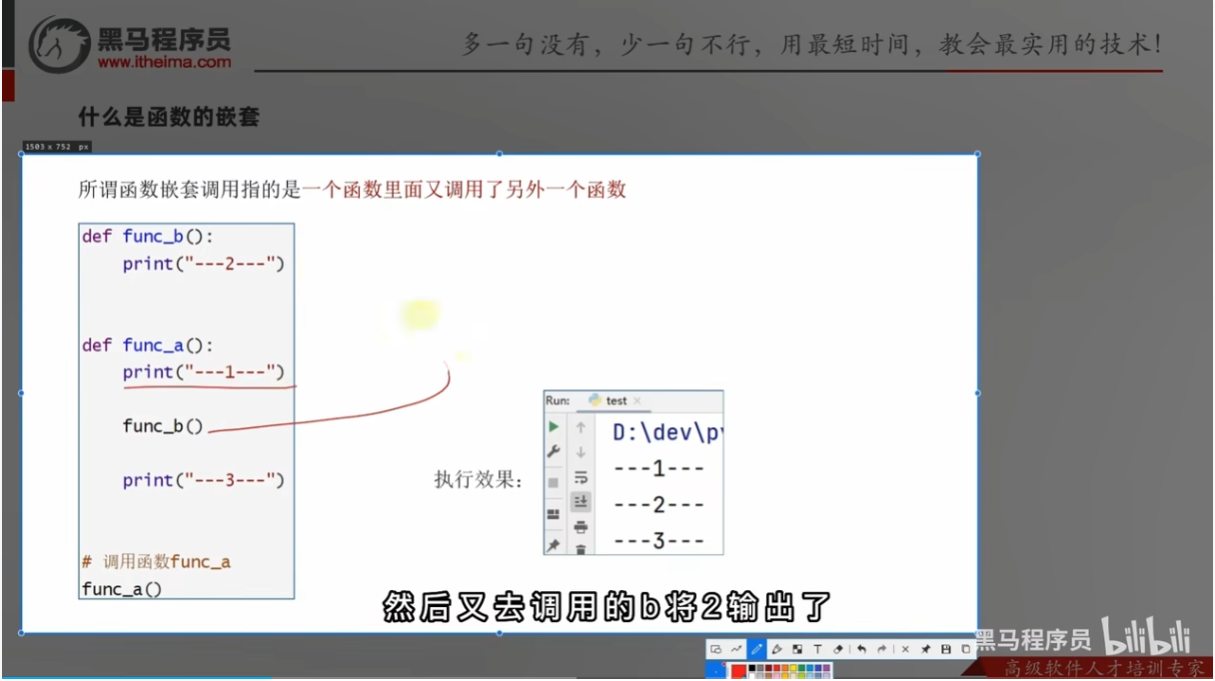
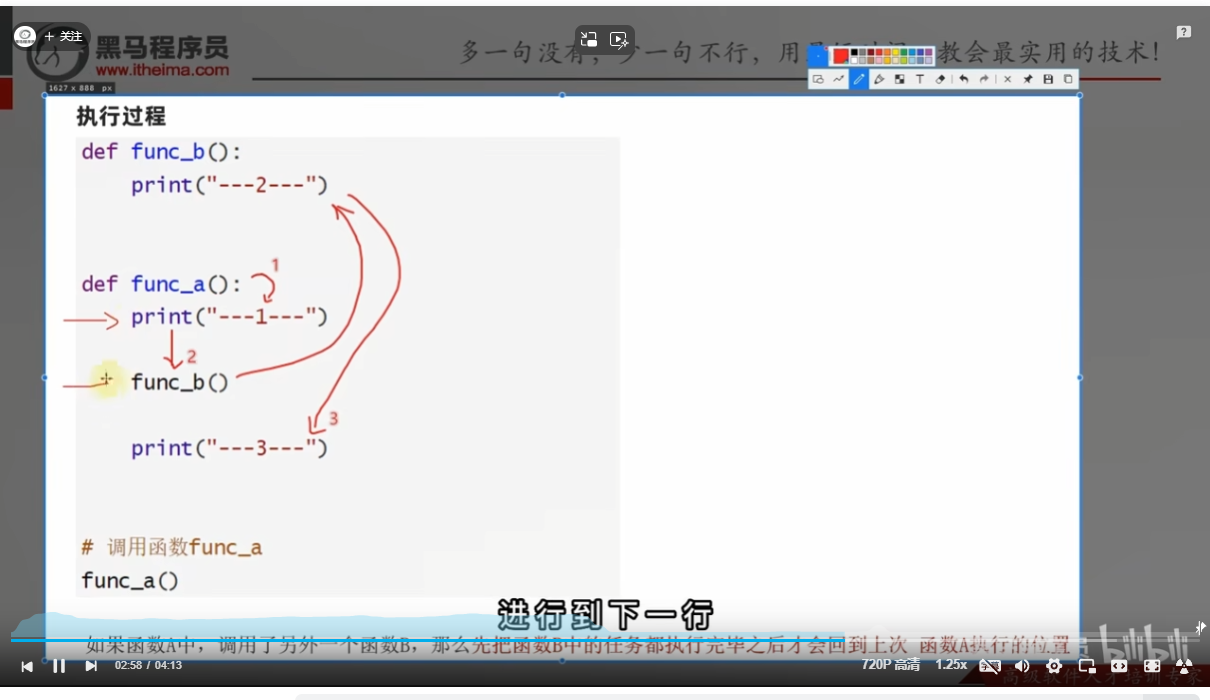
函数的嵌套调用
定义
执行过程
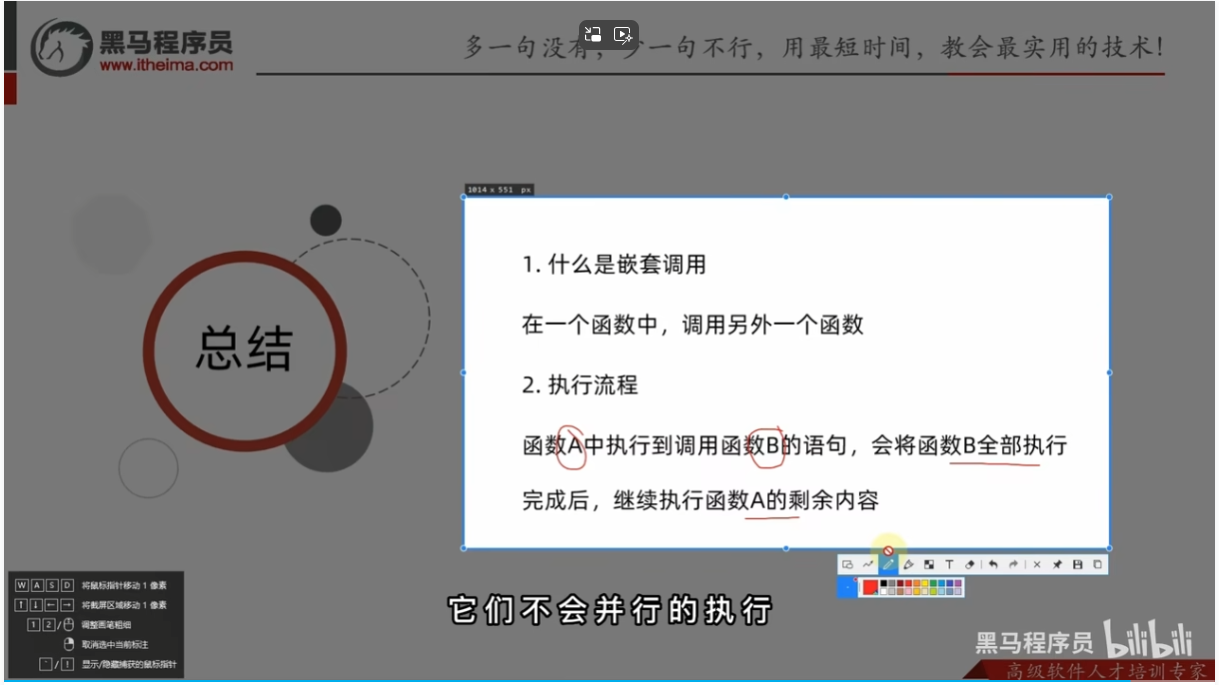
总结
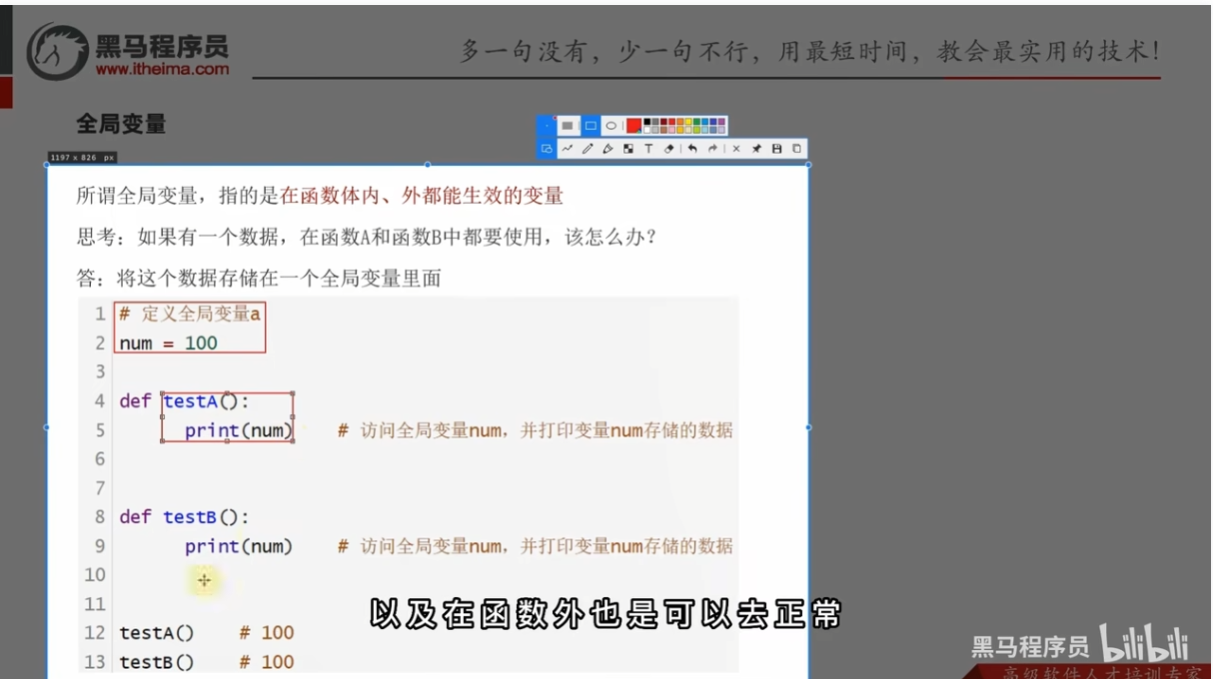
变量在函数中的作用域
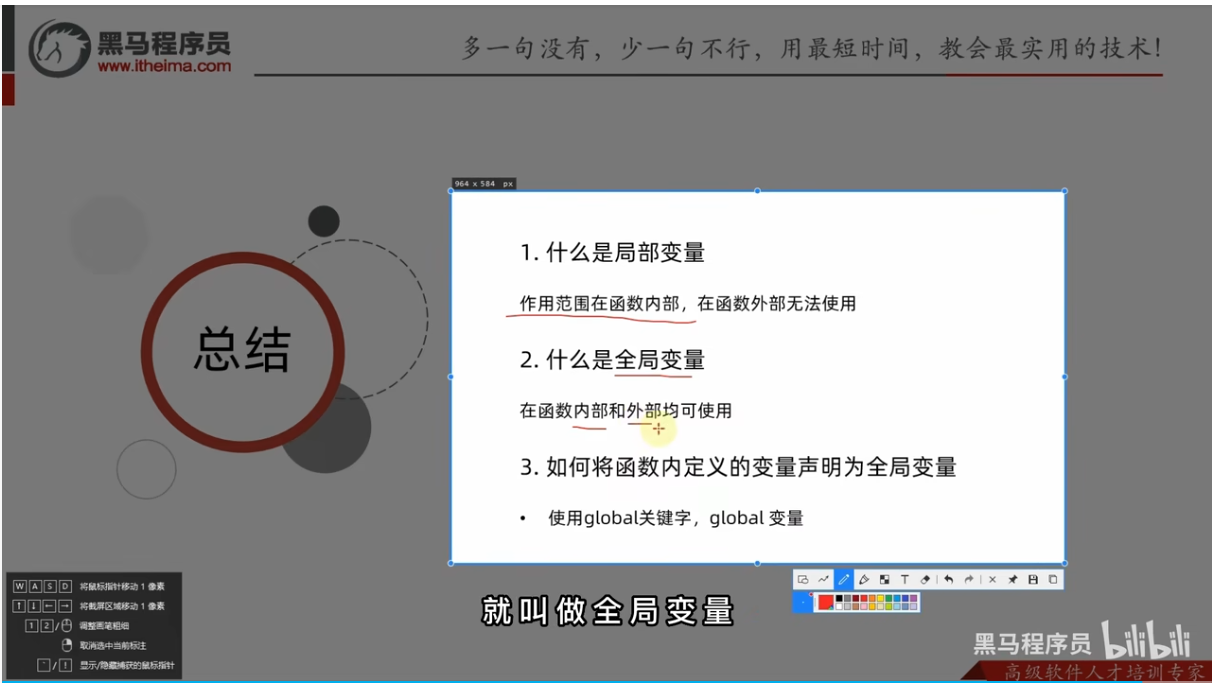
局部变量

全局变量
总结
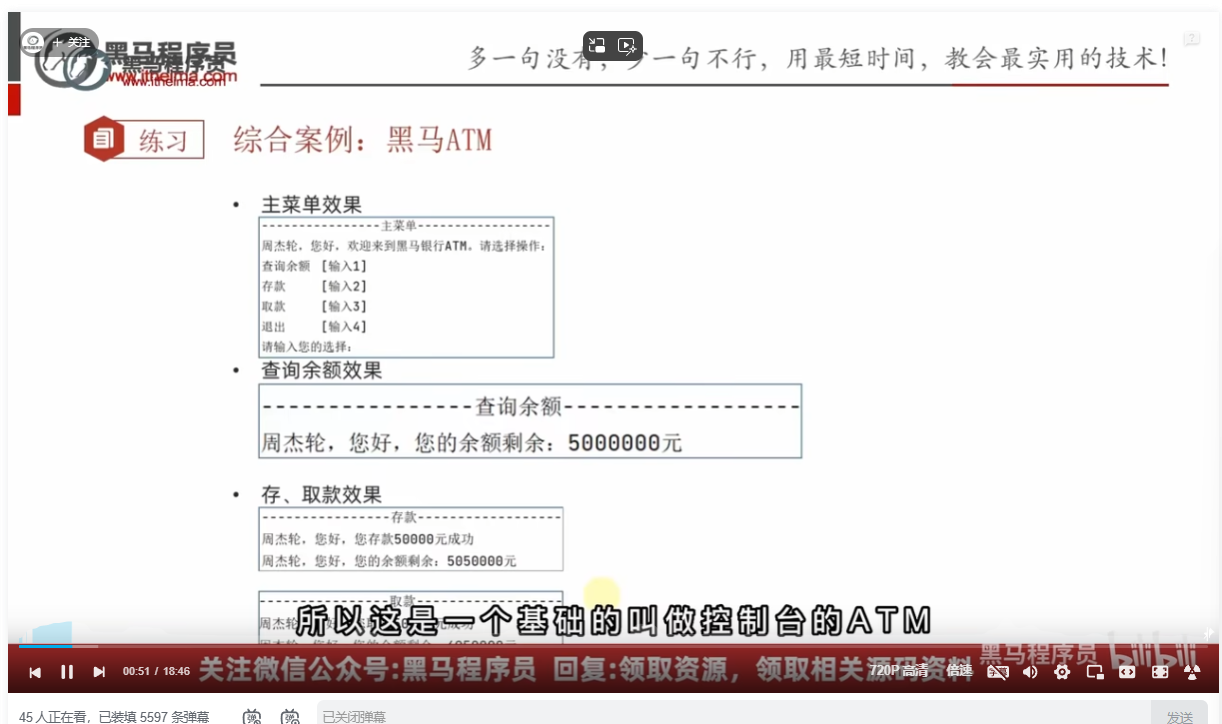
函数综合案例
"""
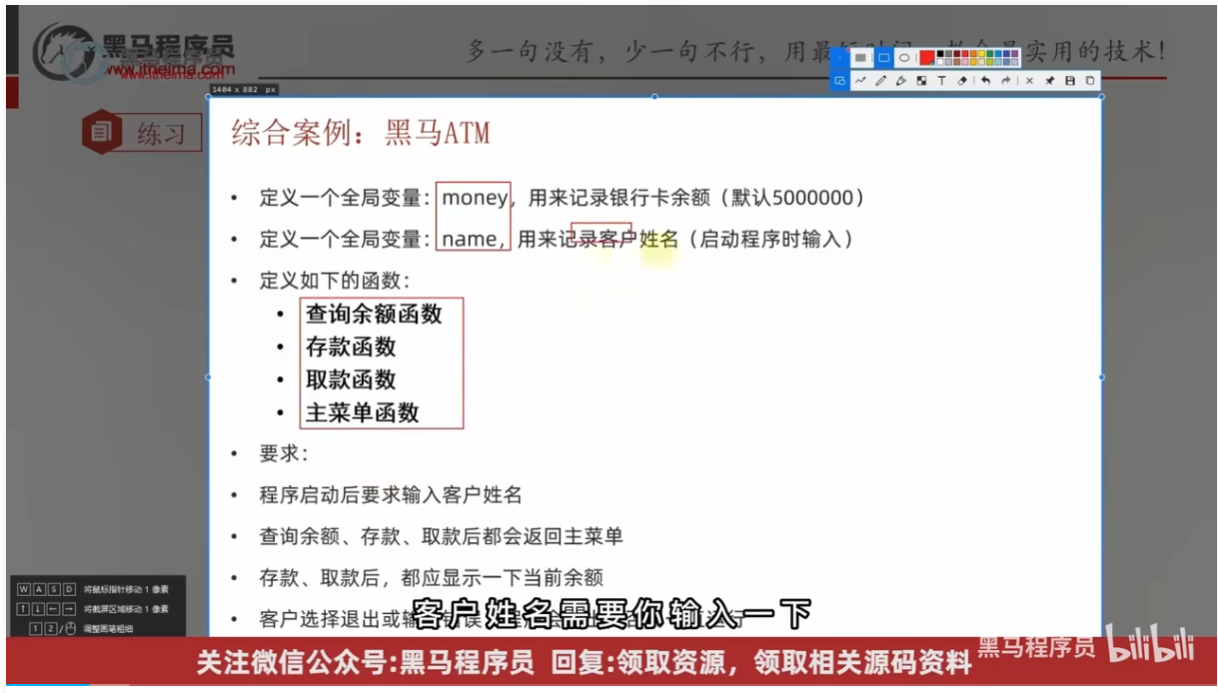
函数综合案例 控制台ATM
"""
# 定义全局变量 money name
money = 5000000
name = None
# 要求客户输入姓名
name = input("请输入您的姓名")
#定义查询余额函数
def query(show_header):
if show_header:
print("----------查询余额----------")
print(f"{name},您的余额剩余:{money}")
# 定义存款函数
def saving(num):
global money # money 在函数内部定义为全局变量
money += num
print("----------存款----------")
print(f"{name},您好,您存款{money}元成功")
# 通过query函数查询余额
query(False)
# 定义取款函数
def get_money(num):
global money
print("----------取款----------")
print(f"周杰伦,您好,您取款{num}元成功")
# 通过query函数查询余额
query(False)
# 定义主菜单函数
def main():
print("----------主菜单----------")
print(f"{name},您好,欢迎来到黑马程序员ATM,请选择操作")
print("查询余额\t[输入1]")
print("存款\t\t[输入2]") # 通过\t制表符对齐
print("取款\t\t[输入3]")
print("退出\t\t[输入4]")
return input("请输入你的选择")
# 退出(设置无限循环,确保程序不退出)
while True:
keyboard_input = main()
if keyboard_input == "1":
query(True)
continue # 通过continue继续下一次循环,一进来就是进入了主菜单
elif keyboard_input == "2":
num = int(input("您想要存多少钱?请输入:"))
saving(num)
elif keyboard_input == "3":
num = int(input("您想要取多少钱?请输入:"))
get_money(num)
continue
else:
print("程序退出了")
break
python数据容器
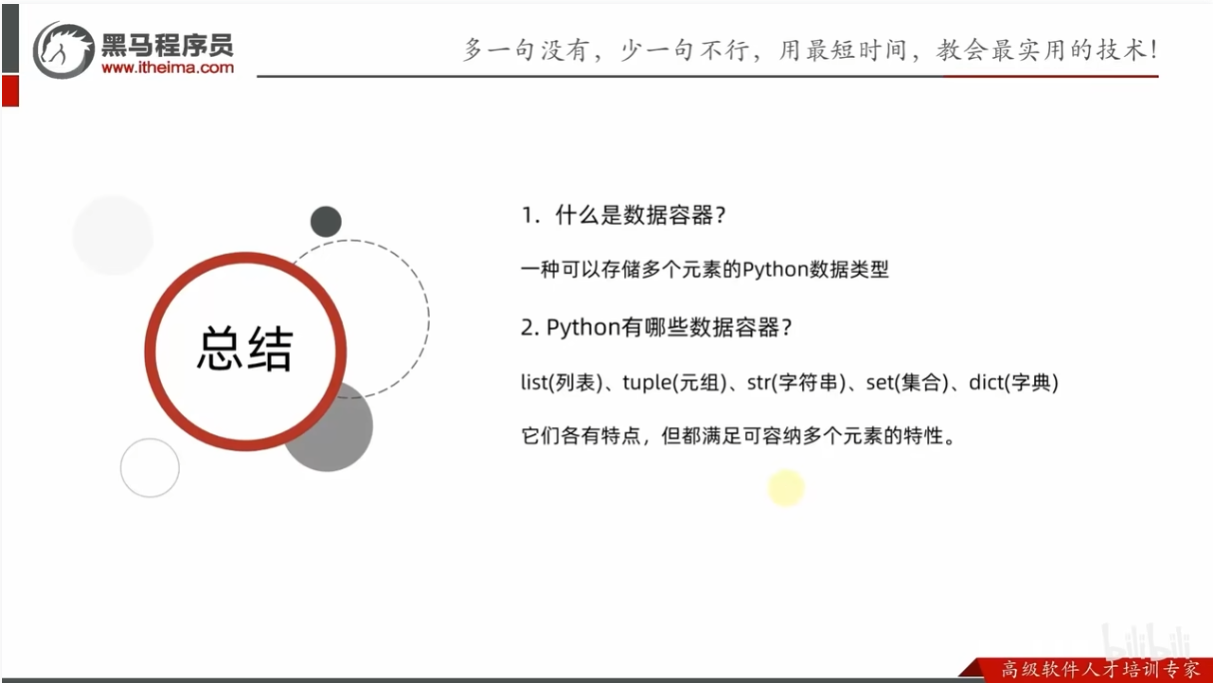
数据容器入门
数据容器

总结
数据容器-列表
list列表的定义语法
列表定义
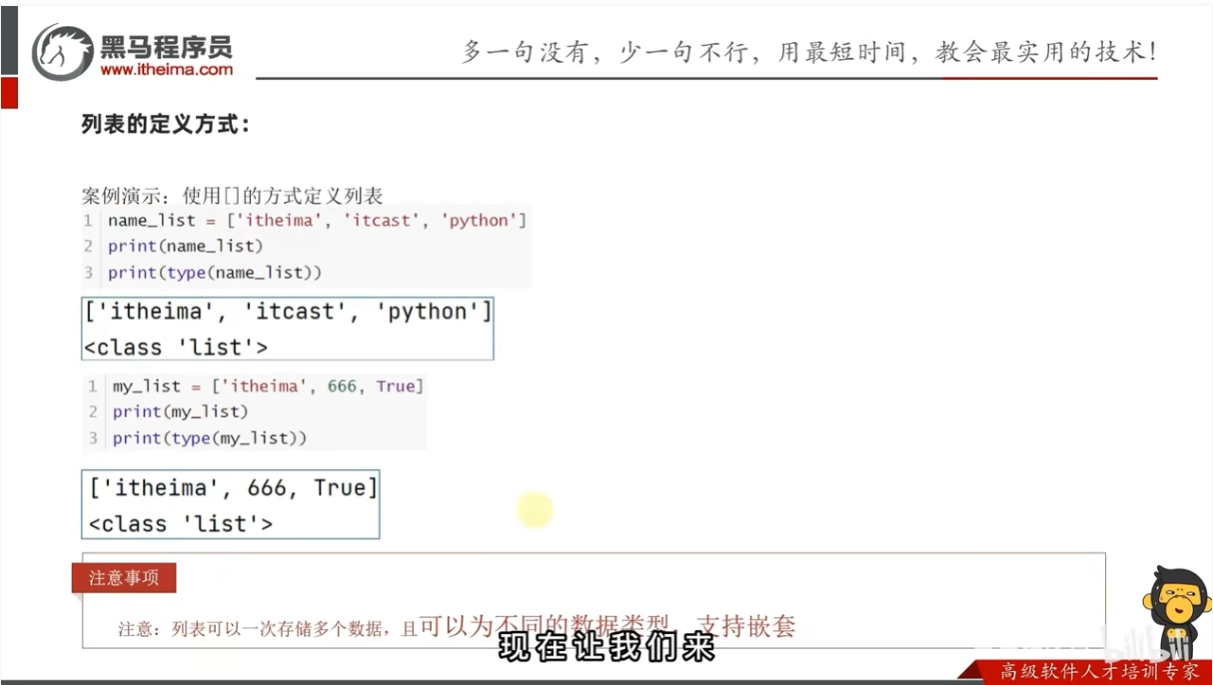
案例演示
总结
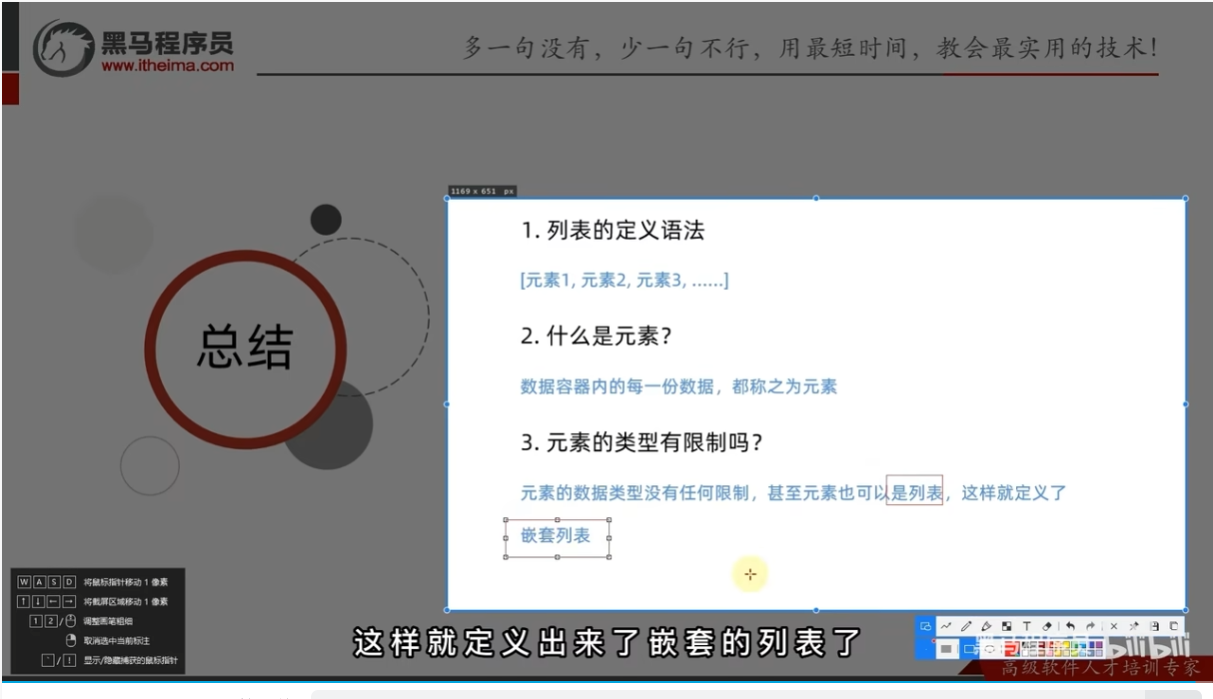
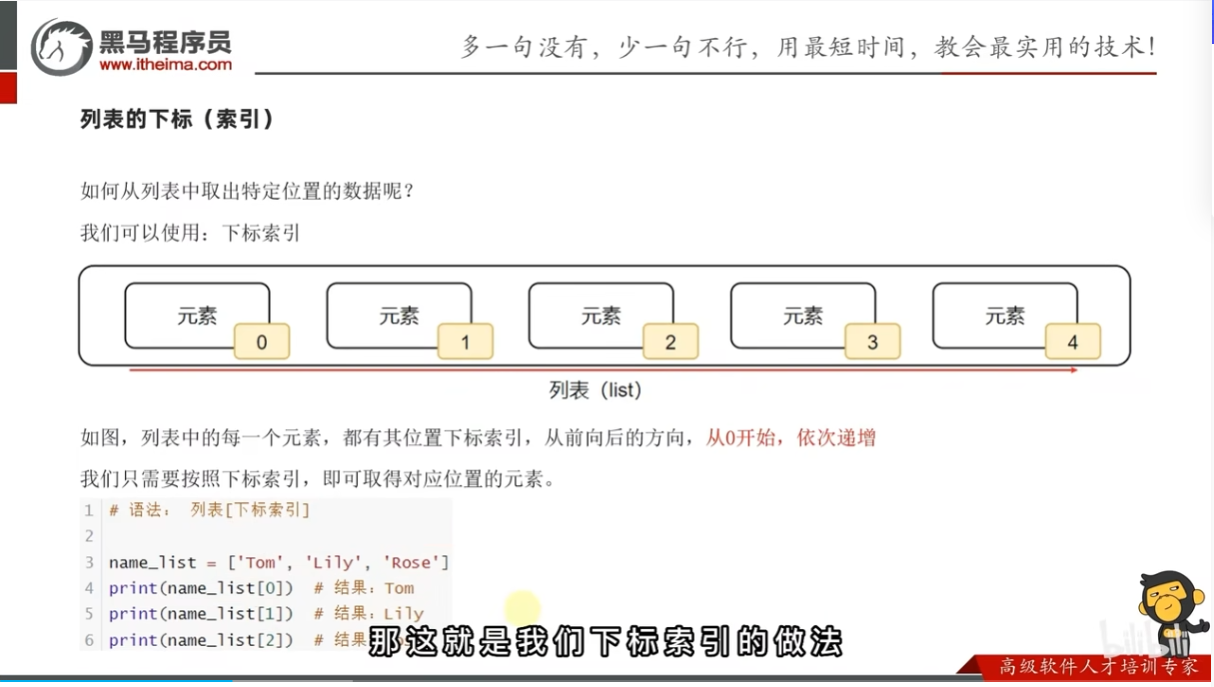
列表的下标索引
从列表中取出想要取的元素
语法:列表[下标索引]
反向取值元素

嵌套索引
# 取出嵌套列表的元素
my_list = [(1, 2, 3), [4, 5, 6]]
print(my_list[1][1])
总结
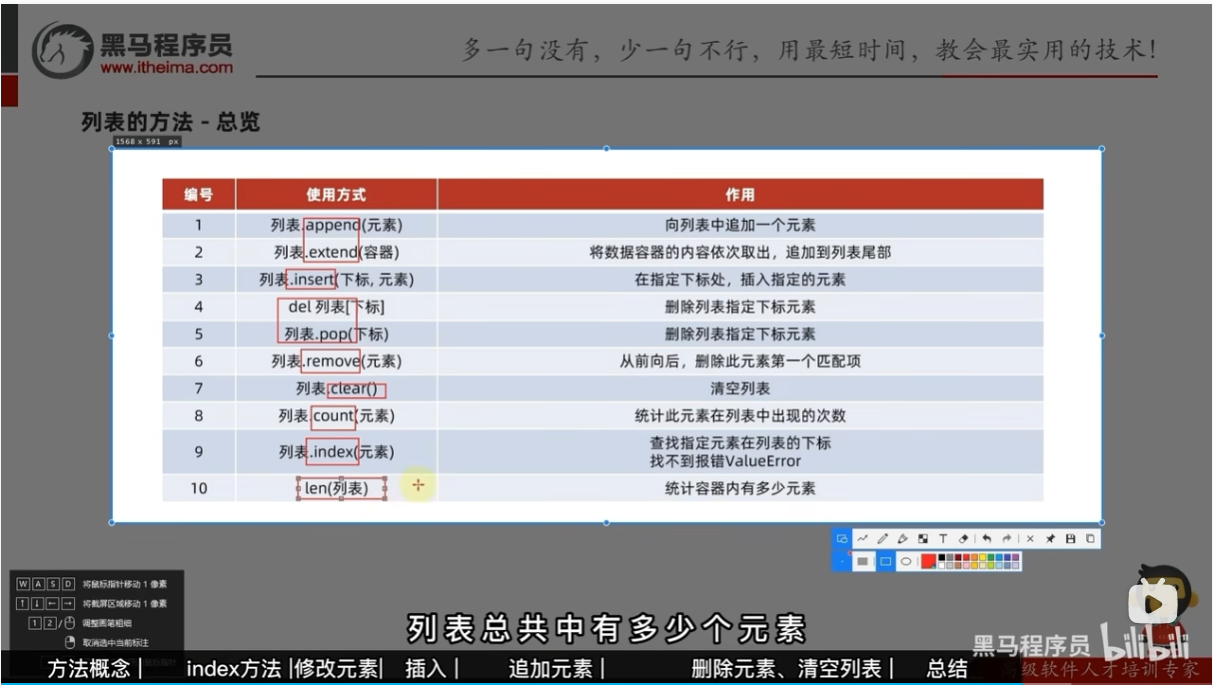
列表的常用操作方法
列表常用操作

列表的查询功能
将函数定义为class(类)的成员,函数就被称之为:方法

详细操作方法:
1.查找某元素在列表内的下标索引
语法:列表.index(元素)
index = mylist.index("itheima")
print(f"itheima在列表中的下标索引值是:{index}")
index就是列表对象(变量)内置的方法(函数)
2.修改特定下标索引的值
语法:列表[下标] = 值
mylist = ["itcast","itheima","python"]
mylist[0] = "传智教育"
print(f"列表被修改元素后,结果是:{mylist}")
3.插入元素
语法:列表.insert(下标,元素),在指定的下标位置,插入指定的元素
mylist = ["itcast","itheima","python"]
mylist.insert(1,"best")
print(f"列表插入元素后,结果是:{mylist}")
5.追加元素
①语法:列表.append(元素),将指定元素,追加到列表尾部
mylist = ["itcast","itheima","python"]
mylist.append("黑马程序员")
print(f"列表在追加了元素后,结果是:{mylist}")
②语法:列表extend(其它数据容器), 将其它数据容器的内容取出,依次追加到列表尾部
mylist2 = [1,2,3]
mylist.extend(mylist2)
print(f"列表在追加了新的列表后,结果是:{mylist}")
4.删除元素
- del列表[下标]
python
mylist = ["itcast","itheima","python"]
del mylist[2]
print(f"列表删除元素后的结果是:{mylist}")
- 列表.pop(下标)
python
mylist = ["itcast","itheima","python"]
mylist.pop(0)
element = mylist.pop(0)
print(f"通过pop方法取出元素后列表内容:{mylist},取出的元素师:{element}")
- 删除某元素在列表中的第一个匹配项:列表.remove(元素)
python
mylist = ["itcast","itheima","itcast","itheima","python"]
mylist.remove("itheima")
print(f"通过remove方法移除元素后,列表的结果是:{mylist}")
- 清空列表内容,语法:列表.clear()
python
mylist.clear()
print(f"列表被清空了,结果是:{mylist}")
5 统计某元素在列表内的数量
语法:列表.count(元素)
mylist = ["itcast","itheima","itcast","itheima","python"]
count = mylist.count("itheima")
print(f"列表中的itheima的数量是:{count}")
6 统计列表内,有多少元素
语法:len(列表)
mylist = ["itcast","itheima","itcast","itheima","python"]
count = len(mylist)
print(f"列表的元素数量总共有:{count}")
说明-格局
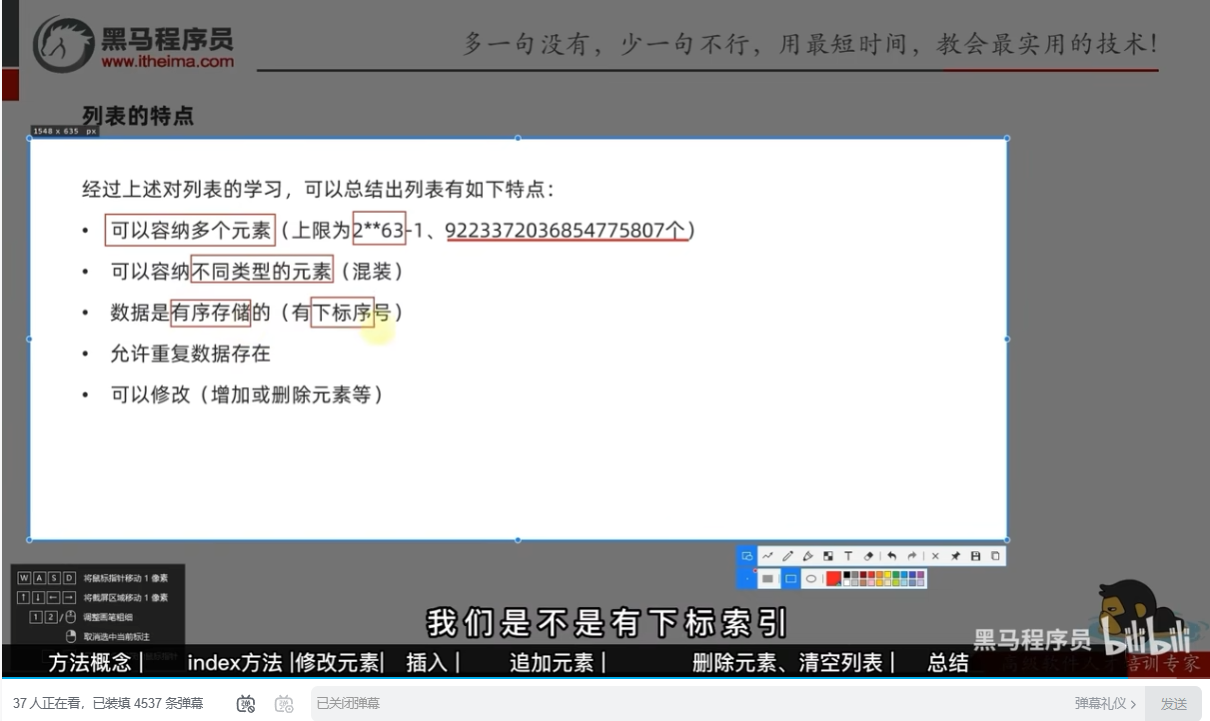
列表的特点
列表的循环遍历
列表的遍历-while循环
遍历:将容器内的元素依次取出进行处理的行为

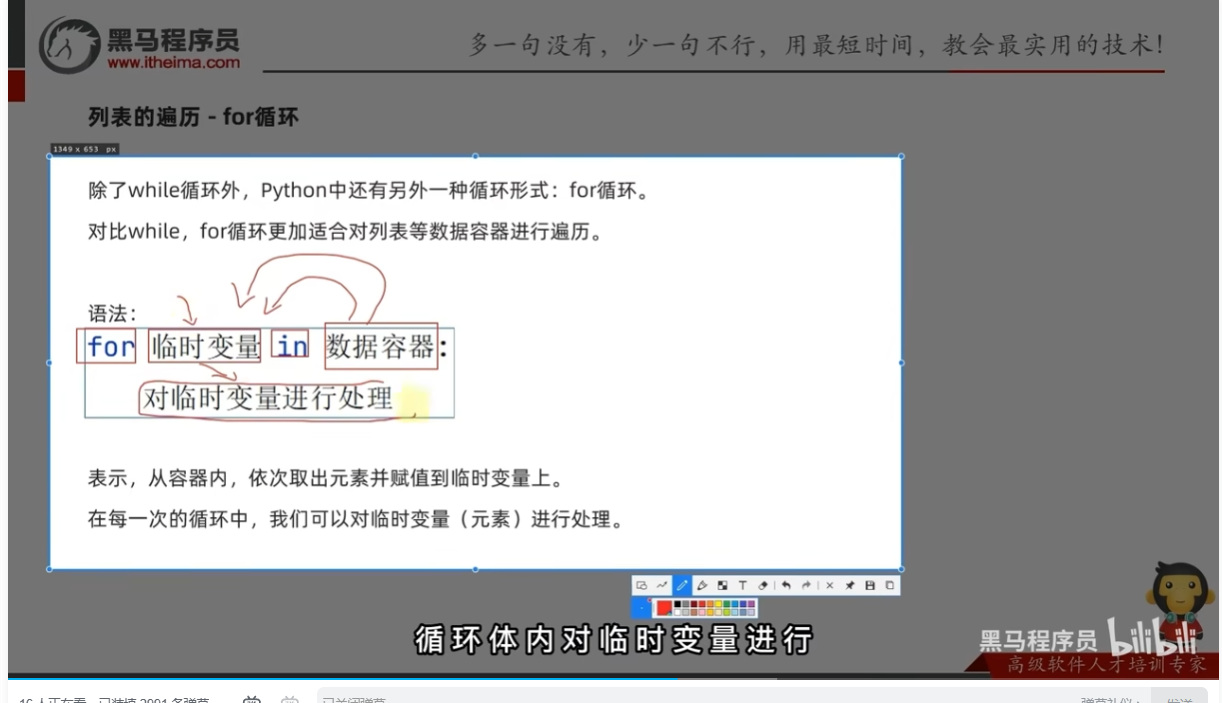
列表的遍历-for循环
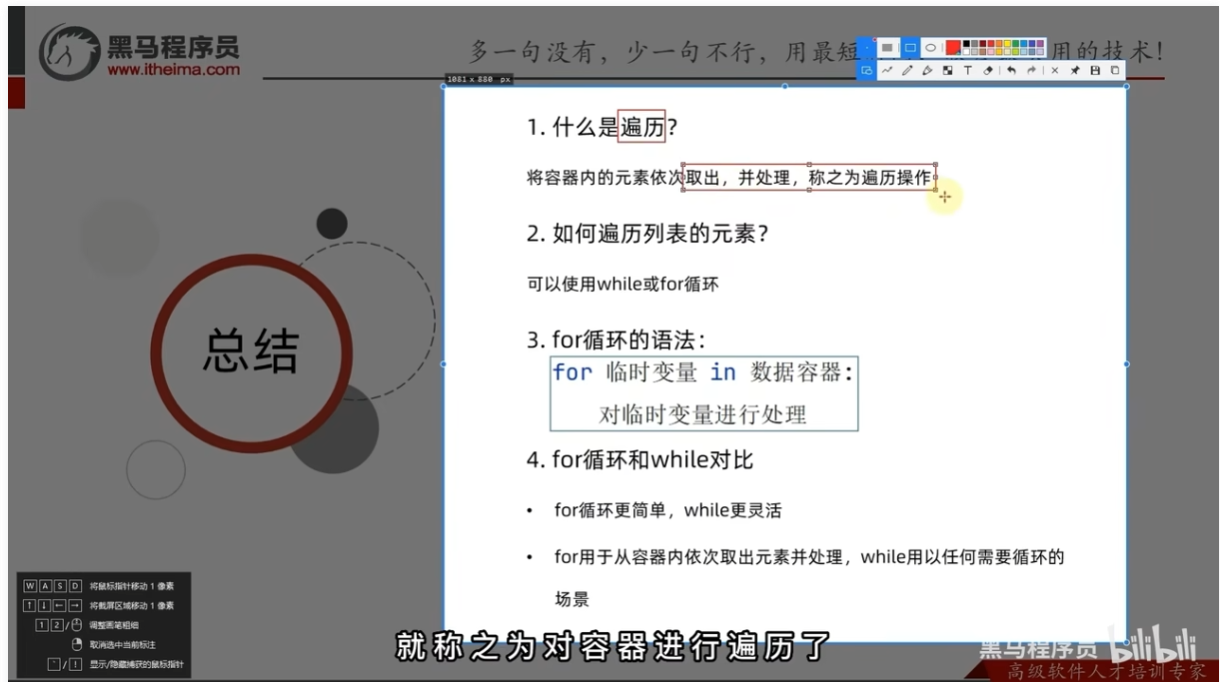
两者对比

总结
课后练习(第一次独立写那么长的代码,疯狂鼓掌,另感谢gpt的特别出席!)
"""
列表的遍历应用:取出列表内的偶数
"""
# 定义一个列表
mylist = [1,2,3,4,5,6,7,8,9,10]
mylist2 =[]
# while循环
index = 0
def list_while_func():
"""
使用while循环遍历列表的演示函数
:return: None
"""
global index
while index < len(mylist):
element = mylist[index]
if element % 2 == 0:
mylist2.append(element)
index += 1
# for 循环
def list_for_func():
"""
使用for循环遍历列表的演示函数
:return: None
"""
for element in mylist:
if element % 2 == 0:
mylist2.append(element)
# 清空 mylist2 后运行两个函数
mylist2.clear()
list_while_func()
# 在调用完 while 循环后,打印结果
print(f"通过while循环,从列表:{mylist}中取出偶数,组成新列表{mylist2}")
mylist2.clear() # 清空 mylist2,避免重复
list_for_func()
print(f"通过for循环,从列表:{mylist}中取出偶数,组成新列表{mylist2}")
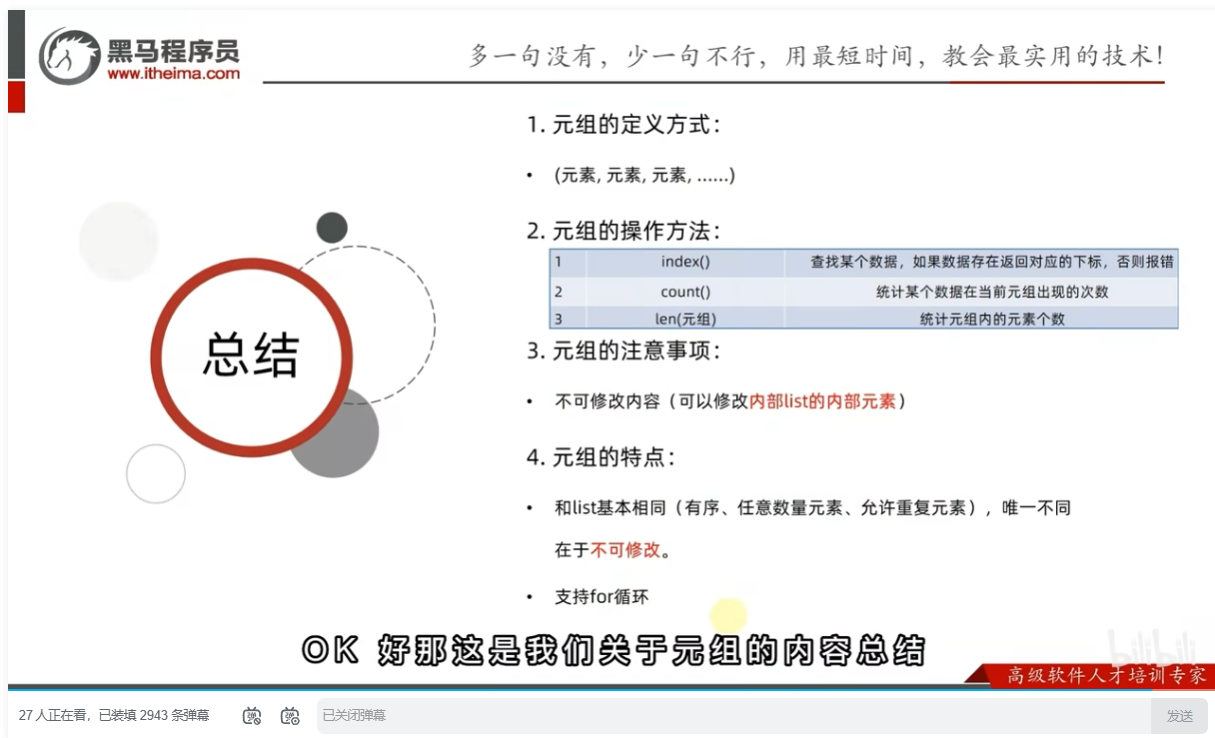
元组的定义和操作

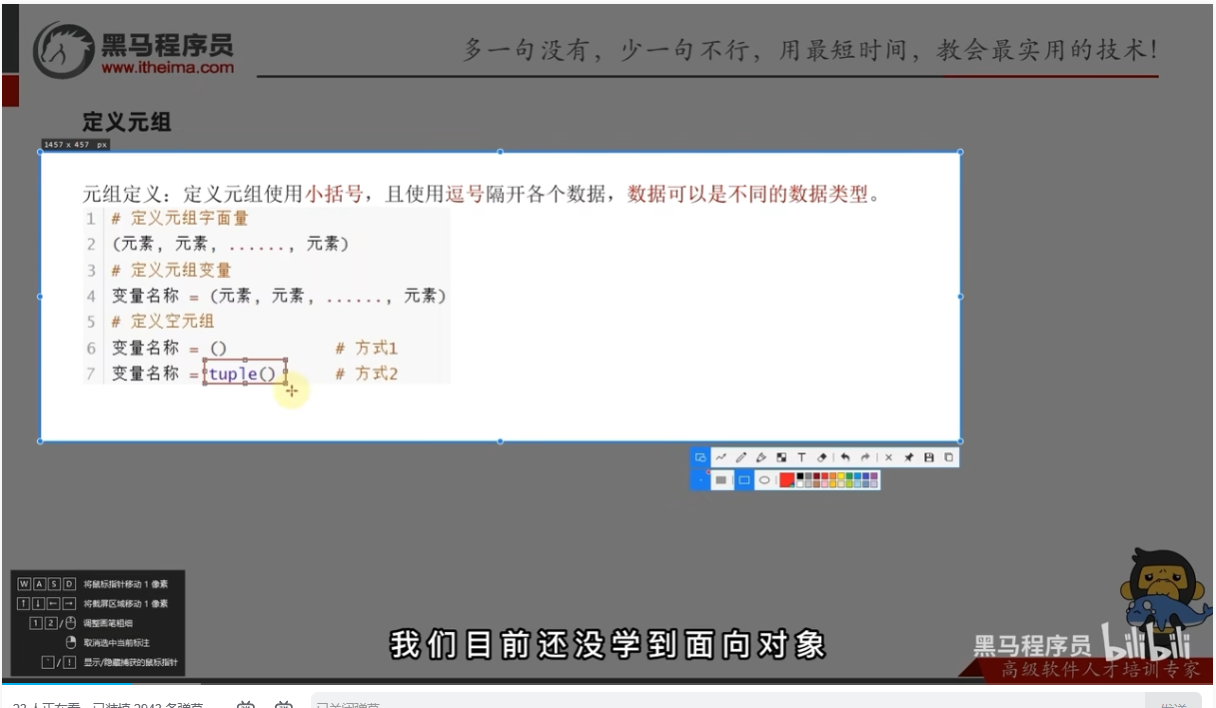
元组定义
元组特点

总结
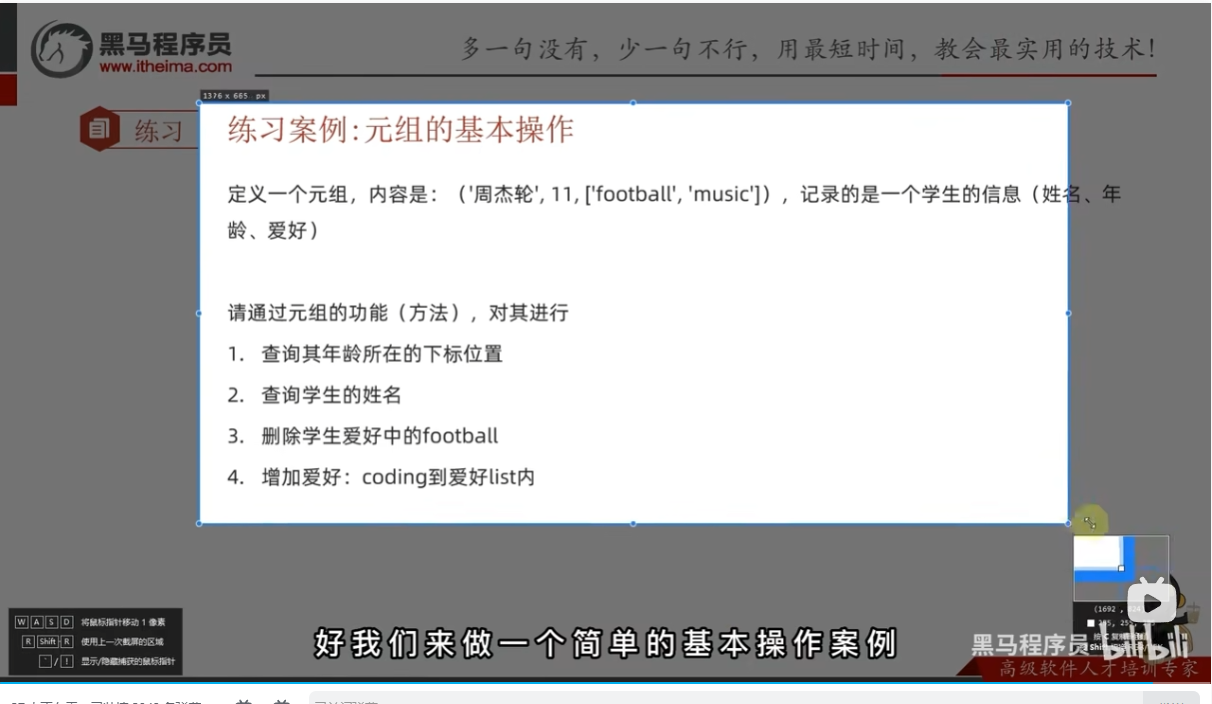
练习
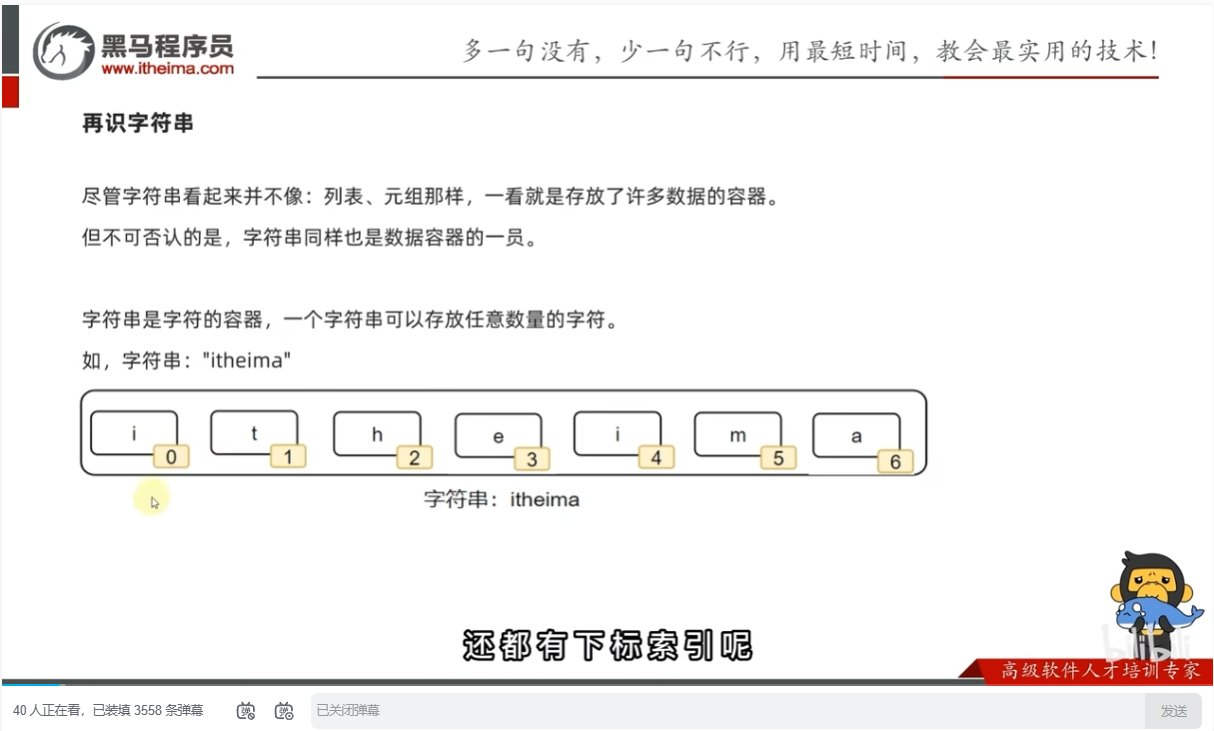
字符串的定义和操作
字符串
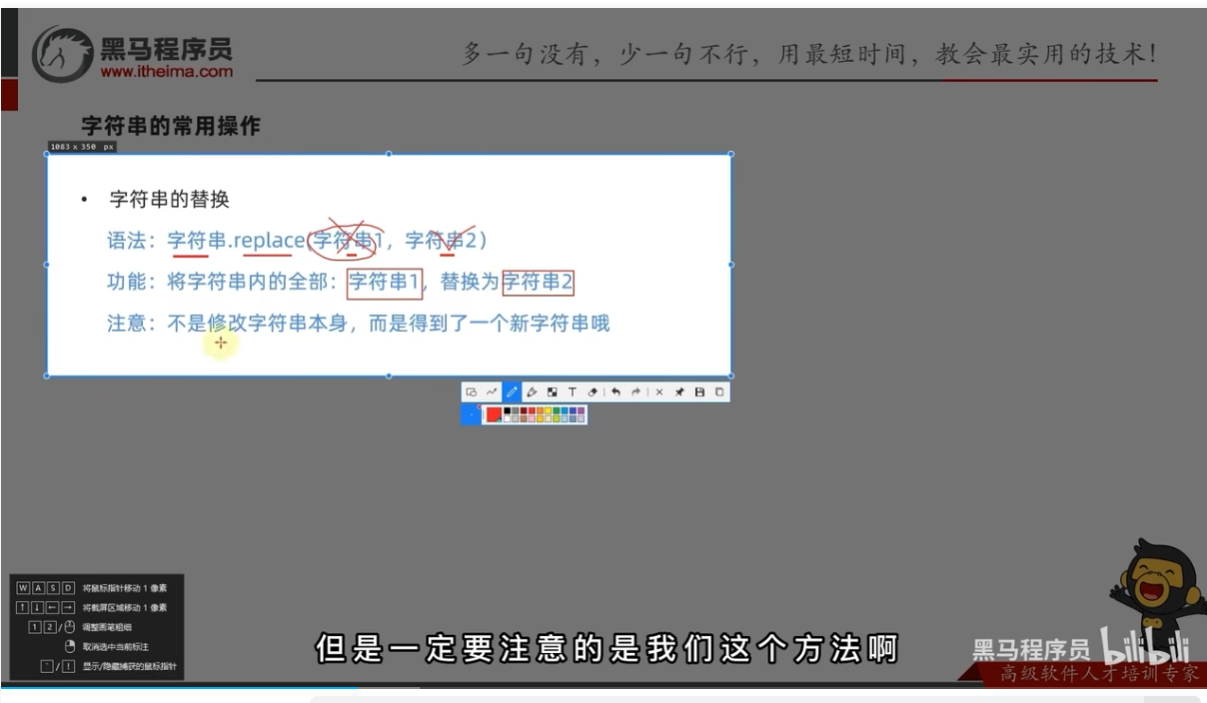
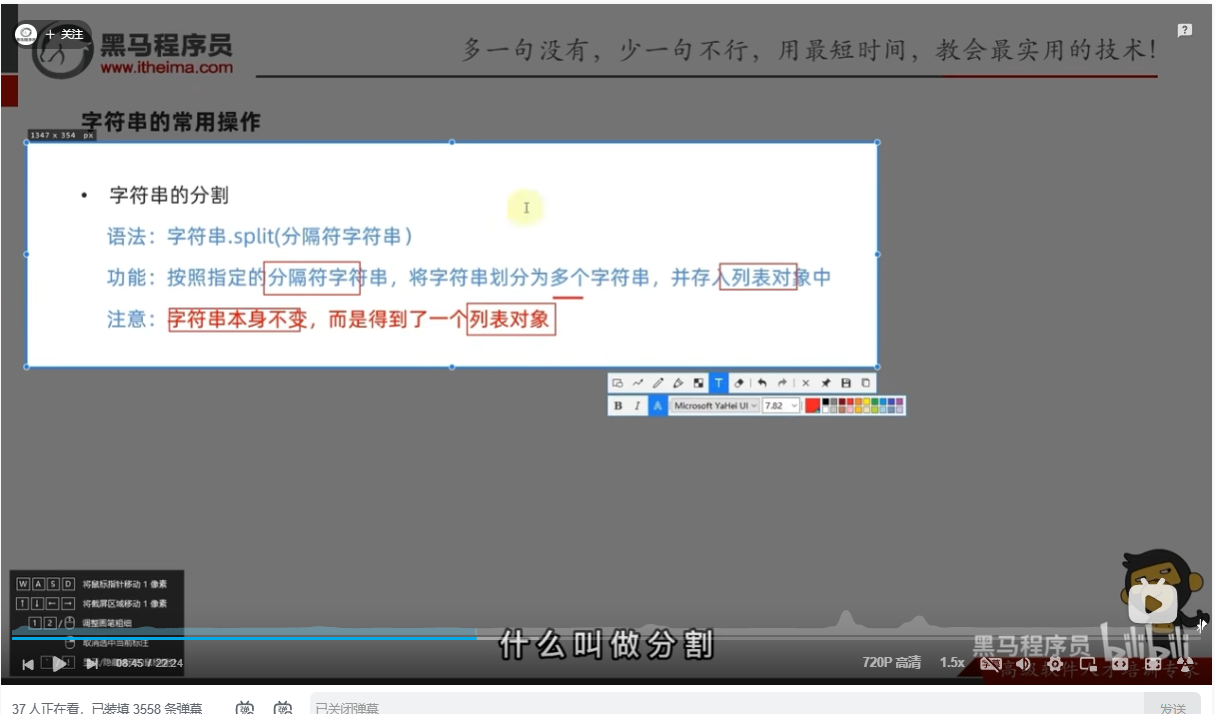
字符串的常用操作
字符串的分割:字符串.split(分隔符字符串)
注意:字符串本身不变,而是得到一个列表对象
# split方法 分隔字符串后,得到一个新的列表
my_str = "hello python itheima itcast"
my_str_list = my_str.split(" ")
print(f"将字符串{my_str}进行split切分后得到:{my_str_list},类型是:{type(my_str_list)}")
# 结果:将字符串hello python itheima itcast进行split切分后得到:['hello', 'python', 'itheima', 'itcast'],类型是:<class 'list'>
字符串的规整操作
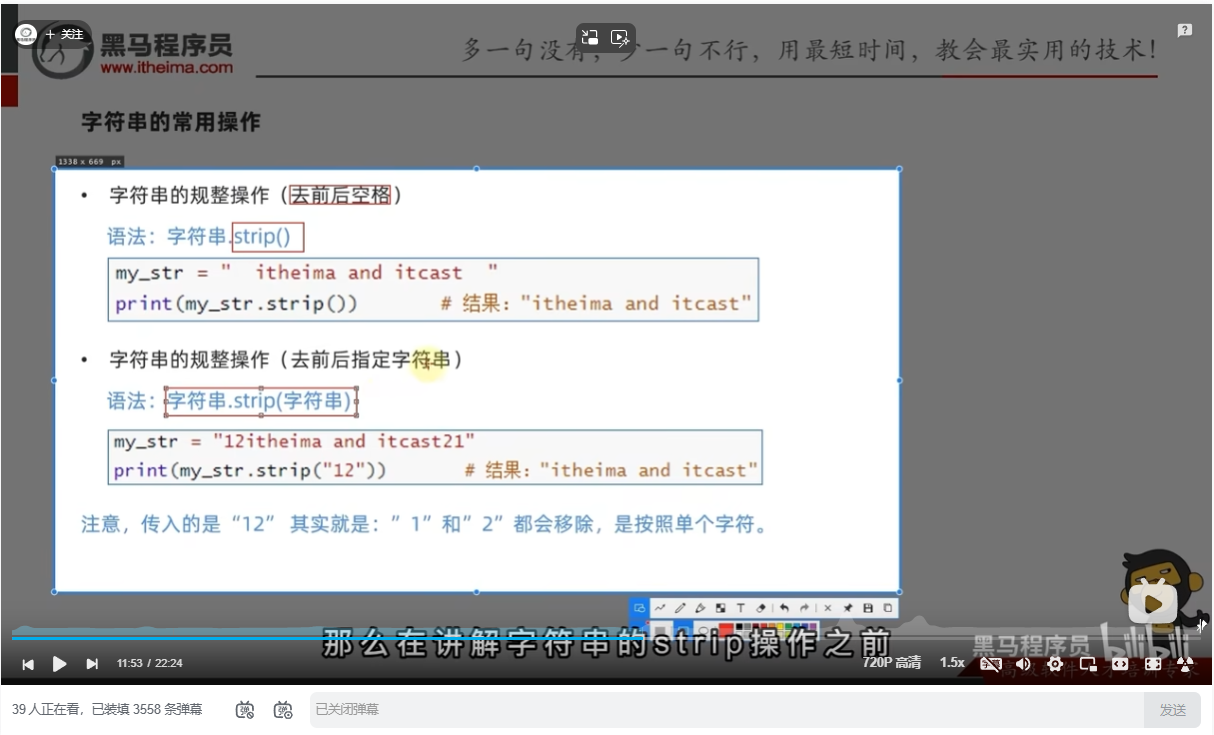
# strip方法 字符串的规整,自动去掉字符串前后的空格
my_str = " itheima and itcast "
new_my_str_list = my_str.strip() # 不传入参数,取出首尾空格
print(f"字符串{my_str}被strip后,结果是{new_my_str_list}")
字符串常用操作

字符串的遍历
"""
字符串遍历
"""
my_str = "黑马程序员"
index = 0
while index < len(my_str):
print(my_str[index])
index += 1
my_str = "黑马程序员"
for i in my_str:
print(i)
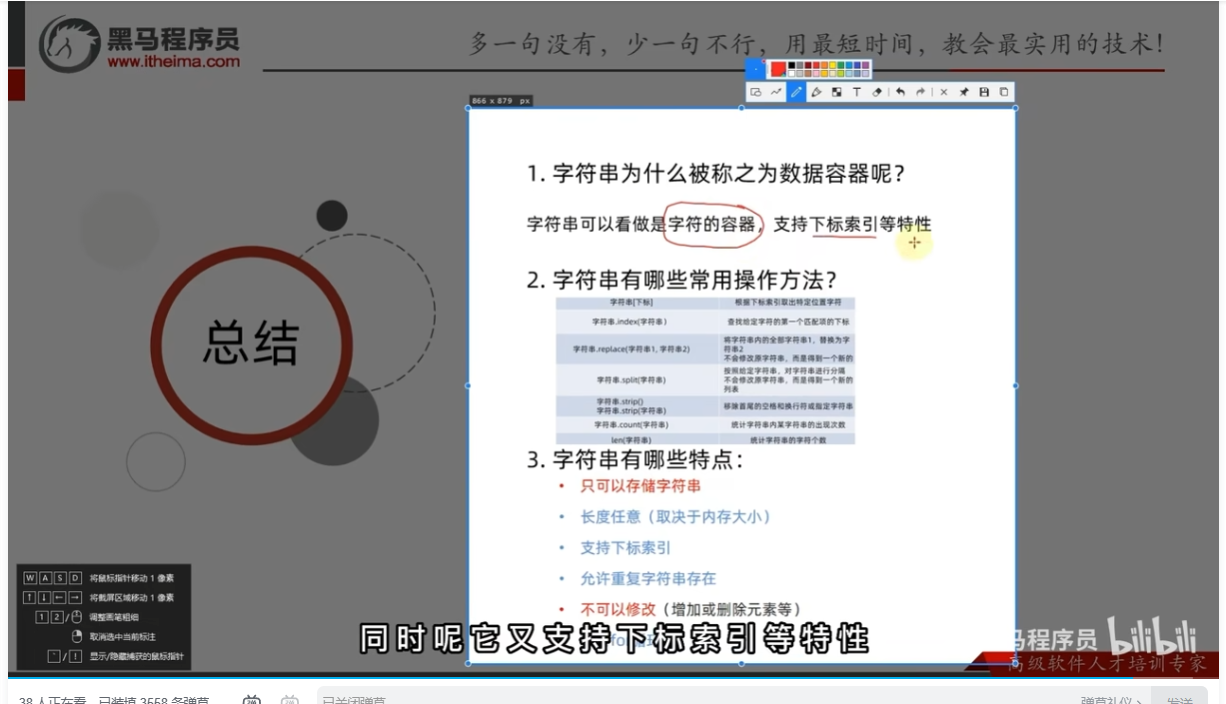
字符串的特点

总结
数据容器(序列)切片
定义
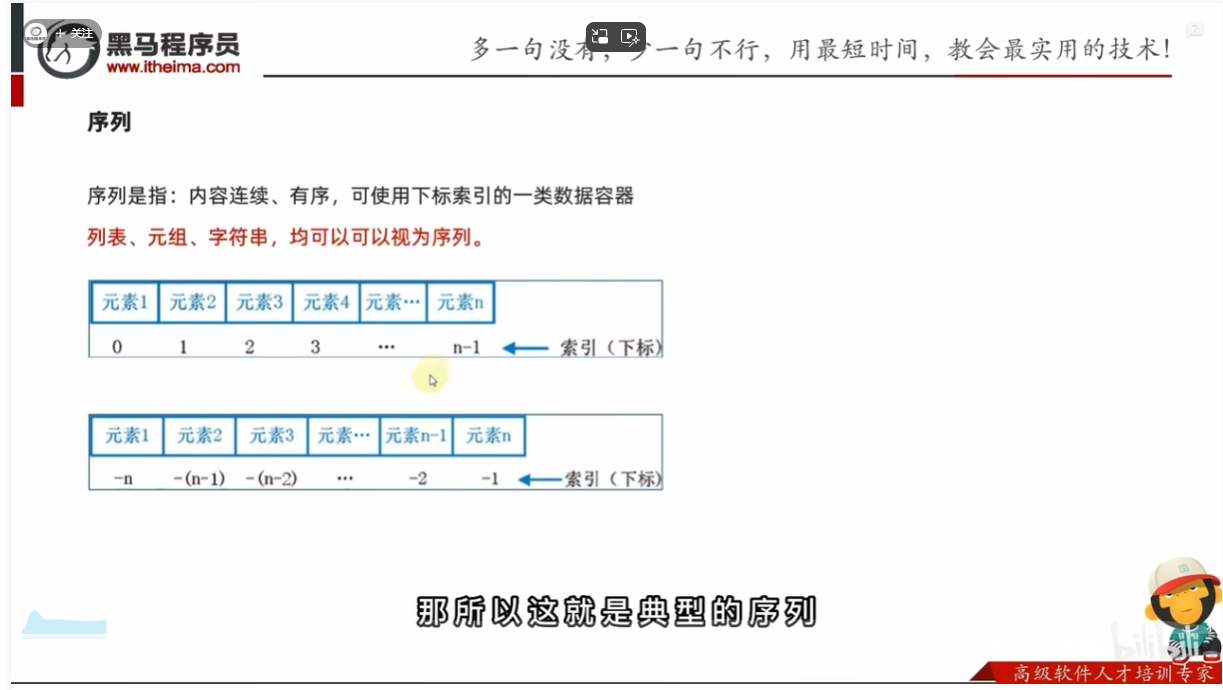
切片定义
从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
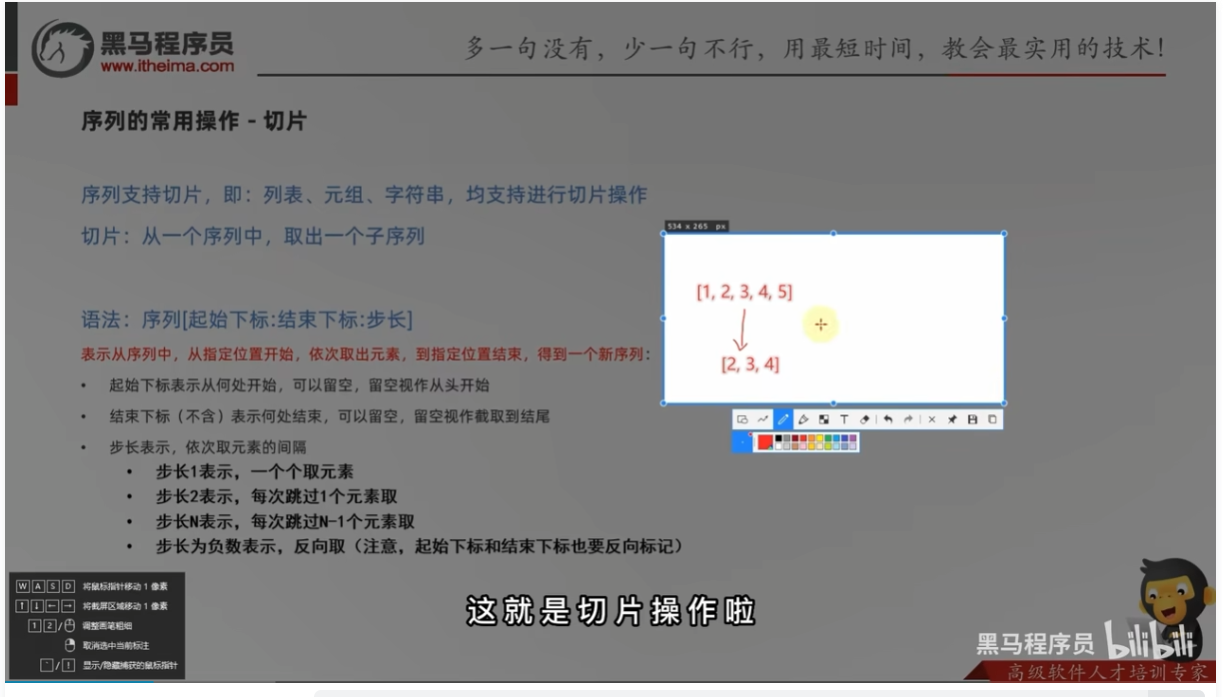
"""
对序列进行切片,从1开始,4结束,步长1
"""
# 对列表list进行切片,从1开始,4结束,步长1
my_list = [0, 1, 2, 3, 4, 5, 6]
result1 = my_list[1:4]
print(f"结果1:{result1}")
# 对元组tuple进行切片,从头开始,到最后结束,步长1
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result2 = my_tuple[:] # 起始和结束不写表示从头到尾,步长为1
print(f"结果1:{result2}")
# 对字符串str进行切片,从头开始,到最后结束,步长2
my_str = "01234567"
result3 = my_str[::2]
print(f"结果1:{result3}")
# 对str进行切片,从头开始,到最后结束,步长-1
my_str = "01234567"
result4 = my_str[::-1] #-1表示从后向前取 等于将序列翻转了
print(f"结果1:{result4}")
# 对列表进行切片,从3开始,到1结束,步长-1
my_list = [0, 1, 2, 3, 4, 5, 6]
result5 = my_list[3:1:-1]
print(f"结果1:{result5}")
# 对元组进行切片,从头开始,到尾结束,步长-2
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result6 = my_tuple[::-2]
print(f"结果1:{result6}")
总结

练习案例:序列的切片实践
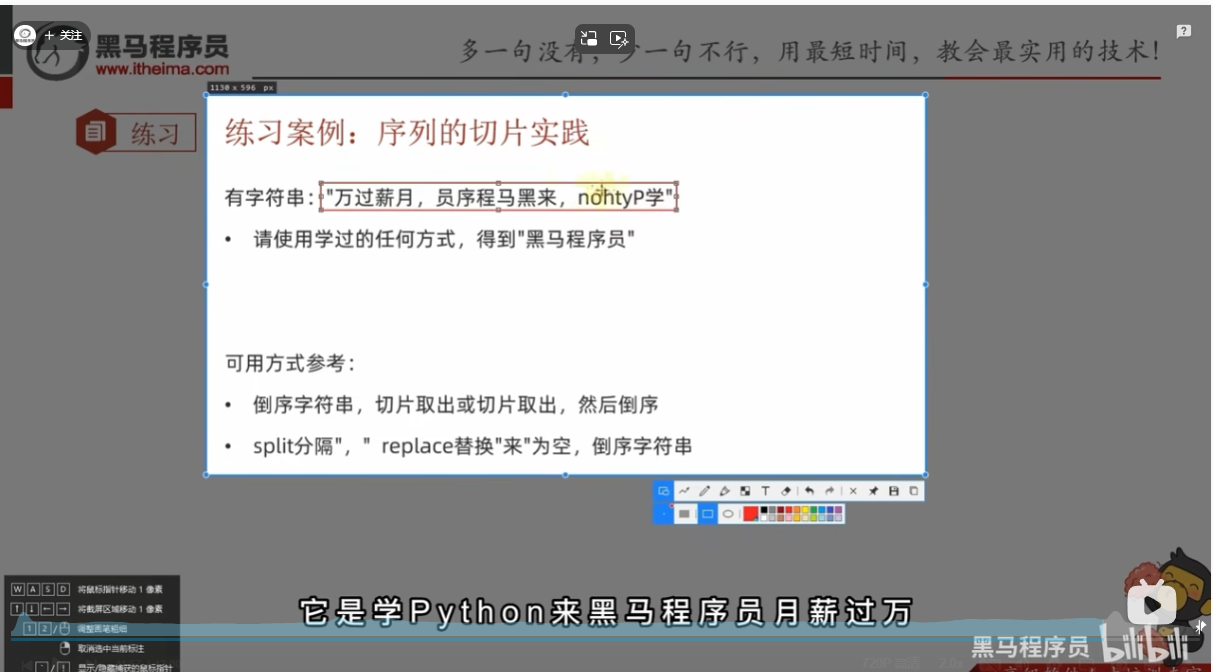
"""
序列的切片实践
"""
# 请使用学过的任何方式,得到"黑马程序员”
my_str = "月过万薪, 员序程马黑来, nohtyp学"
# 可用方式参考:
# 1、倒序字符串,切片取出或切片取出,然后倒序
# 2、split分隔","replace替换"来"为空,倒序字符串
# 倒序字符串,切片取出
result1 = my_str[::-1][9:14]
print(result1)
# 切片取出,然后倒序:从10开始到4结束,步长为-1 ? 也是可以滴 反向步长的切片可以从右往左取字符串
# result = my_str[9:4:-1]
# print(result)
result3 = my_str[5:10][::-1]
print(result3)
# split分隔","replace替换"来"为空,倒序字符串
my_str = "月过万薪, 员序程马黑来, nohtyp学"
result4 = my_str.split(", ")[1].replace("来","")[::-1]
print(result4)
集合的定义和操作
为什么使用集合(set)?
不支持元素重复,内容无序→所以不支持下标索引

# 定义集合
my_set = {"传智教育","黑马程序员","itheima","传智教育","黑马程序员","itheima","传智教育","黑马程序员","itheima"}
my_set_empty = set() # 定义空集合
print(f"my_set的内容是:{my_set},类型是:{type(my_set_empty)}")
print(f"my_set_empty的内容是:{my_set_empty},类型是:{type(my_set_empty)}")
集合的常用操作-修改
- 取出2个集合的差集
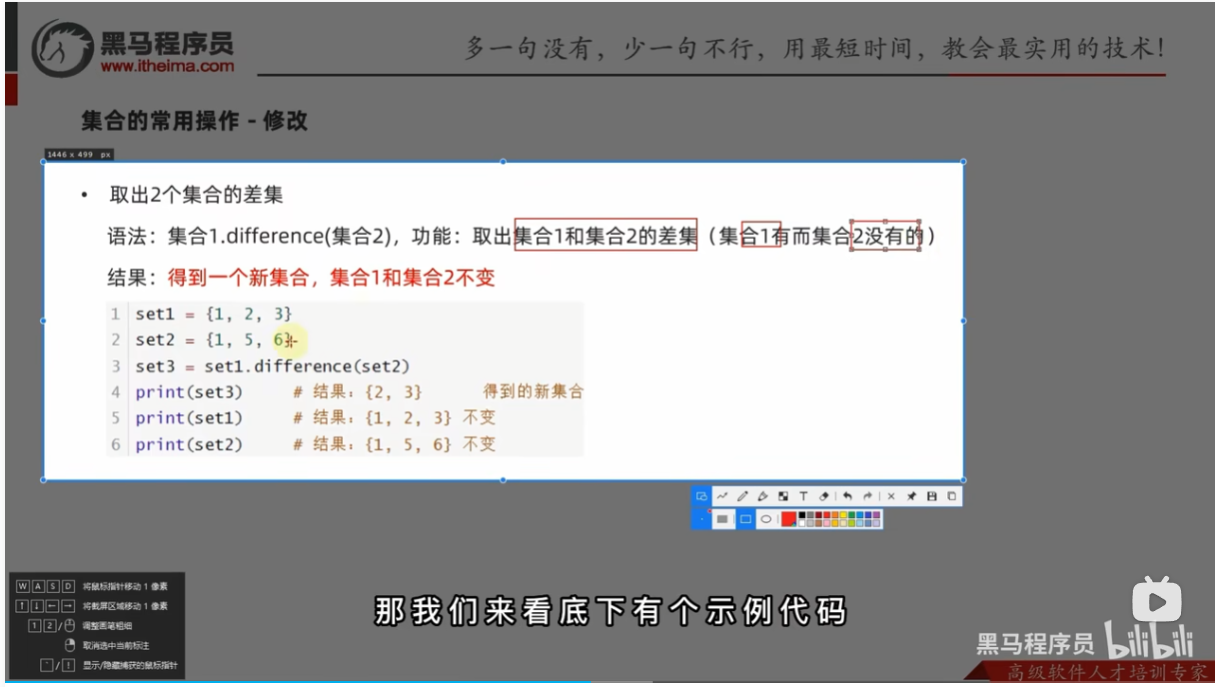
- 消除2个集合的差集
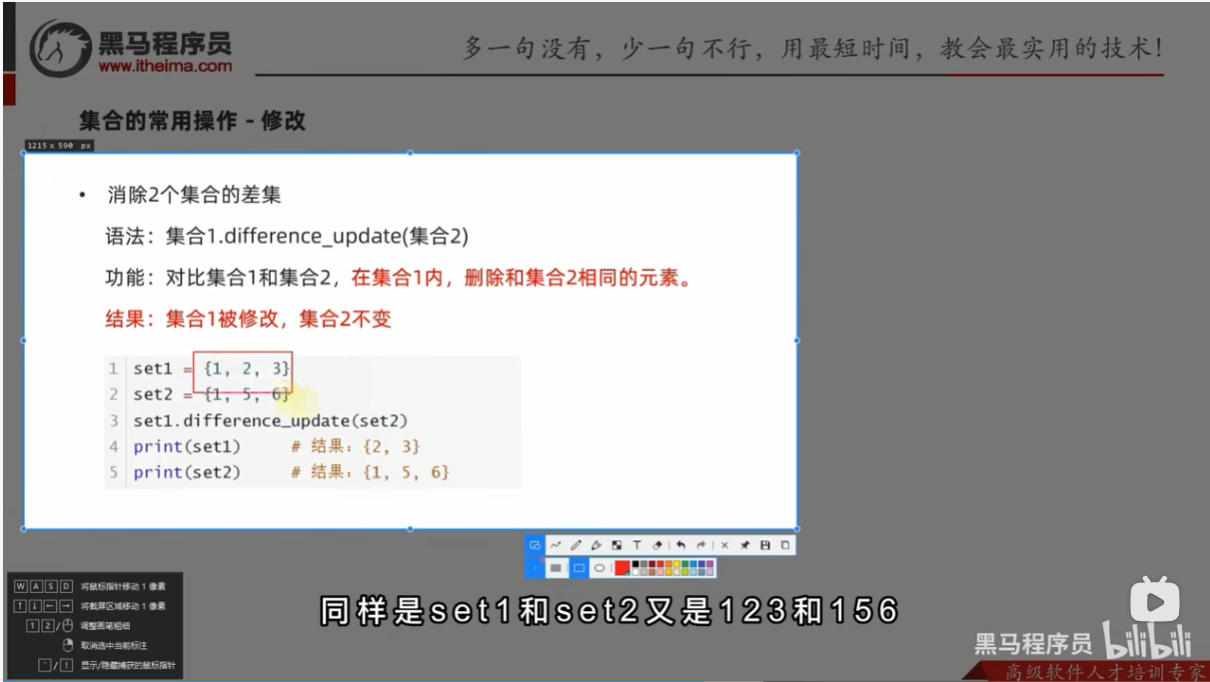
- 合并
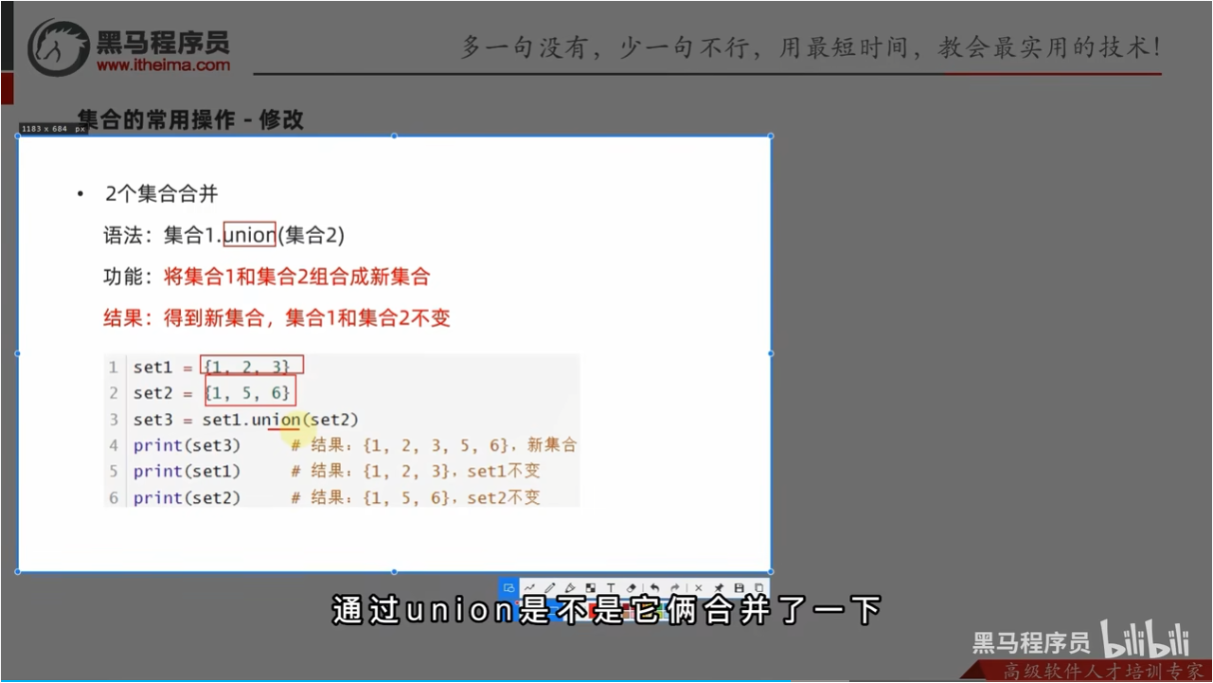
集合常用功能

集合的特点
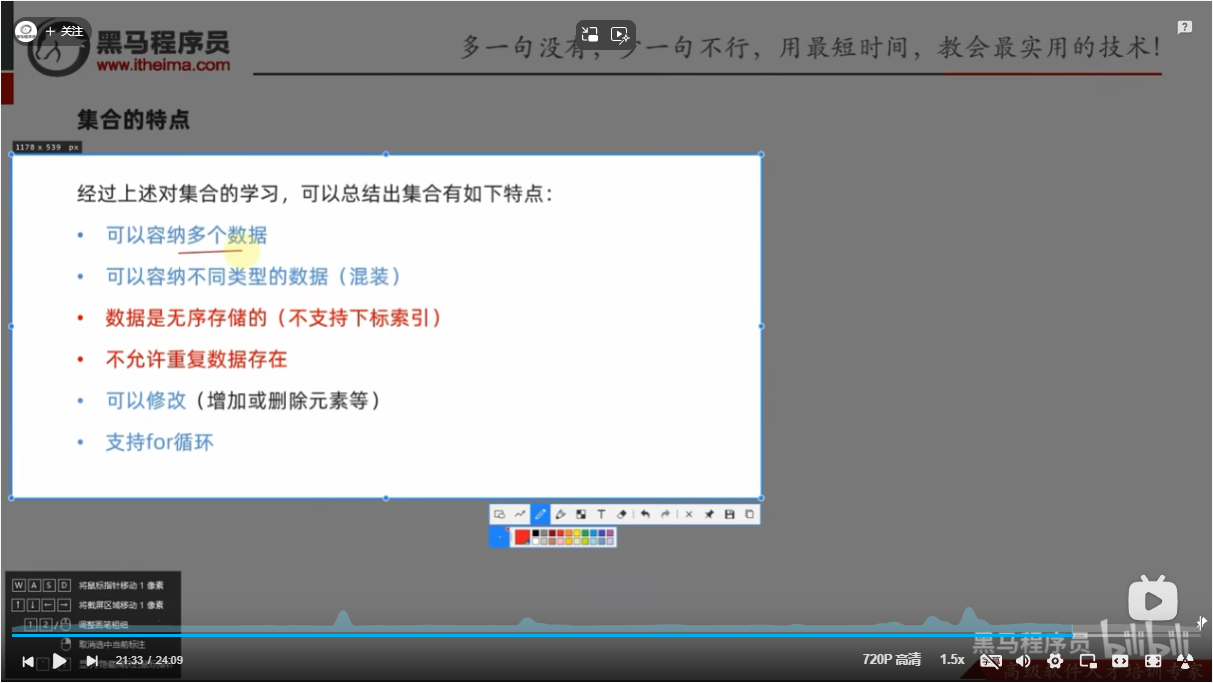
总结
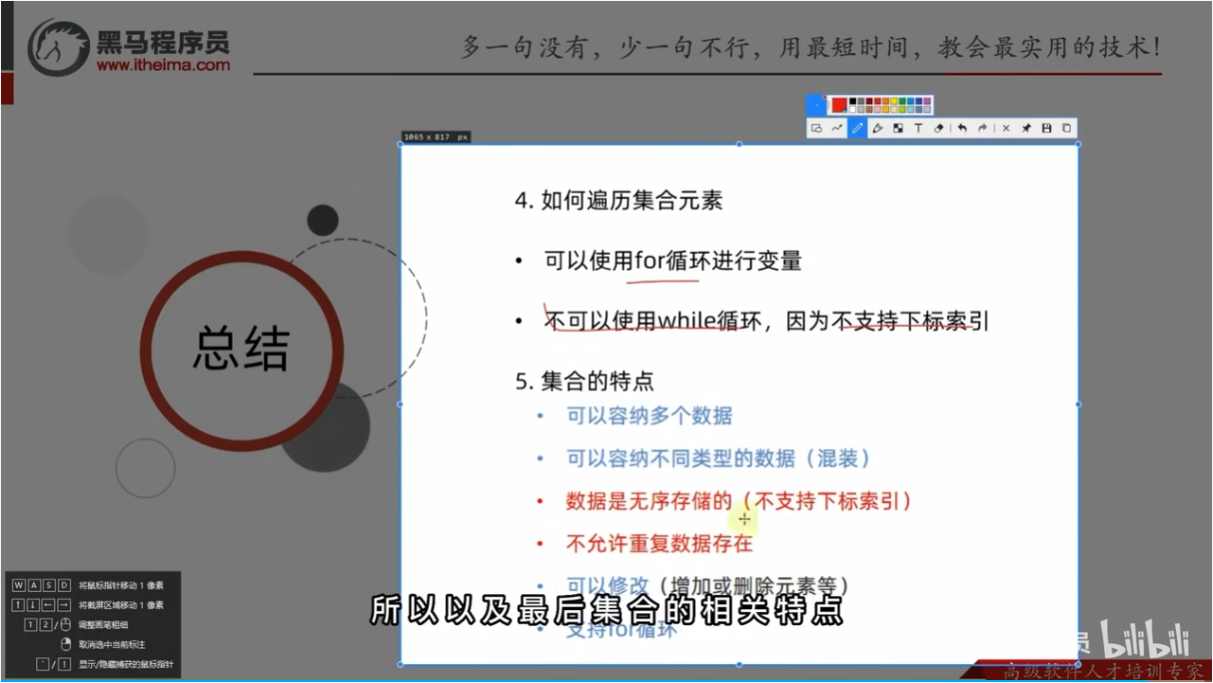
"""
信息去重
"""
my_list = ['黑马程序员','传智播客','黑马程序员','传智播客',
'itheima','itcast','itheima','itcast','best']
# 定义一个空集合
my_set = set()
for element in my_list:
# 直接将元素 element 添加到集合中,而不是将它包装在一个新的集合里
my_set.add(element)
print(f"有列表{my_list}")
print(f"存入集合后的结果:{my_set}")
数据容器-字典
字典的定义
为什么使用字典?

字典的定义
存储的元素:键值对
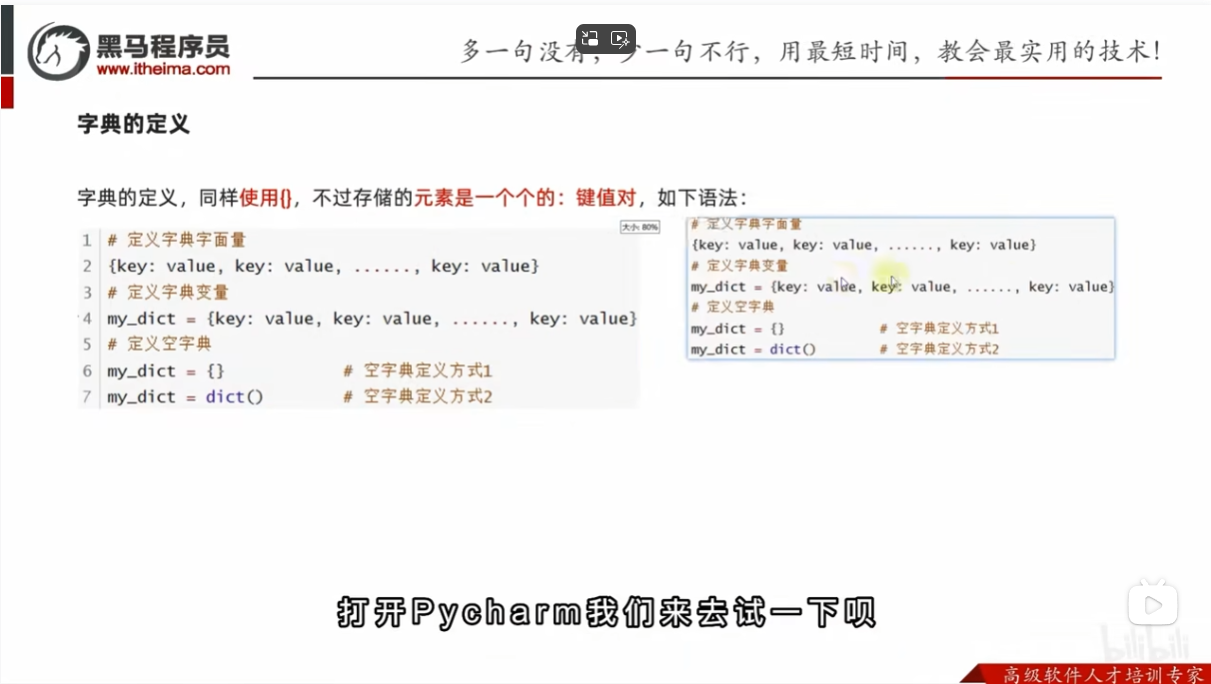
字典数据的获取

字典的嵌套
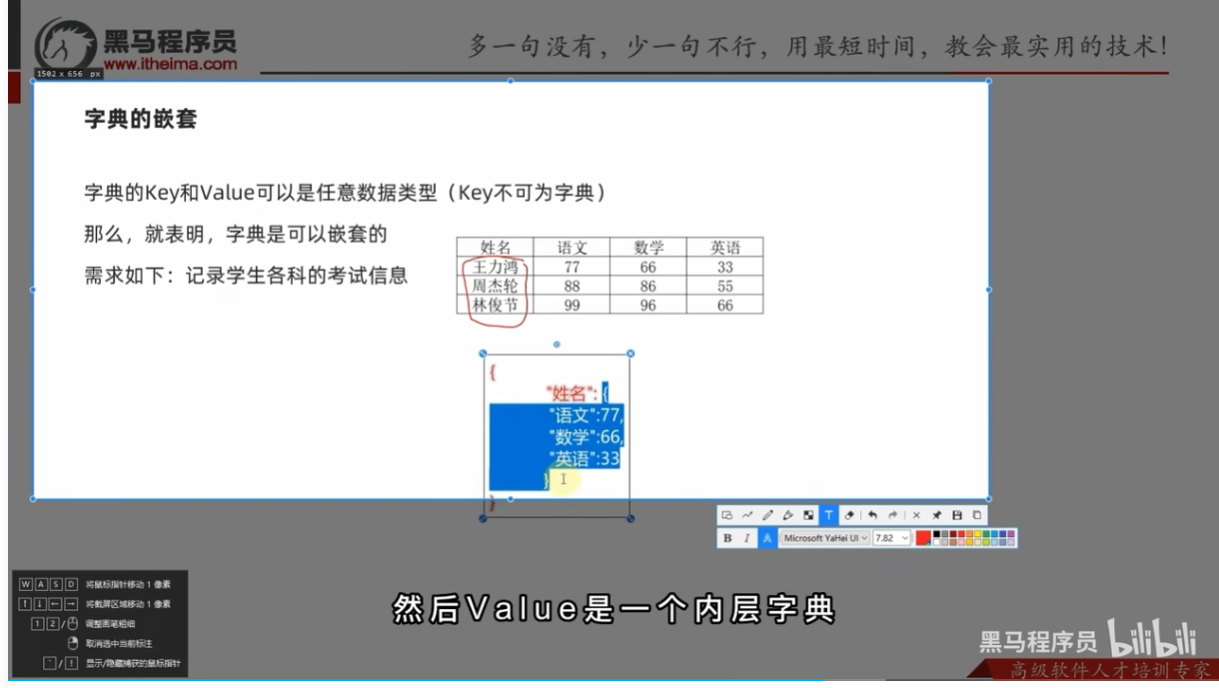
总结
字典的key不可以重复
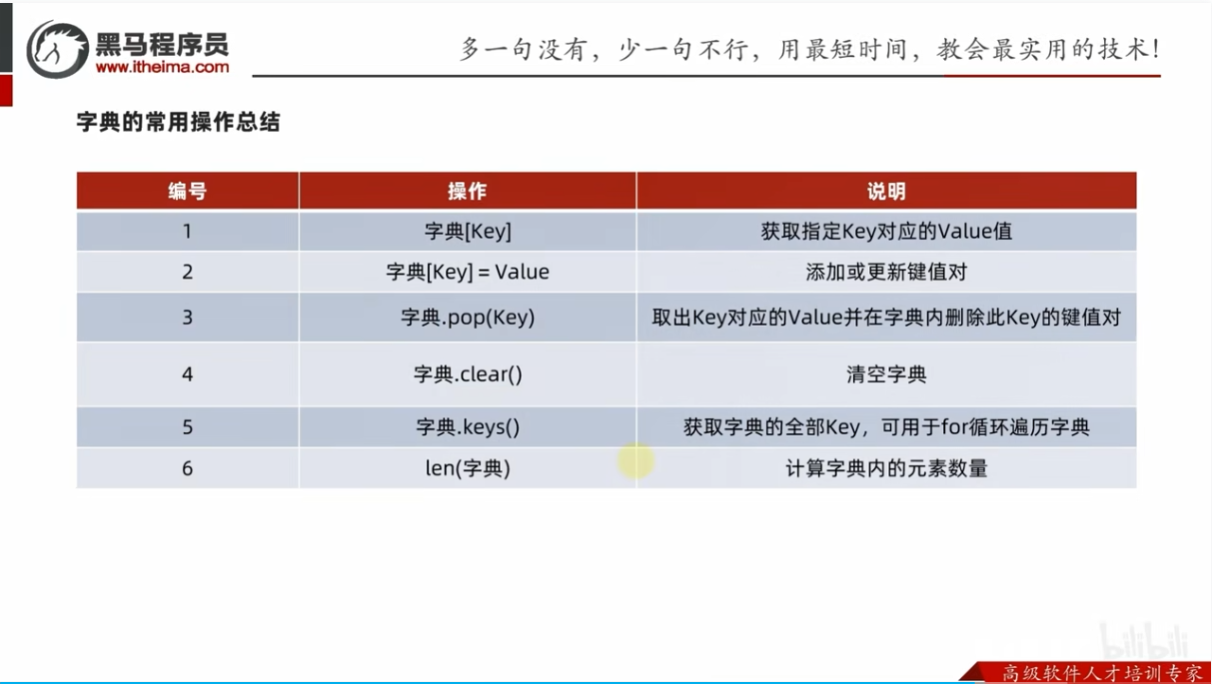
字典的常用操作
常用操作
"""
演示字典的常用操作
"""
my_dict1 = {"王力宏": 99, "周杰伦": 88, "林俊杰": 77}
# 新增元素 字典.[key] = [value]
my_dict1["张信哲"] = 66
print(f"字典经过新增元素后,结果是:{my_dict1}")
# 更新元素 新增和更新两者语法一样,主要看key的值
my_dict1["周杰伦"] = 32
print(f"字典经过新增元素后,结果是:{my_dict1}")
# 删除元素 字典.pop()
score = my_dict1.pop("周杰伦")
print(f"字典移除了一个元素后,结果是:{my_dict1},周杰伦的考试分数是{score}")
# 清空元素 clear
my_dict1.clear()
print(f"字典被清空了,内容是{my_dict1}")
# 获取全部的key 字典.keys()
my_dict1 = {"王力宏": 99, "周杰伦": 88, "林俊杰": 77}
keys = my_dict1.keys()
print(f"字典的全部keys,是{keys}")
# 遍历字典:只支持for循环
# 方式1:通过获取全部的key来完成遍历 也就是先 获取全部的key,再用for循环遍历这个全部的keys
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict1[key]}")
# 方式2 :直接对字典进行for循环,每一次循环都是直接得到key
for key in my_dict1:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict1[key]}")
# 统计字典内的元素数量,len()函数
num = len(my_dict1)
print(f"字典中的元素数量有:{num}个")
字典的特点
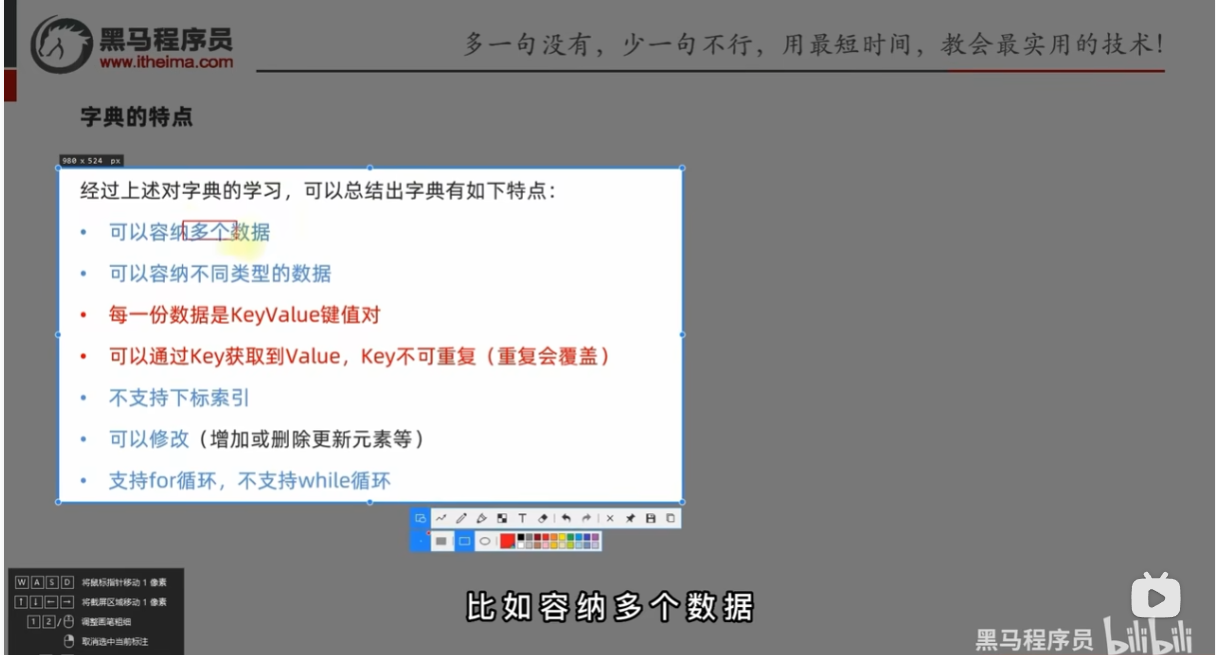
练习 没怎么懂,自己写的时候逻辑不清
"""
升职加薪
"""
All_dict = {
"王力宏":{
"部门":"科技部",
"工资":3000,
"级别":1
},"周杰伦":{
"部门":"市场部",
"工资":5000,
"级别":2
},"林俊杰":{
"部门":"市场部",
"工资":6000,
"级别":3
},"张学友":{
"部门": "科技部",
"工资": 4000,
"级别": 1
},"刘德华":{
"部门": "市场部",
"工资": 6000,
"级别": 2
}
}
print(f"全体员工当前信息如下:{All_dict}")
# for key in All_dict:
# employee = All_dict[key]
# if employee["级别"] ==1:
# employee["工资"] += 1000
# print(f"全体员工{key}级别为1的员工完成升职加薪操作,操作后{employee}")
# for循环遍历字典
for name in All_dict:
# if条件判断符合条件员工
if All_dict[name]["级别"] == 1:
# 升职加薪操作
# 获取到员工的信息字典
employee_All_dict = All_dict[name] #得到一个新的字典,本身意味着可以用语法 字典.[] 获取key
# 修改员工的信息
employee_All_dict ["级别"] = 2
employee_All_dict ["工资"] += 1000
# 将员工的信息更新回All_dict
All_dict[name] = employee_All_dict
# 输出结果
print(f"对员工升职加薪后的结果是{All_dict}")
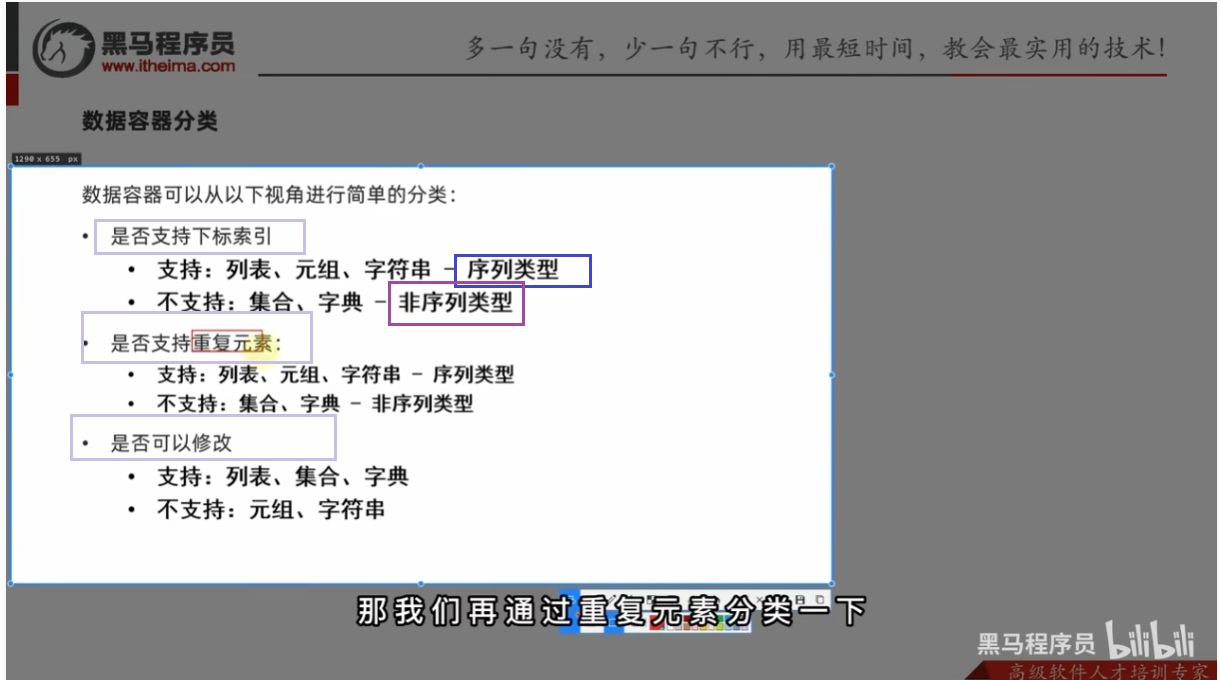
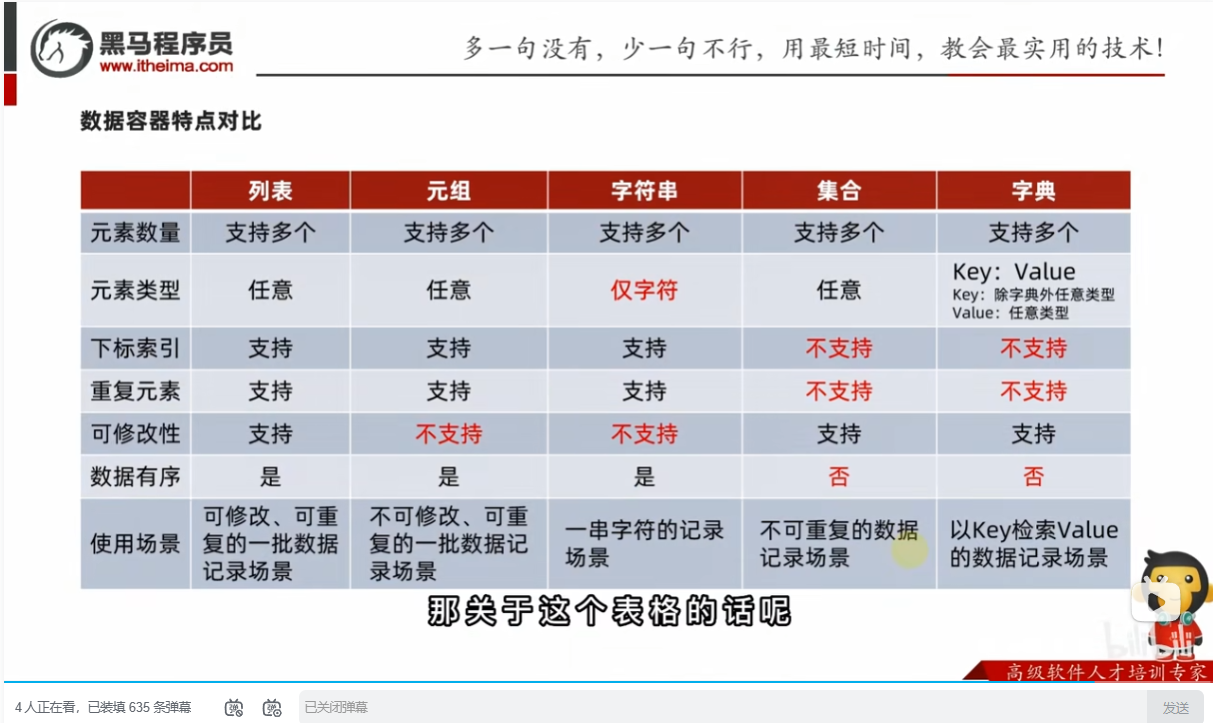
五类数据容器的总结对比
列表与字典的区别
🔹 取值方式不同
-
列表 用 索引 取值(位置)
-
字典 用 键 取值(key)
“`python
my_list = [“Python”, “Java”, “C++”]
print(my_list[1]) # Java (索引取值)
my_dict = {“语言”: “Python”, “版本”: 3.10}
print(my_dict[“语言”]) # Python (键取值)
“`
| 列表(List) | 字典(Dict) |
| ———— | ————– |
| 按索引存取 | 按键存取 |
| 存的是一组值 | 存的是键值对 |
| 数据有序 | 键值对有序 |
| 适合存相似项 | 适合存关联数据 |
数据容器特点对比
数据容器的通用操作
- 遍历
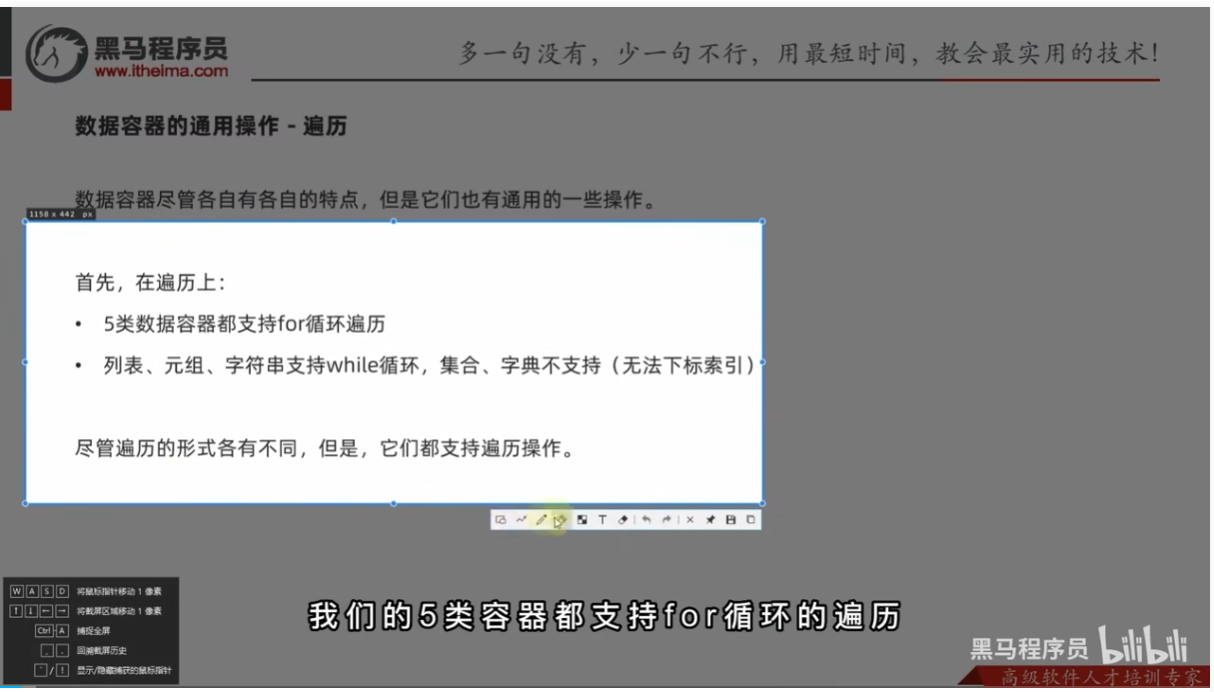
- 通用统计功能
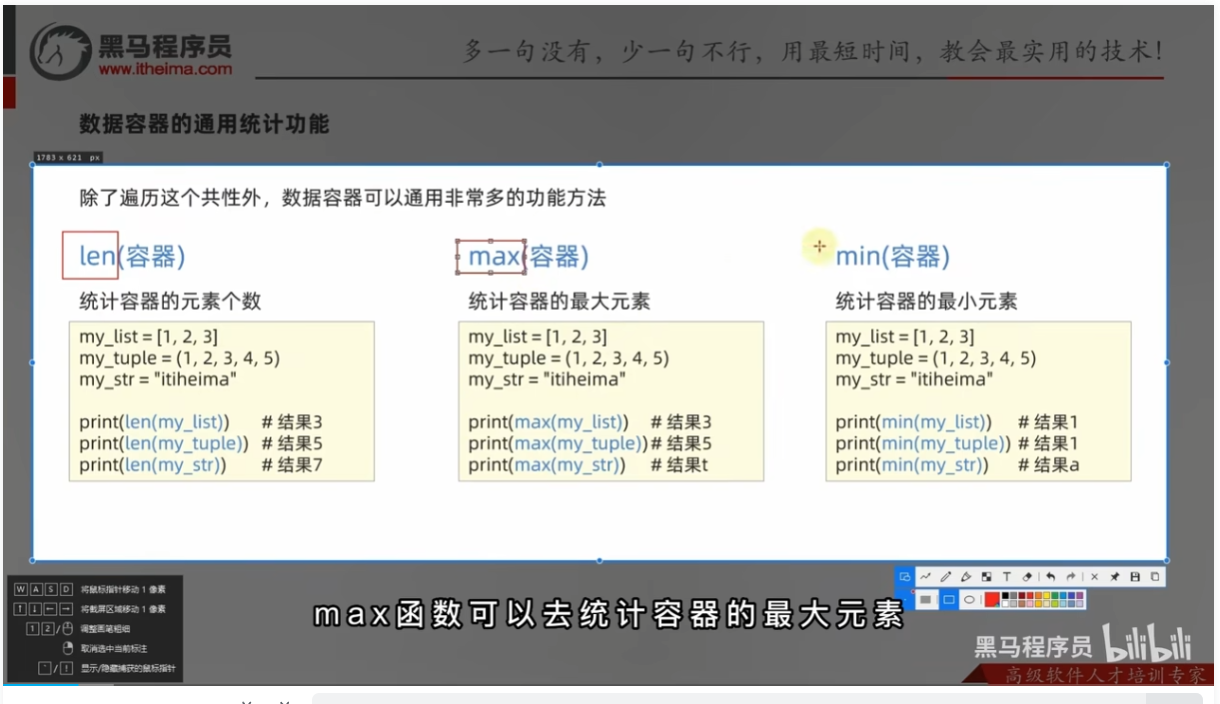
- 通用容器转换功能

- 容器通用排序功能
sorted(序列,[reverse=ture])其中reverse是翻转的意思,也就是选择反向。
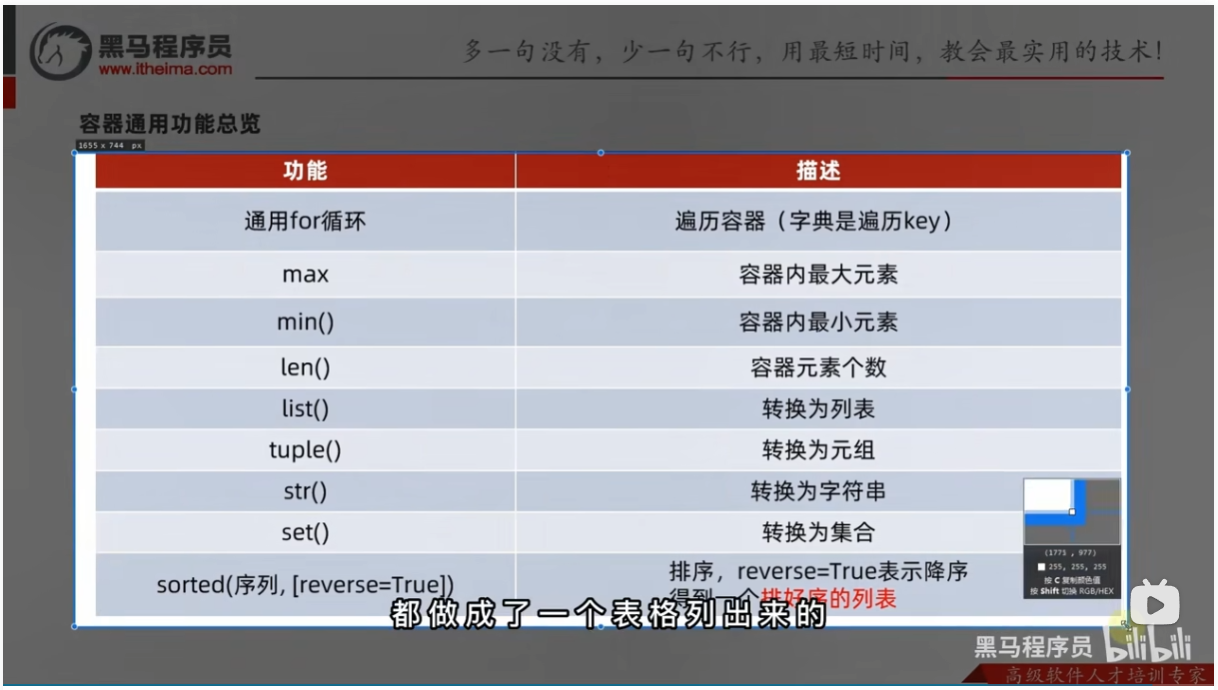
容器通用功能总览
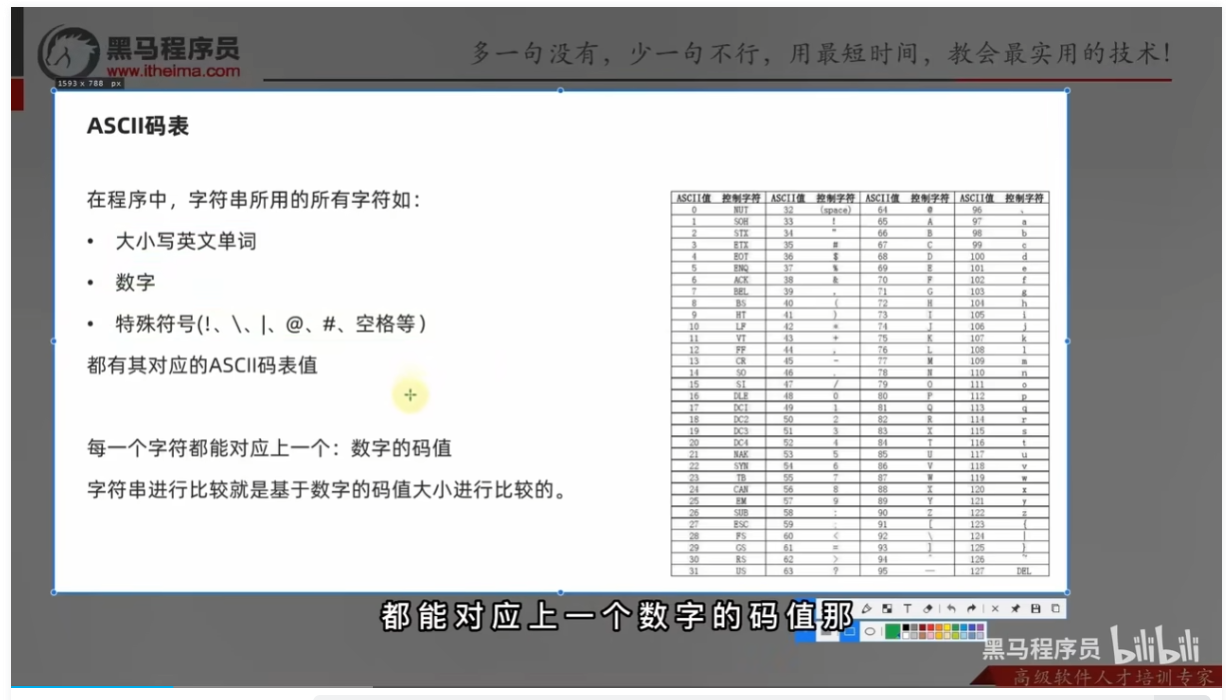
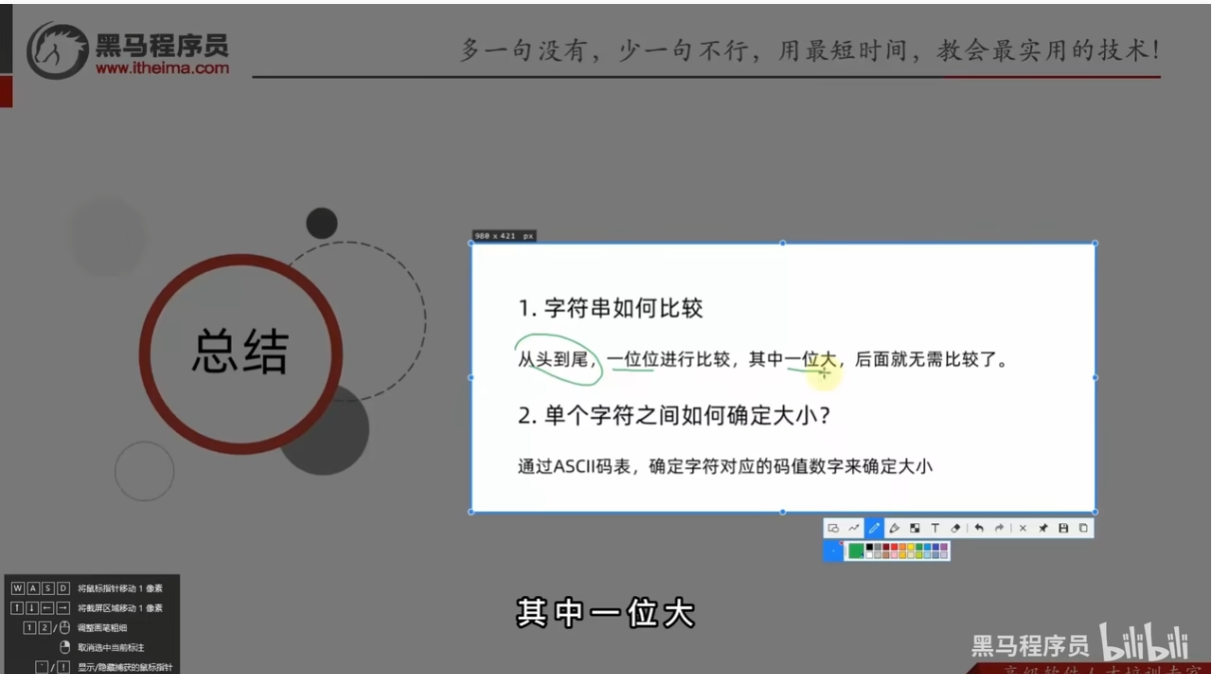
拓展-字符串大小比较的方式
ASCII码表
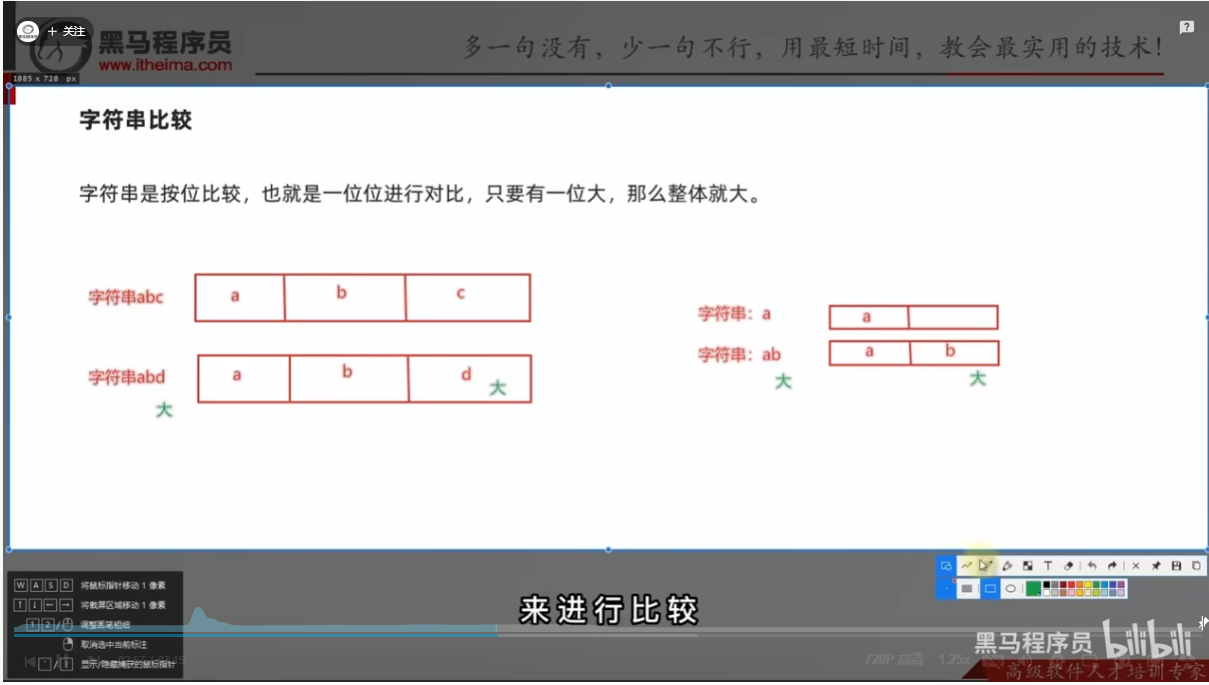
按位比较,一位一位进行对比,只要有一位大,那么整体就大
总结
python函数进阶
函数的多返回值
多个返回值是什么
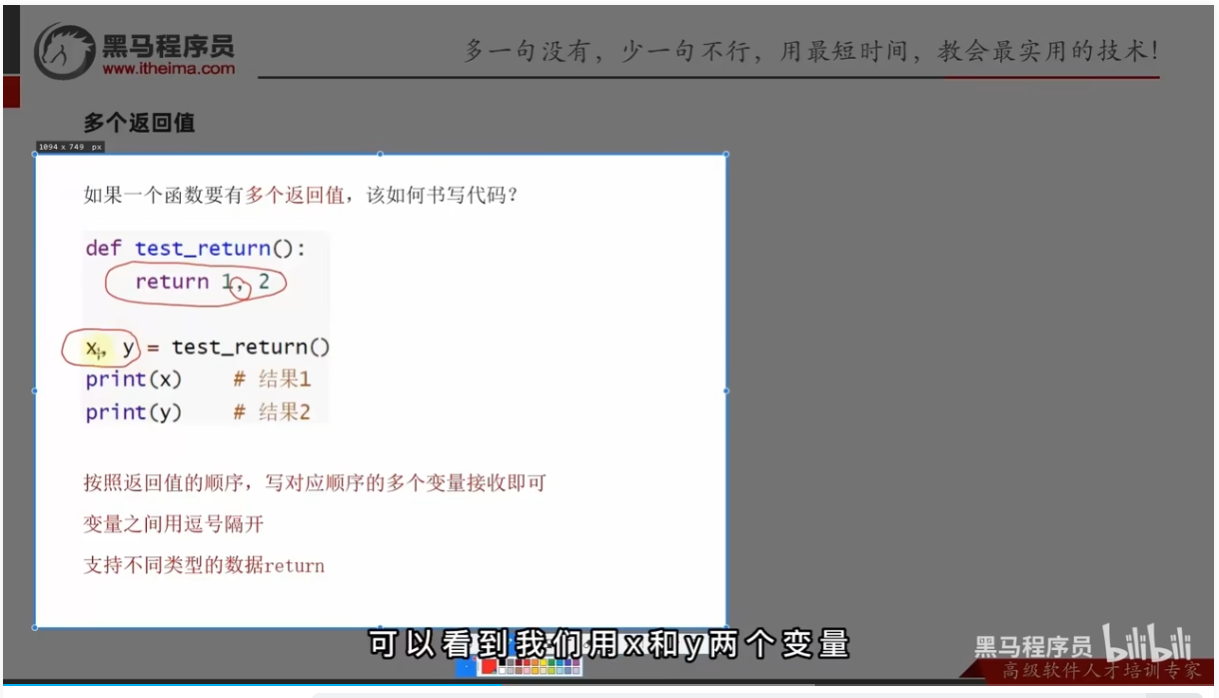
返回值可以是不同的类型
函数的多种传参方式
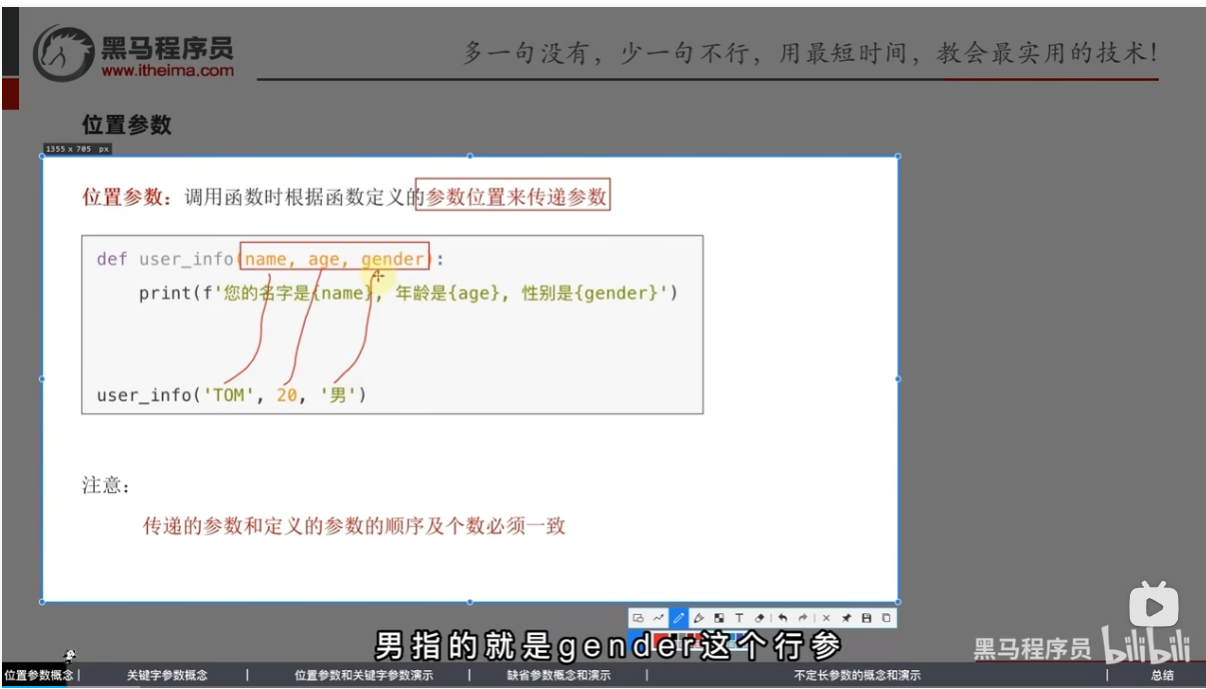
位置参数
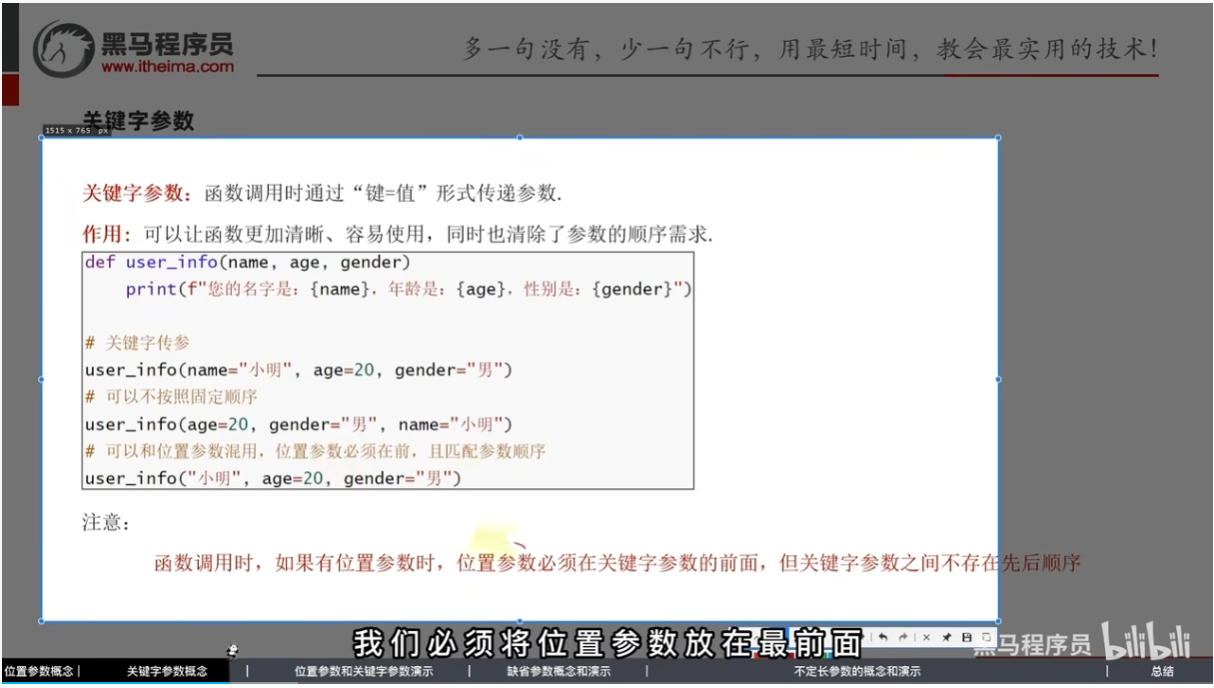
关键字参数
缺省参数
传递参数时,可以设置默认值
注意:默认值统一放到最后

不定长参数
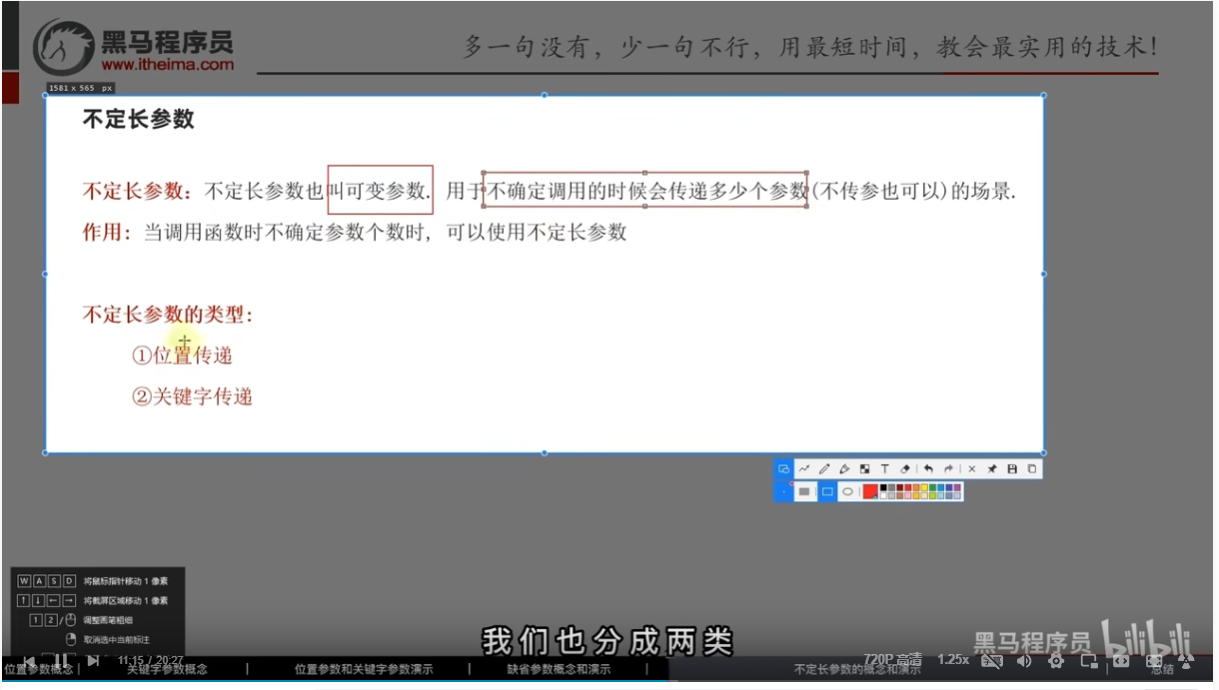
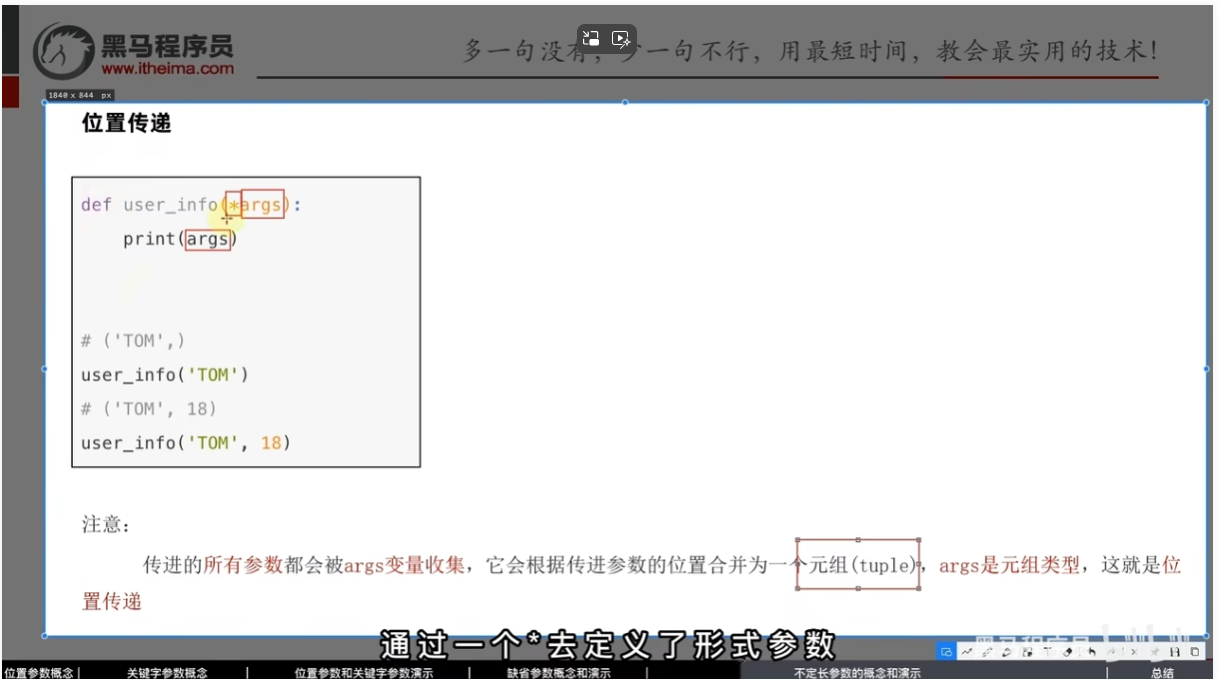
- 位置传递
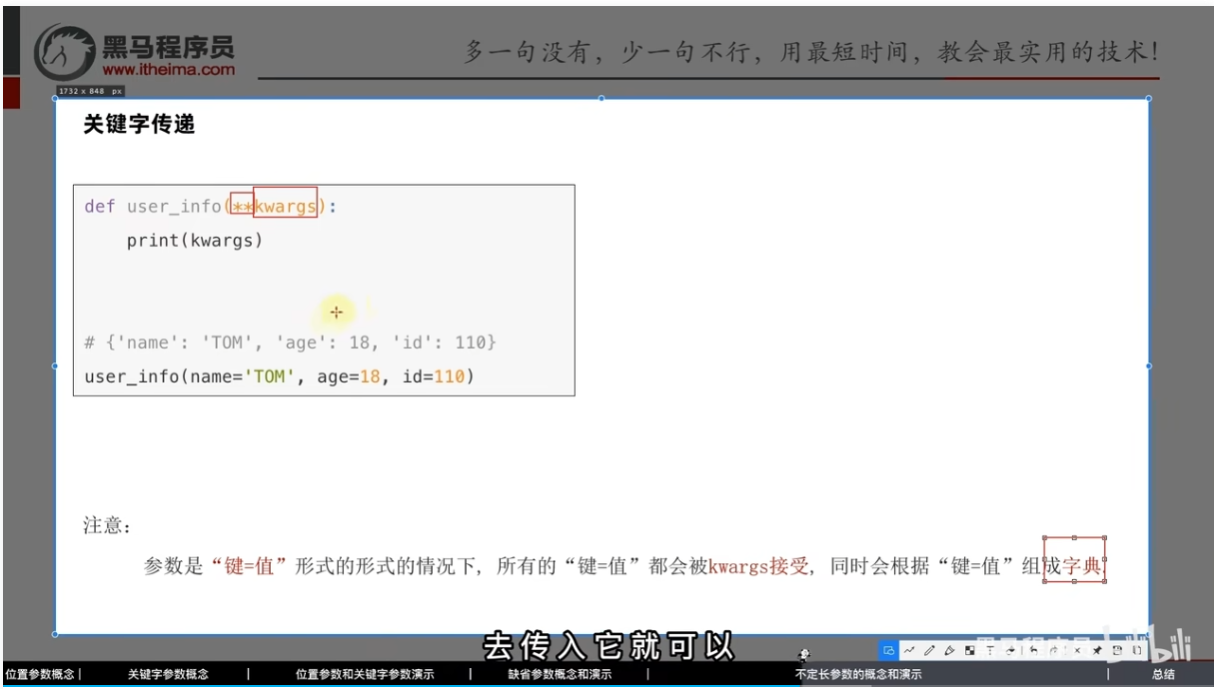
- 关键字传递
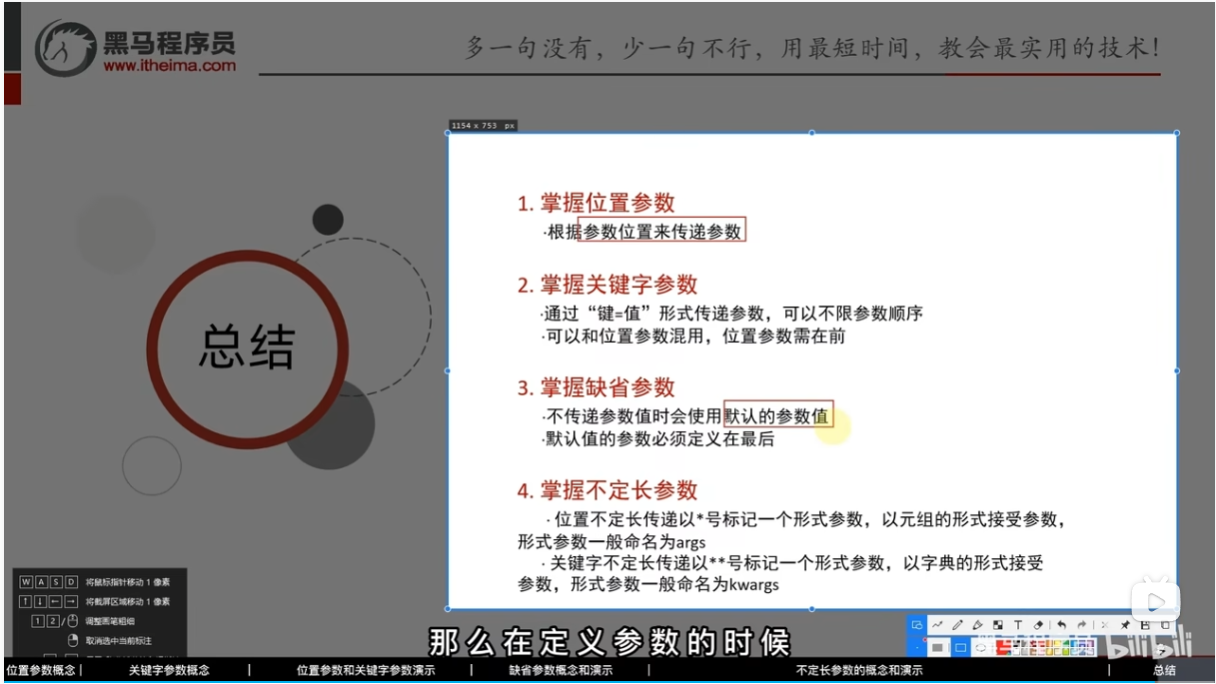
总结
匿名函数
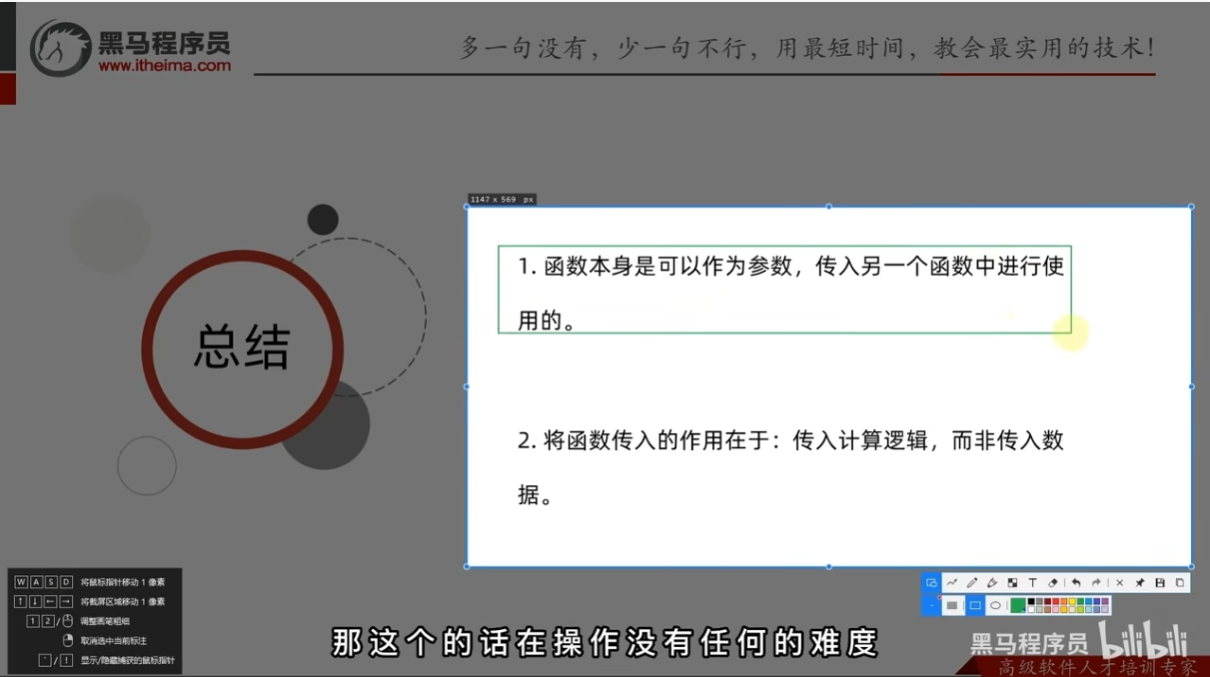
函数作为参数传递
注意:是传入的逻辑,而不是传入的数据
总结
lambda匿名函数
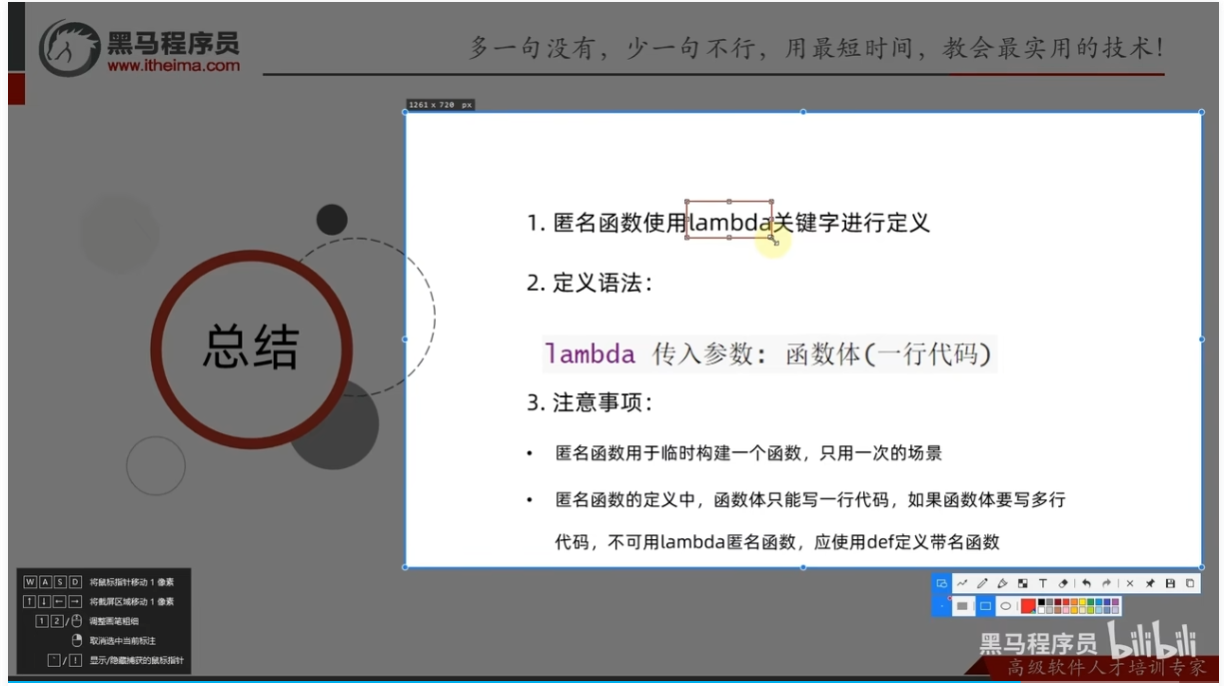
定义
lambda就是一次性函数,用完就没法再调用了

示例
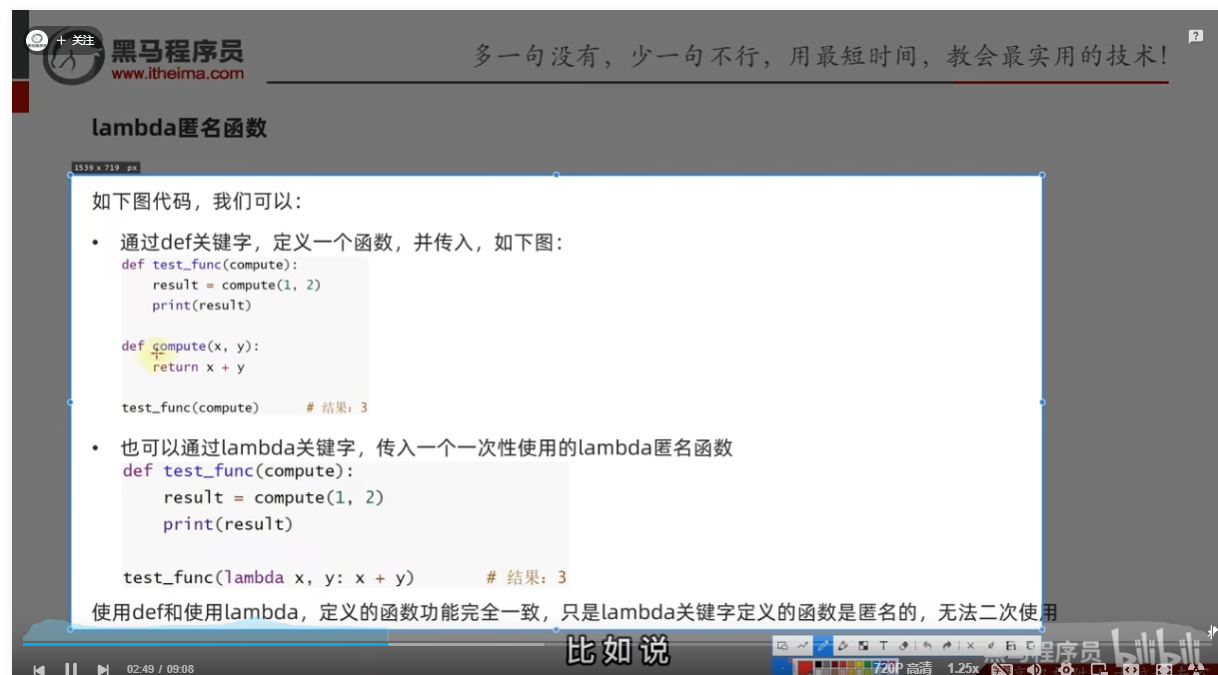
注意:只支持一行代码
总结
python文件操作
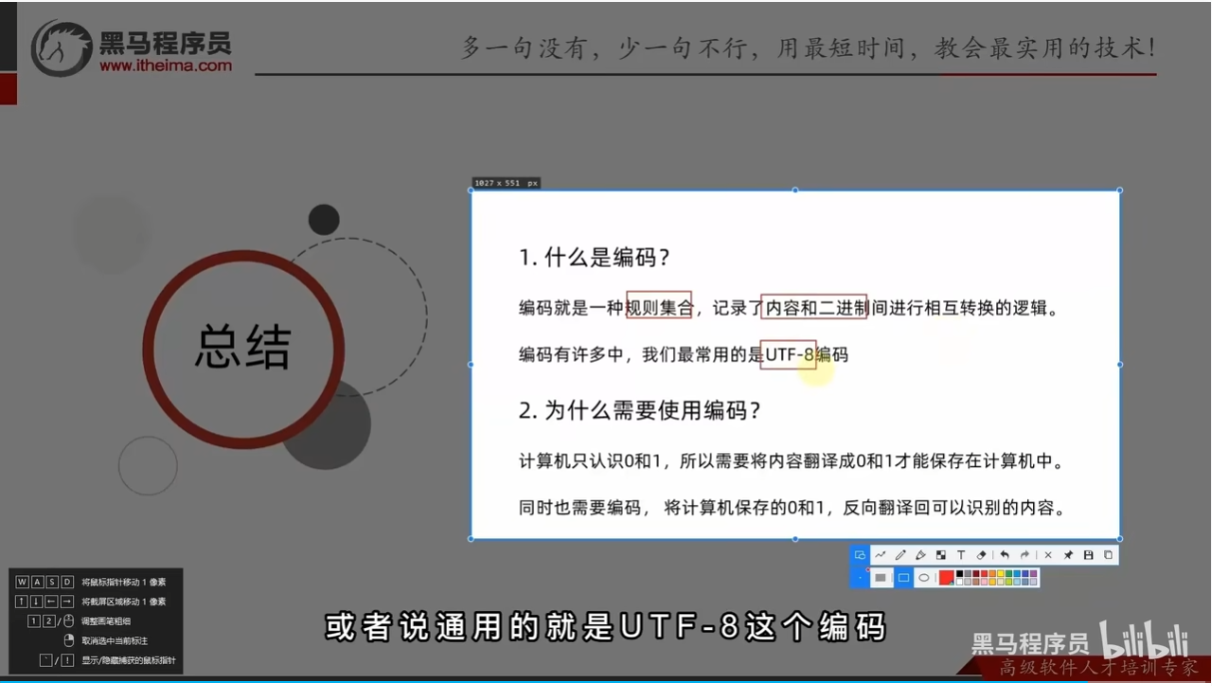
文件编码概念
编码技术

UTF-8是目前全球通用的编码格式
除非有特殊需求,否则,一律以UTF-8进行文件编码即可
总结
文件读取操作
什么是文件?
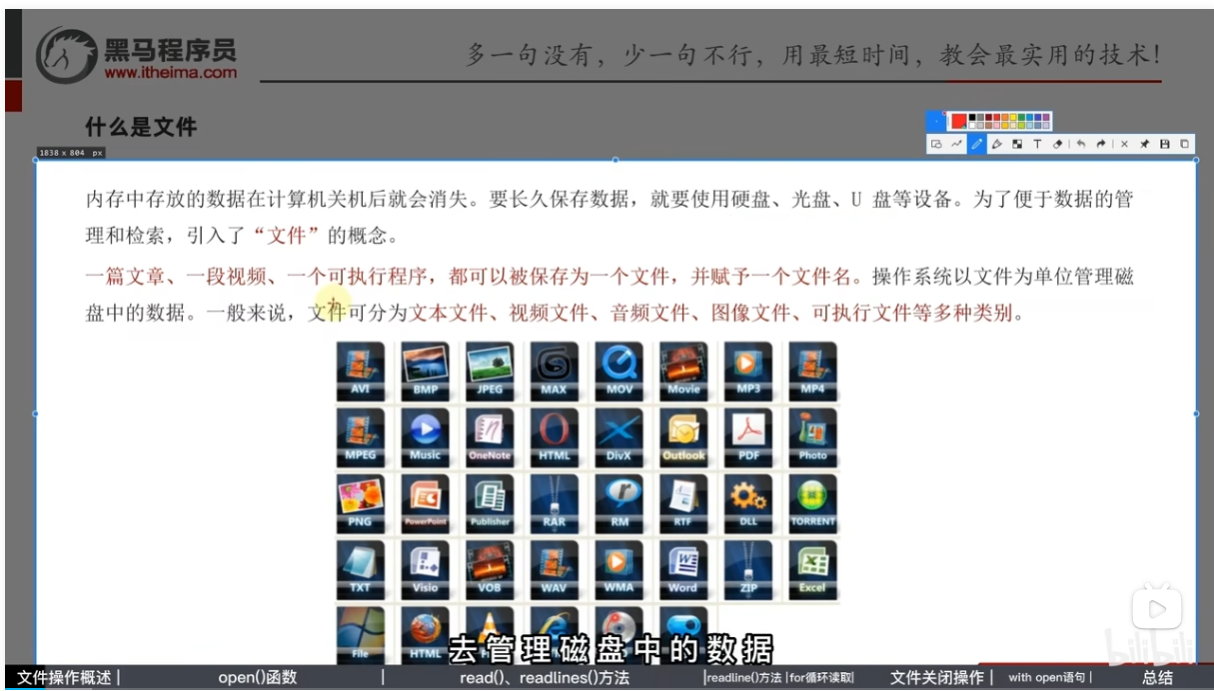
文件操作:打开、关闭、读、写
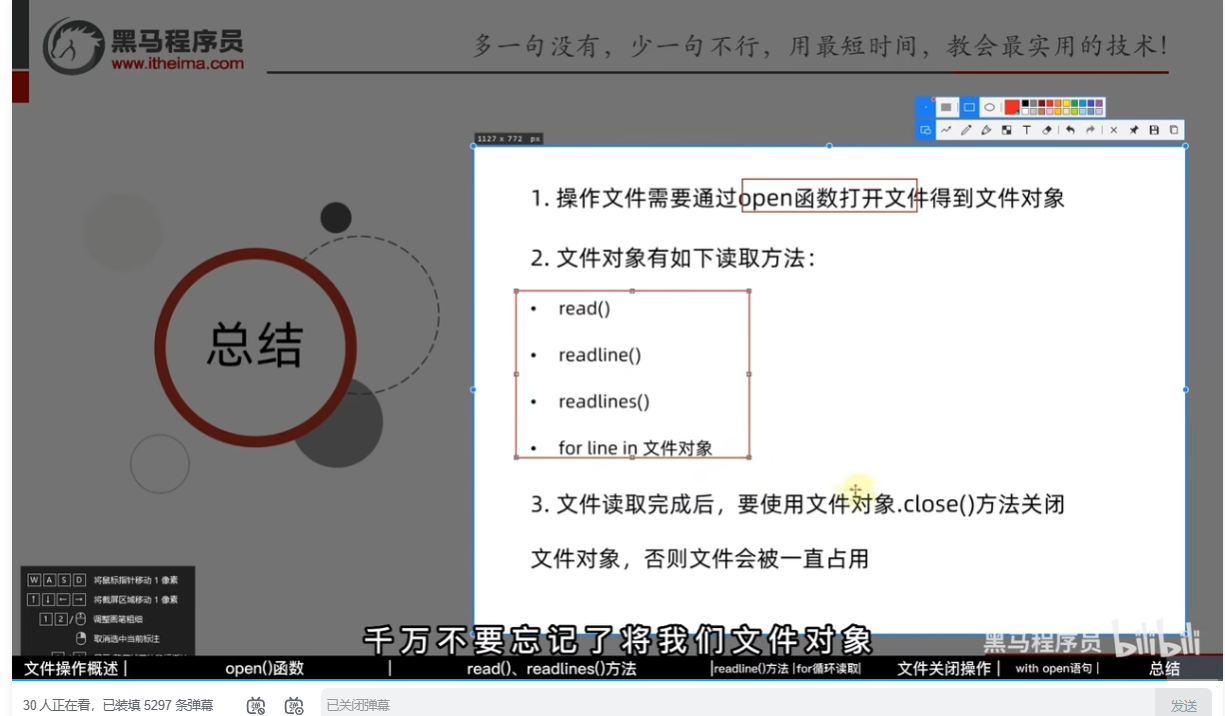
文件的操作步骤

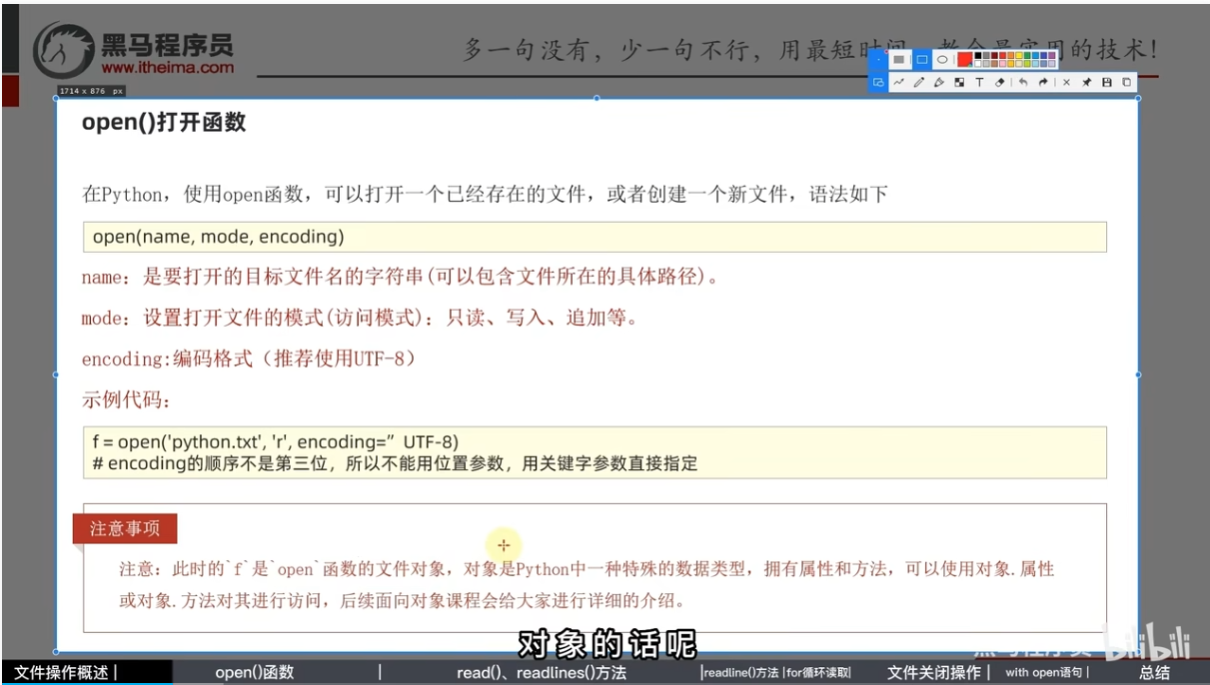
- open()打开文件
- 读取操作
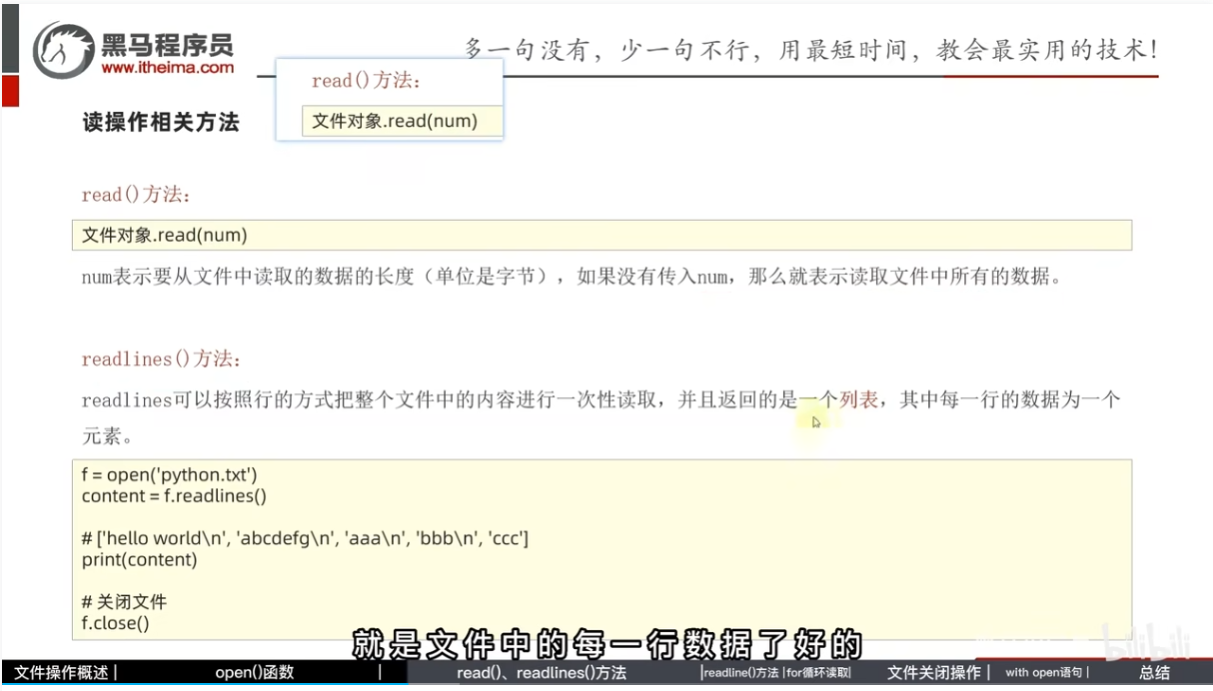
read()
readlines()
readlines()
for循环读取文件行
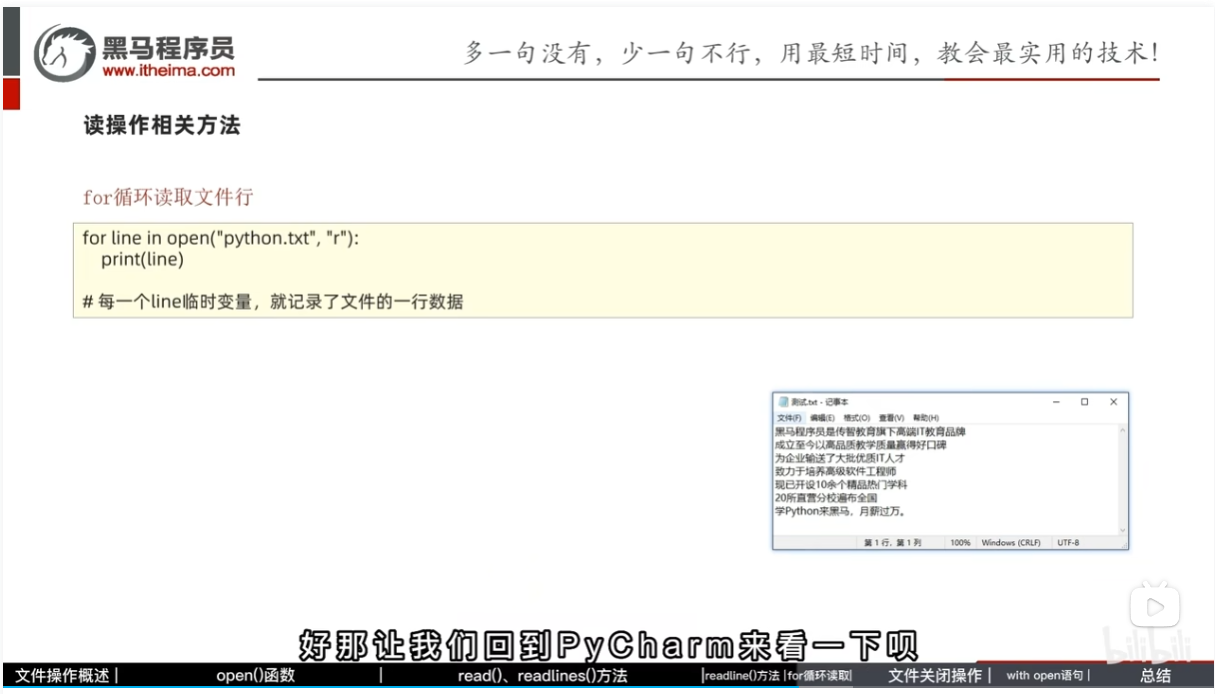
关闭文件对象 close()
with open() as f :
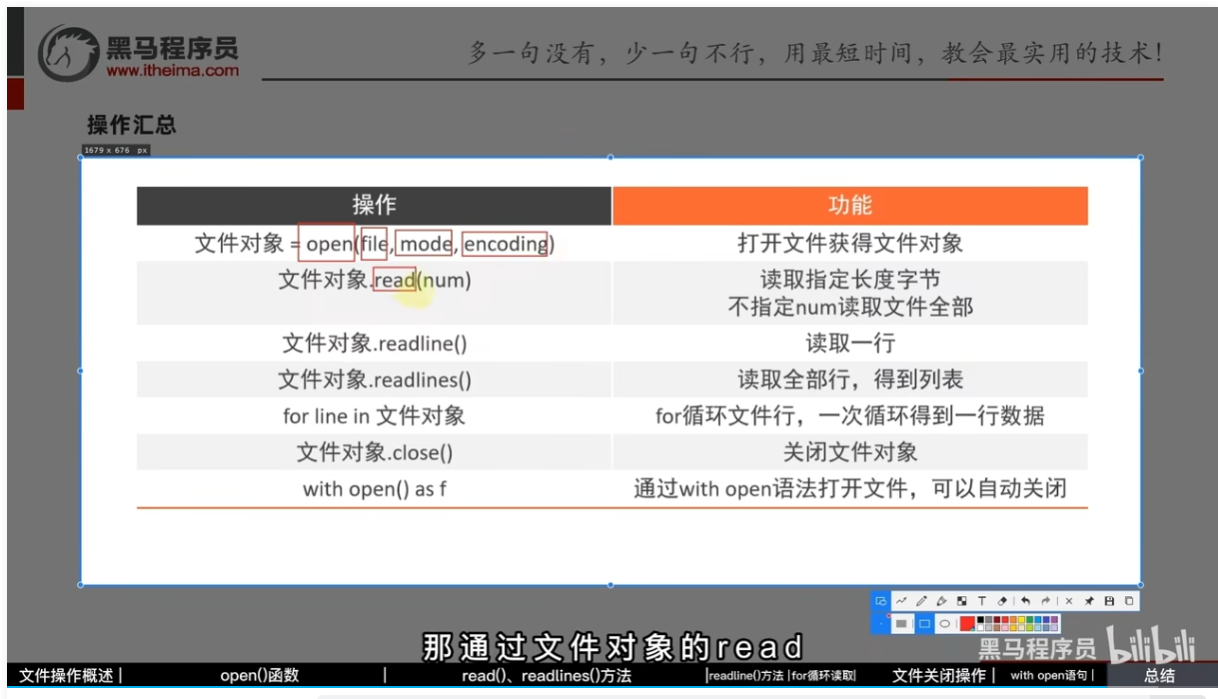
操作汇总
总结
文件读取的课后练习讲解
忘记count()用法
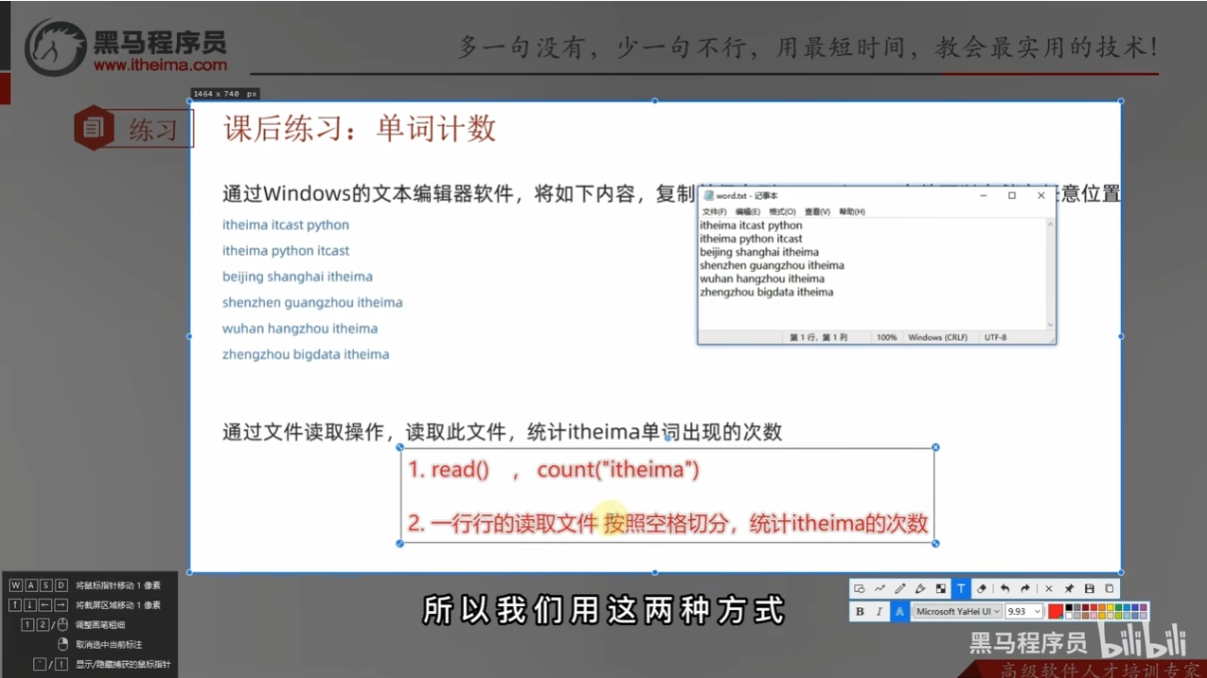
"""
单词计数
"""
f = open("E:/document/word.txt", "r", encoding="utf-8" )
# 方式1:读取内容,通过字符串count方法统计itheima单词数量
content = f.read()
count = content.count("itheima")
print(f"itheima在文件中出现了{count}次")
# 方式2:读取内容,一行一行读取
count = 0 # 使用count变量累计itheima出现的次数
for line in f:
line = line.strip() # 去除开头和结尾的空格以及换行符
words = line.split(" ")
for word in words:
if word == "itheima": # 如果单词是itheima,进行数量的累加加1
count += 1
print(f"itheima在文件中出现了{count}次")
文件的写出操作
写操作快速入门
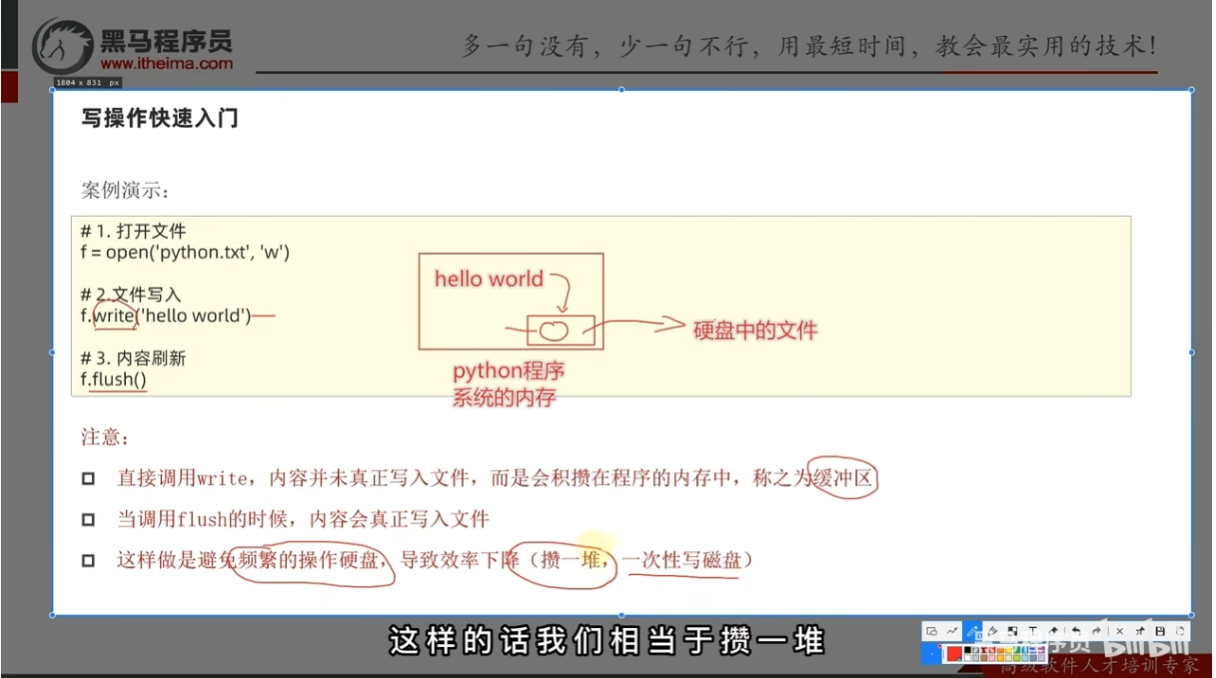
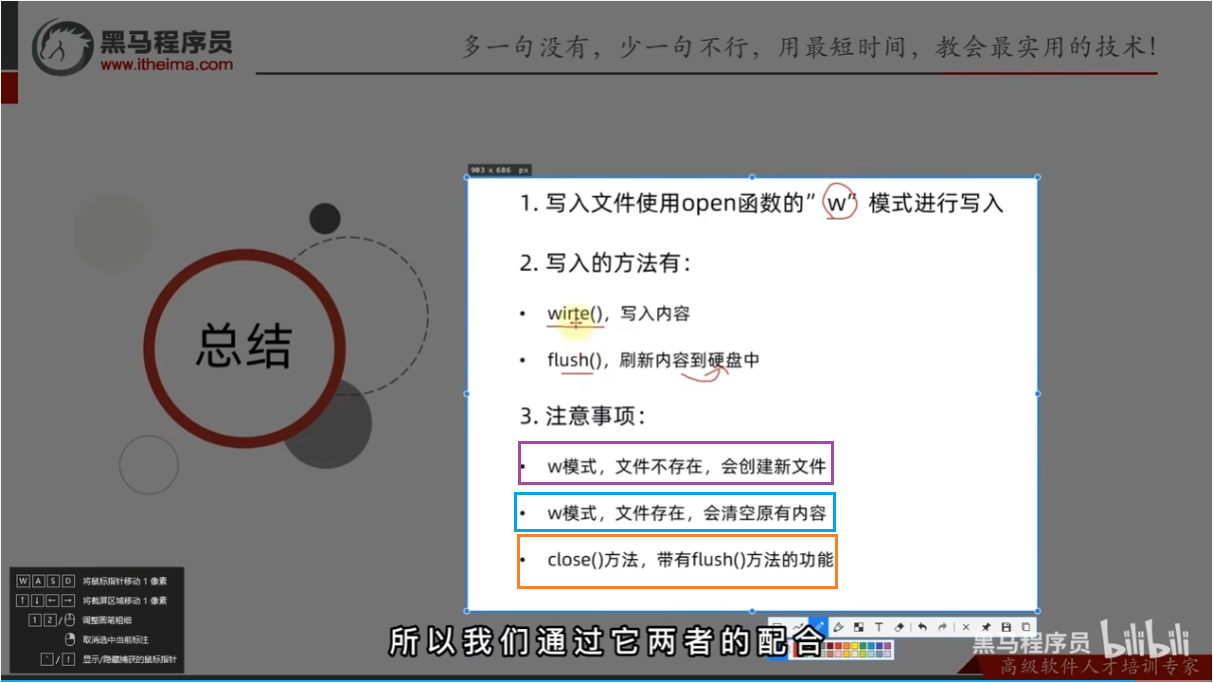
总结
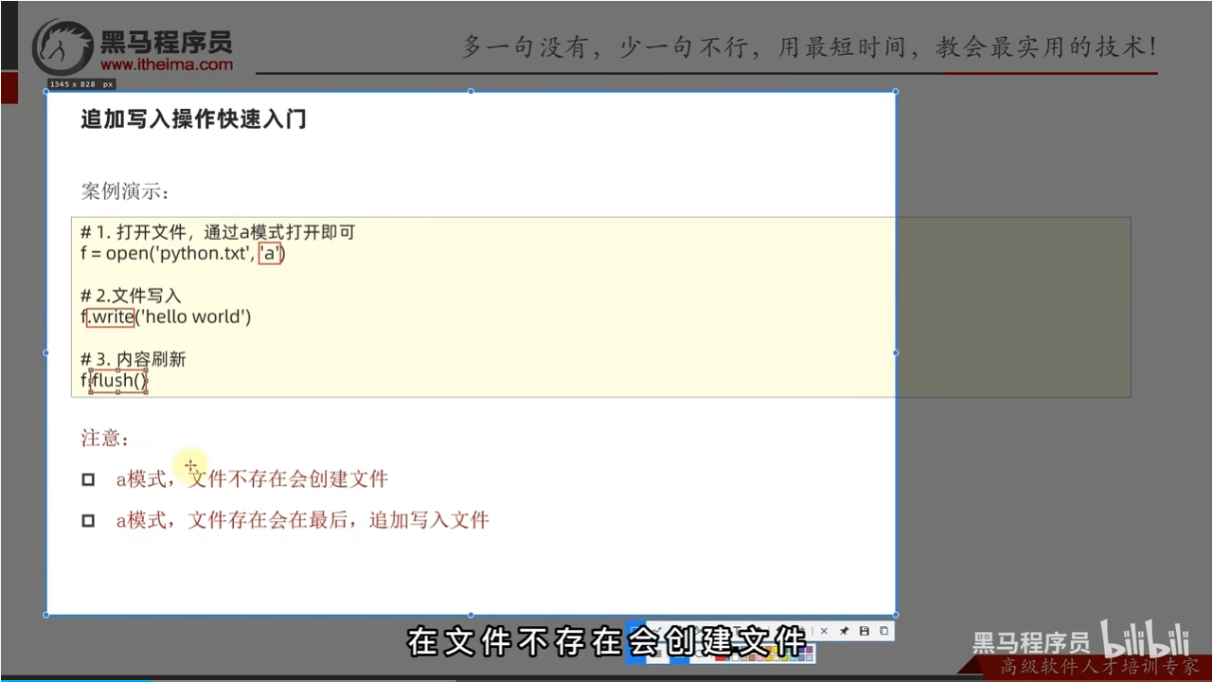
文件的追加写入操作
追加写入操作快速入门
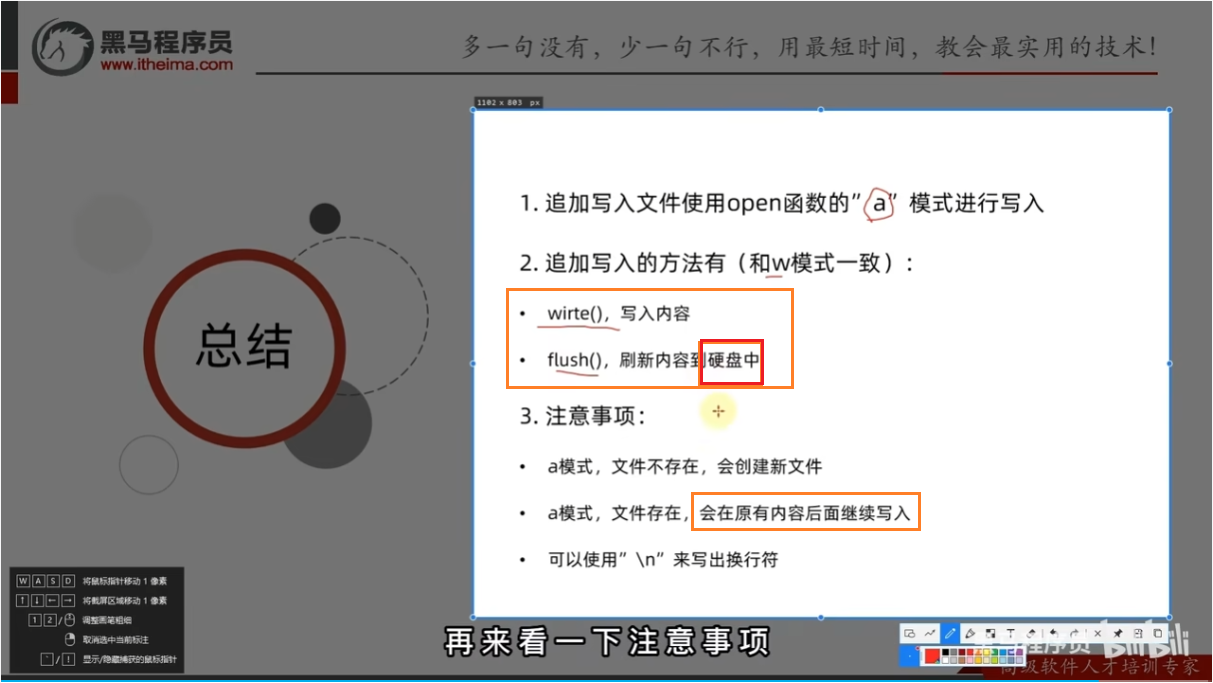
总结
文件操作的综合案例
spilt: 分隔字符串后,得到一个新的列表(字符串的分隔)
"""
文件的综合案例
"""
# 打开文件得到文件对象,准备读取
fr = open("E:/document/bill.txt","r", encoding="utf-8")
# 打开文件得到文件对象,准备写入
fw = open("E:/document/bill.txt.bak", "w", encoding="utf-8")
for line in fr:
line = line.strip()
# 判断内容,将满足的内容写出
if line.split(",")[4] == "测试":
continue # continue进入下一次循环,这一次后面的内容就跳过了
# 将内容写出去
fw.write(line)
# 由于前面对内容进行了strip()操作,所以要手动写出换行符‘
fw.write("\n")
# close 2个文件对象
fr.close()
fw.close()
python异常、模块与包
了解异常
程序运行出现错误
异常的捕获
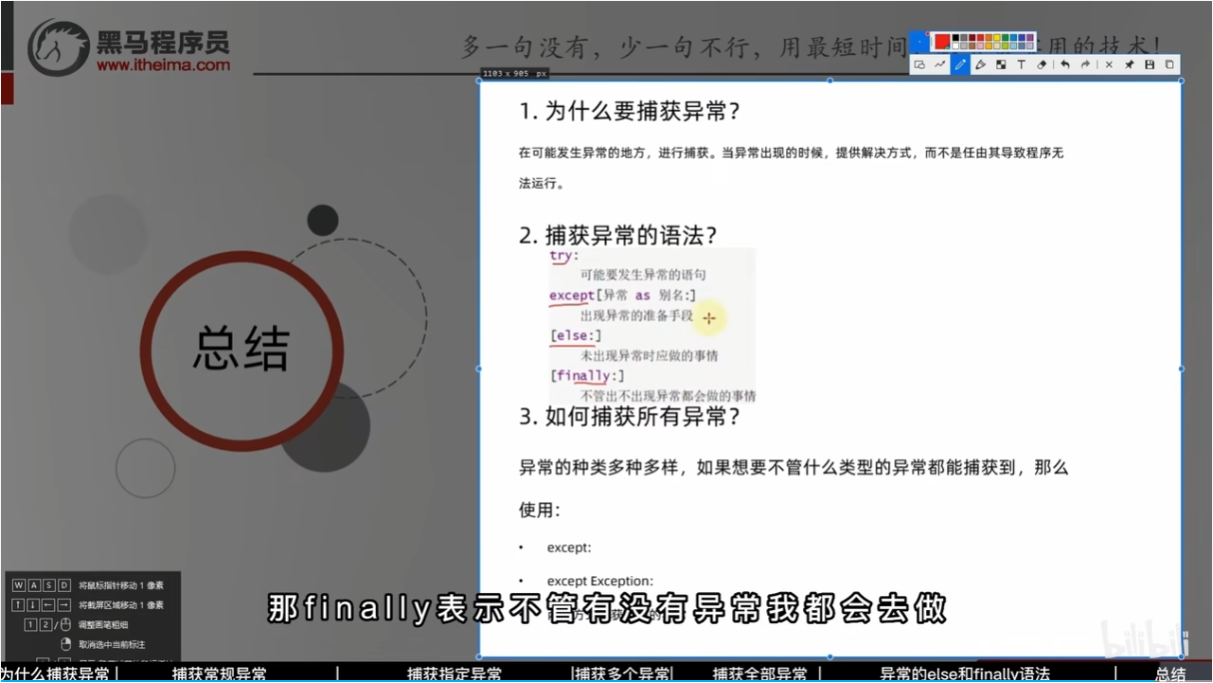
为什么要捕获异常?
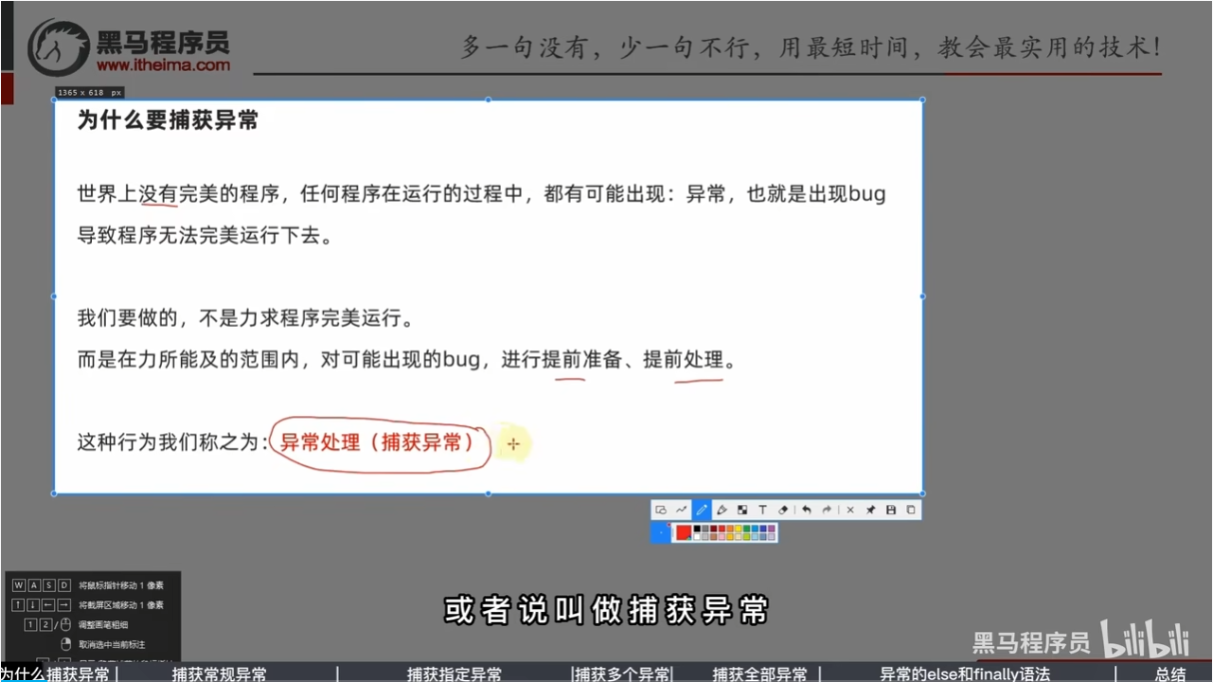
对bug进行提醒,整个程序继续进行
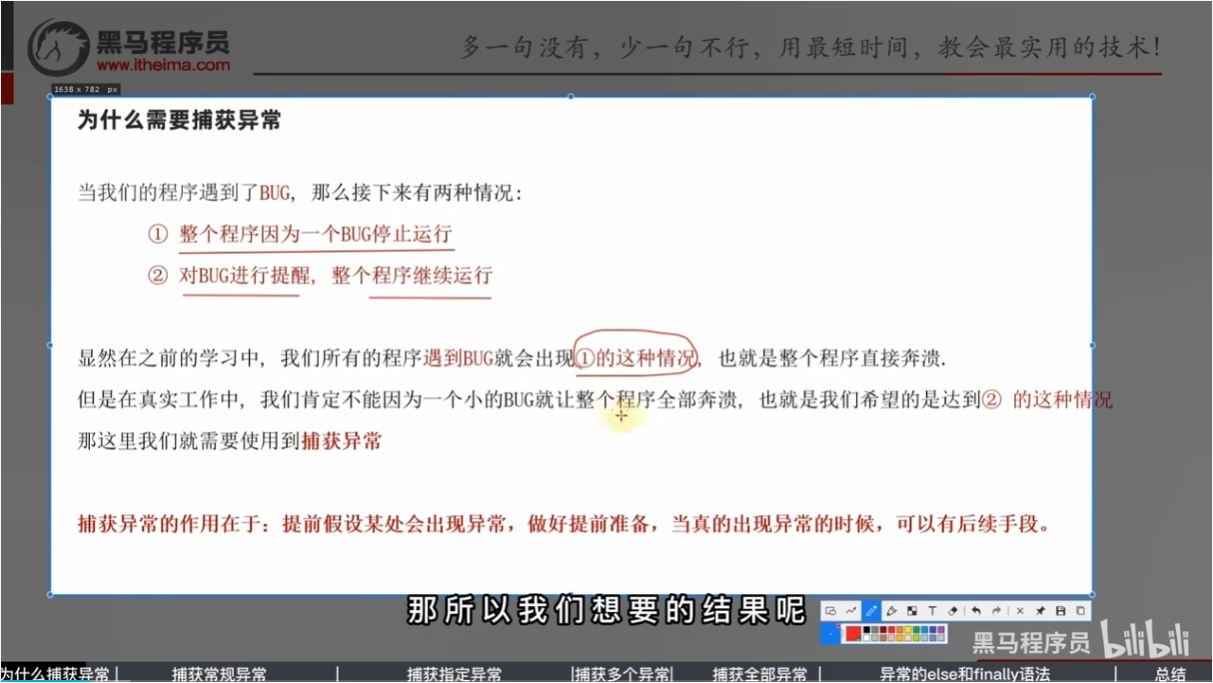
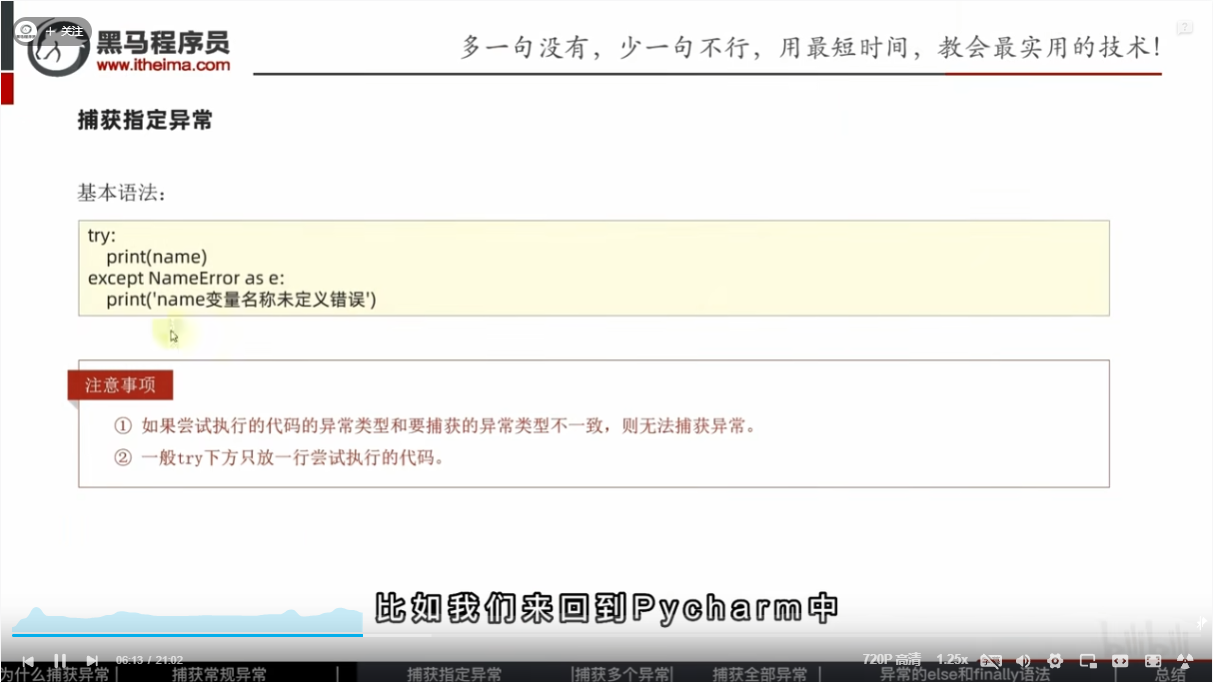
捕获指定异常
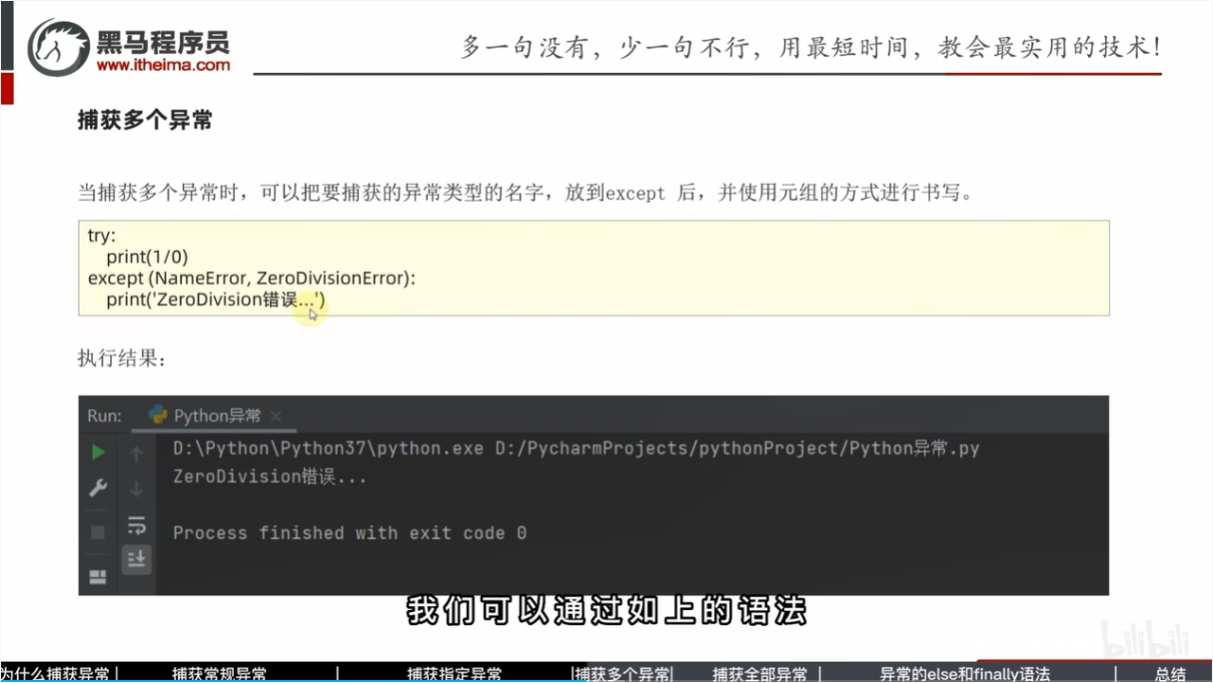
捕获多个异常
总结
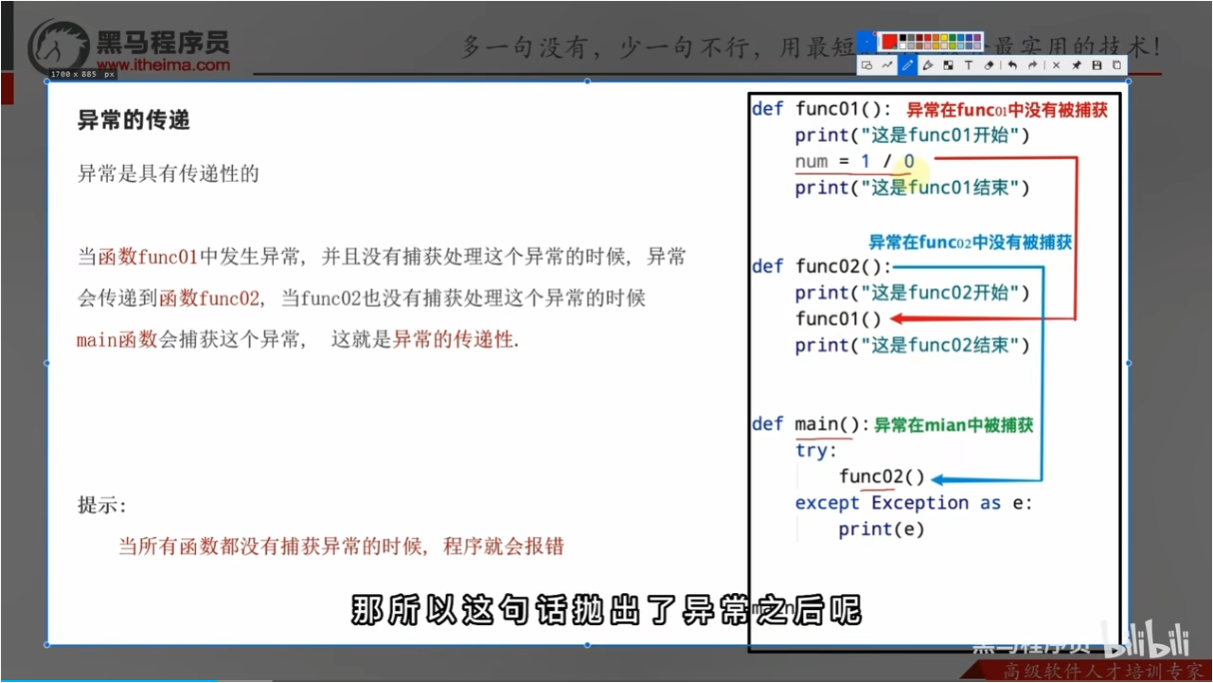
异常的传递
异常的传递
Python模块
模块的概念和导入
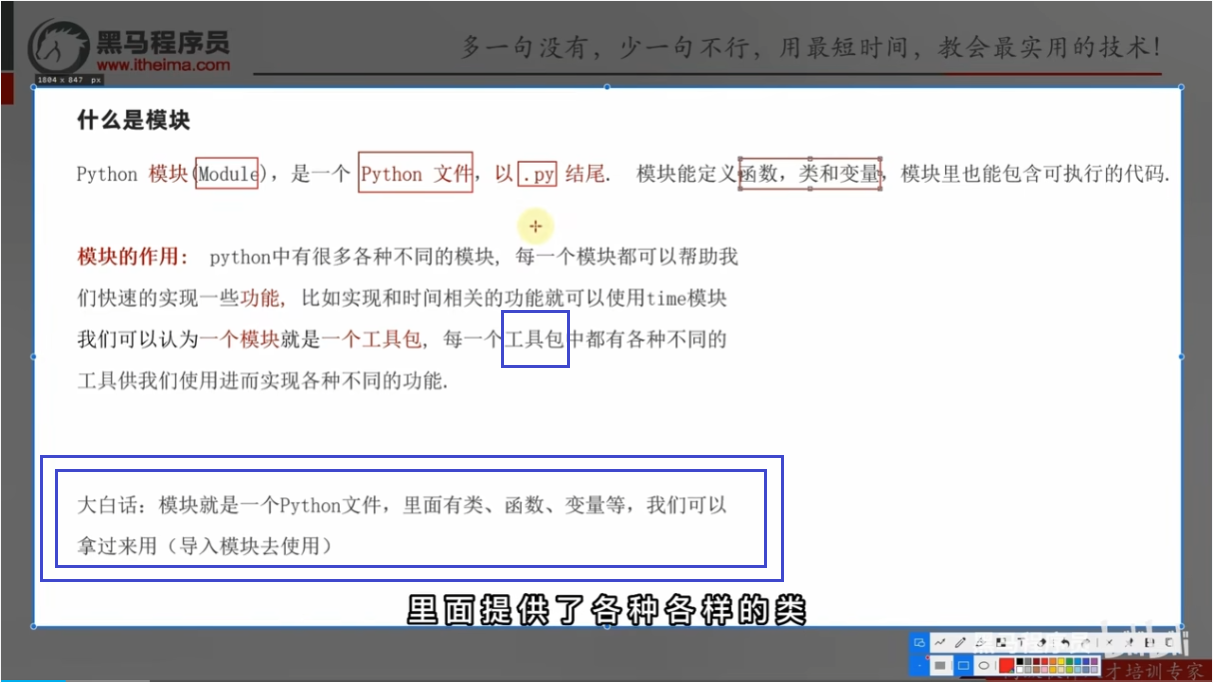
什么是模块?
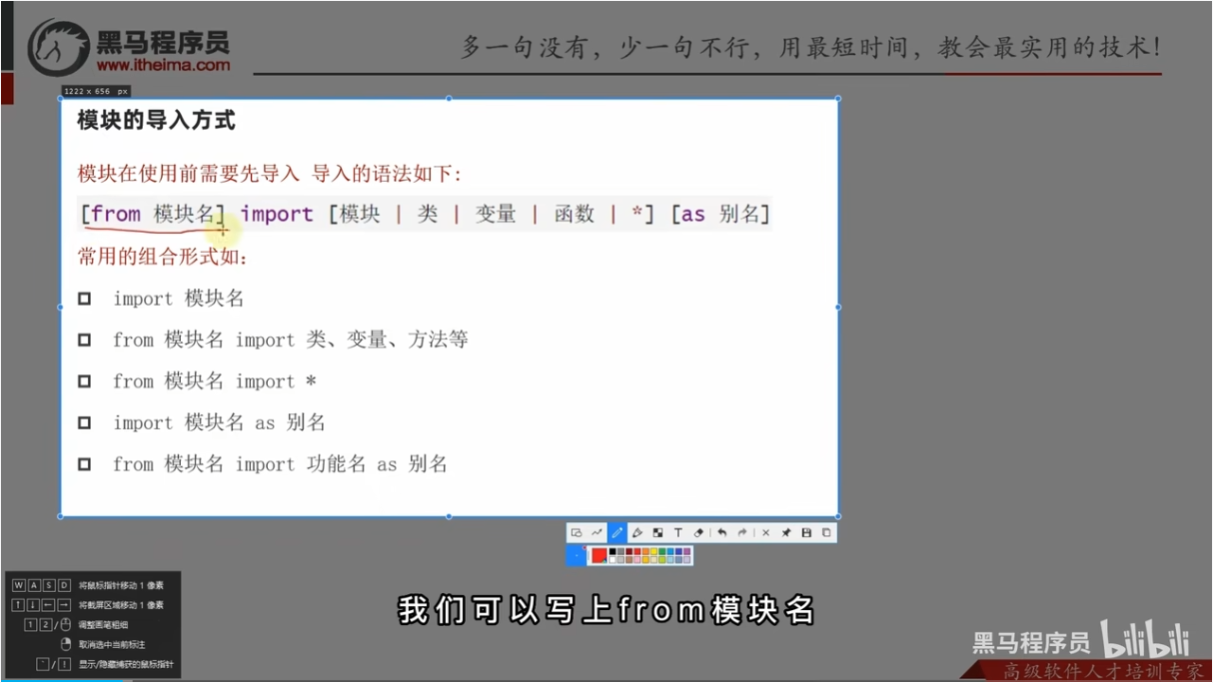
模块的导入方式
1
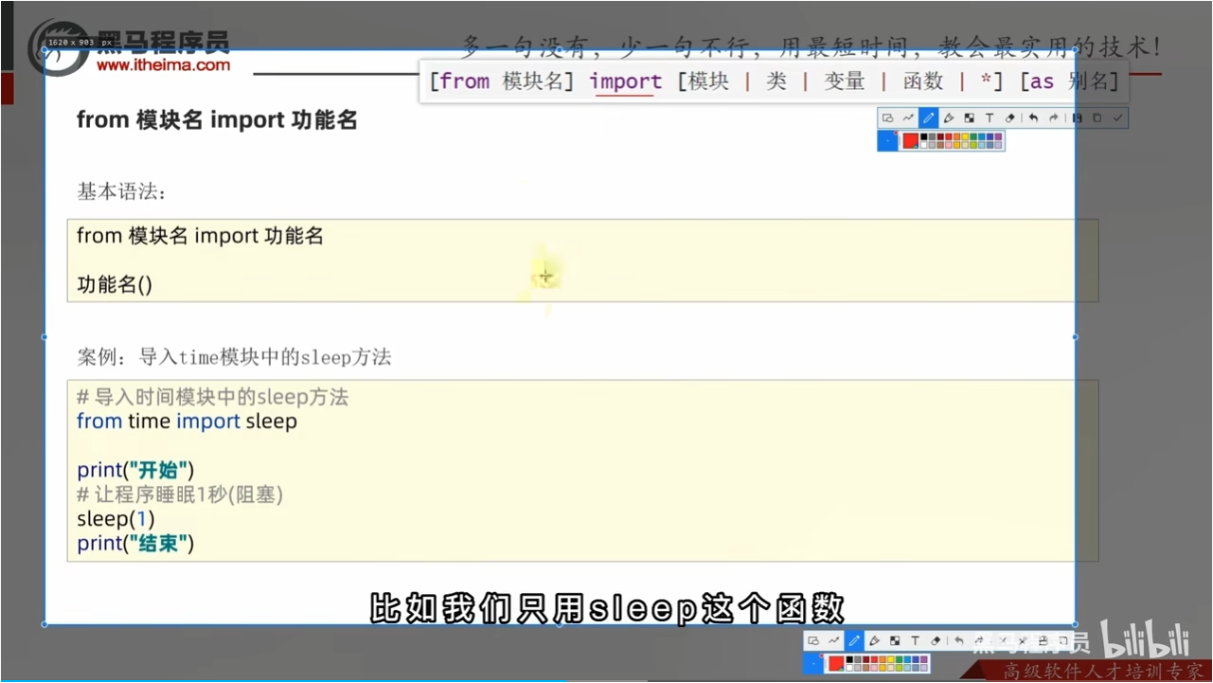
2 只使用time模块中的某个功能
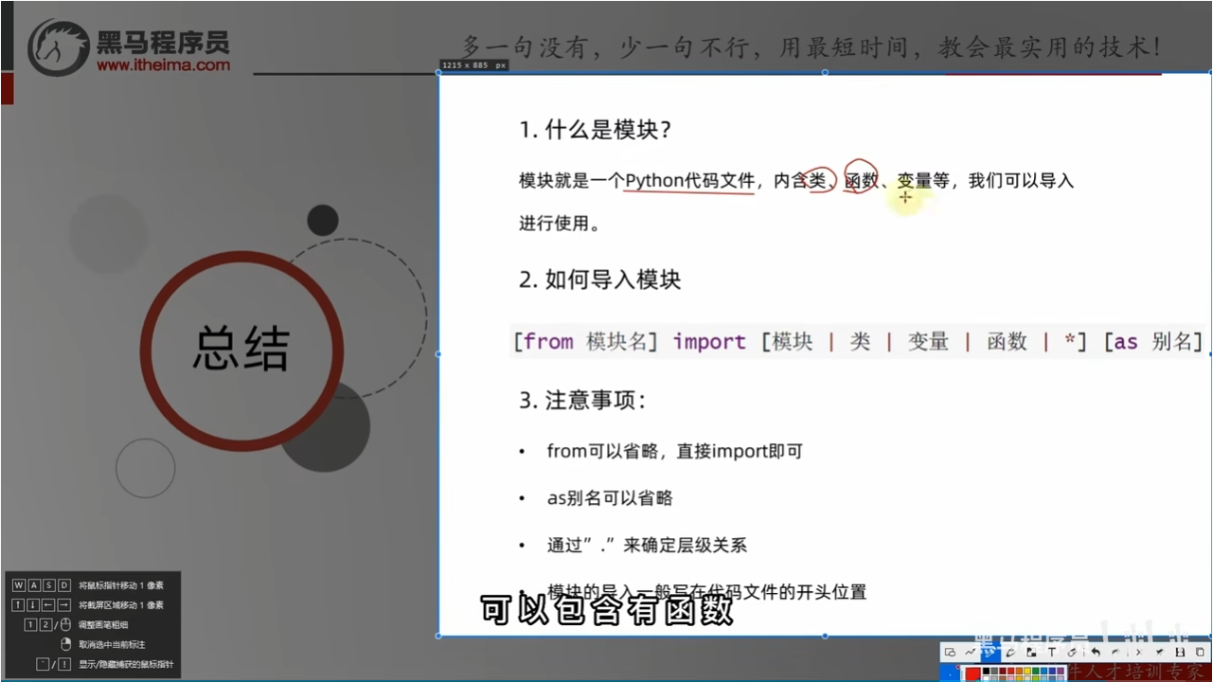
总结
自定义模块并导入
个性化模块–自定义模块
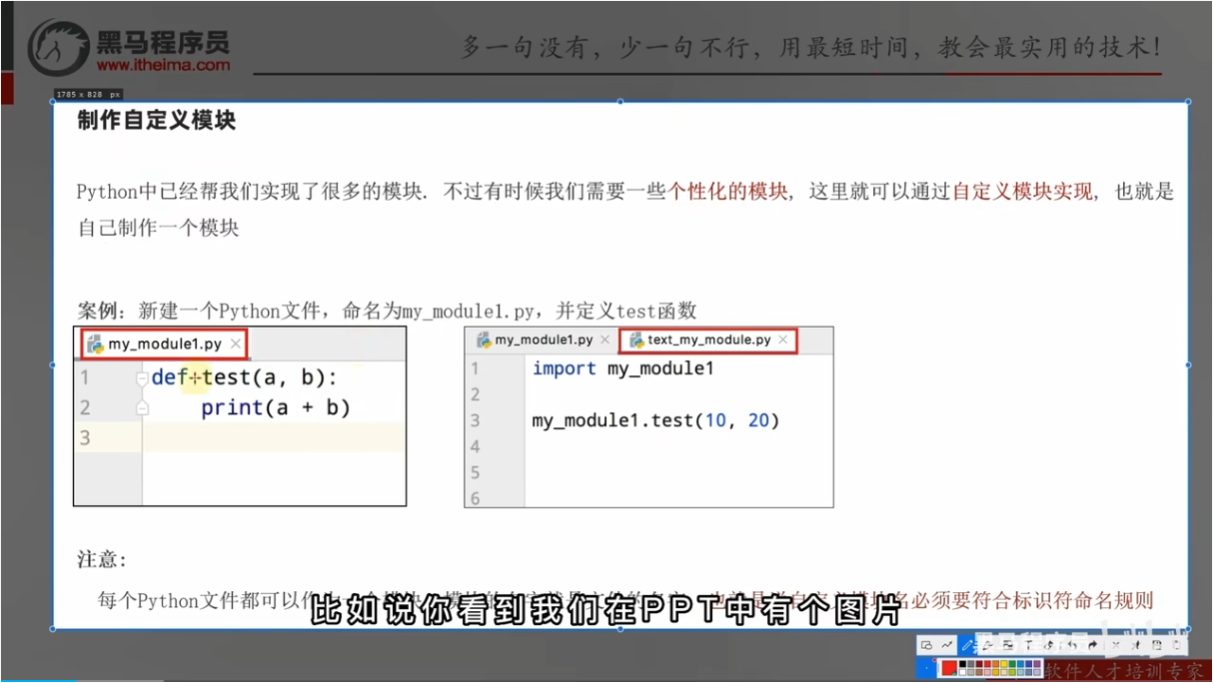
注意事项
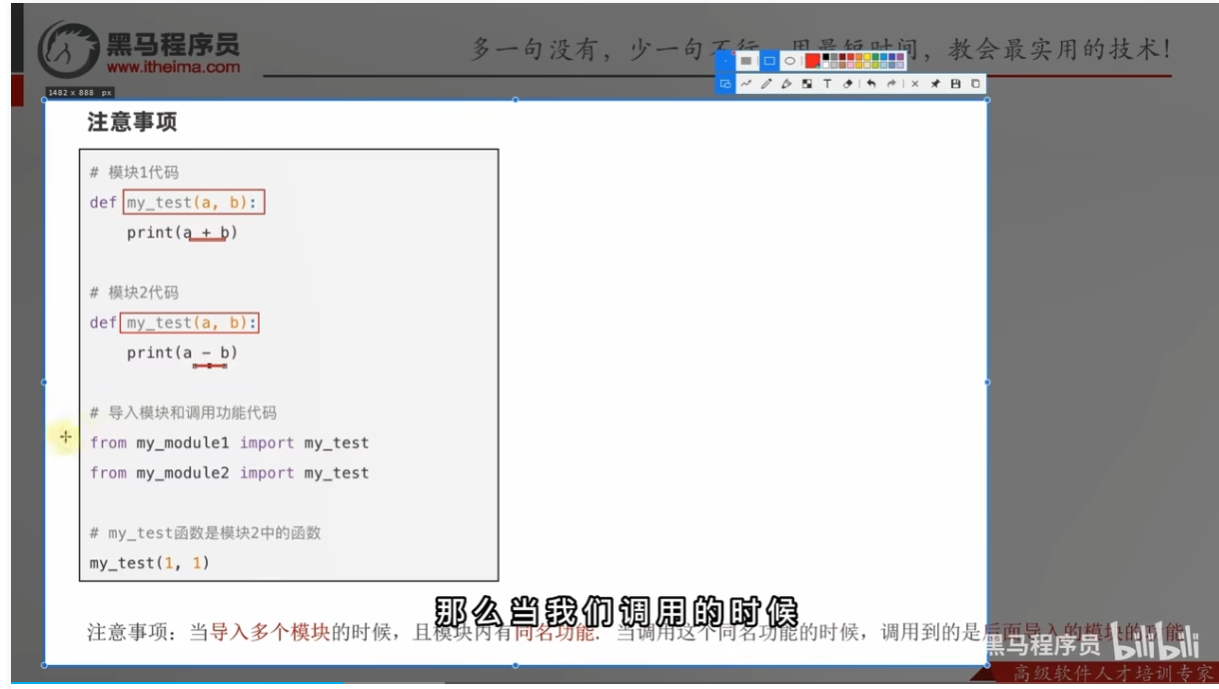
总结
__main__:只有当程序是直接执行时才会进入
__all__:可以控制import的时候哪些功能可以被导入,当然也可以直接手动去决定导入哪些内容,因为all是控制*的(详细建python文件)

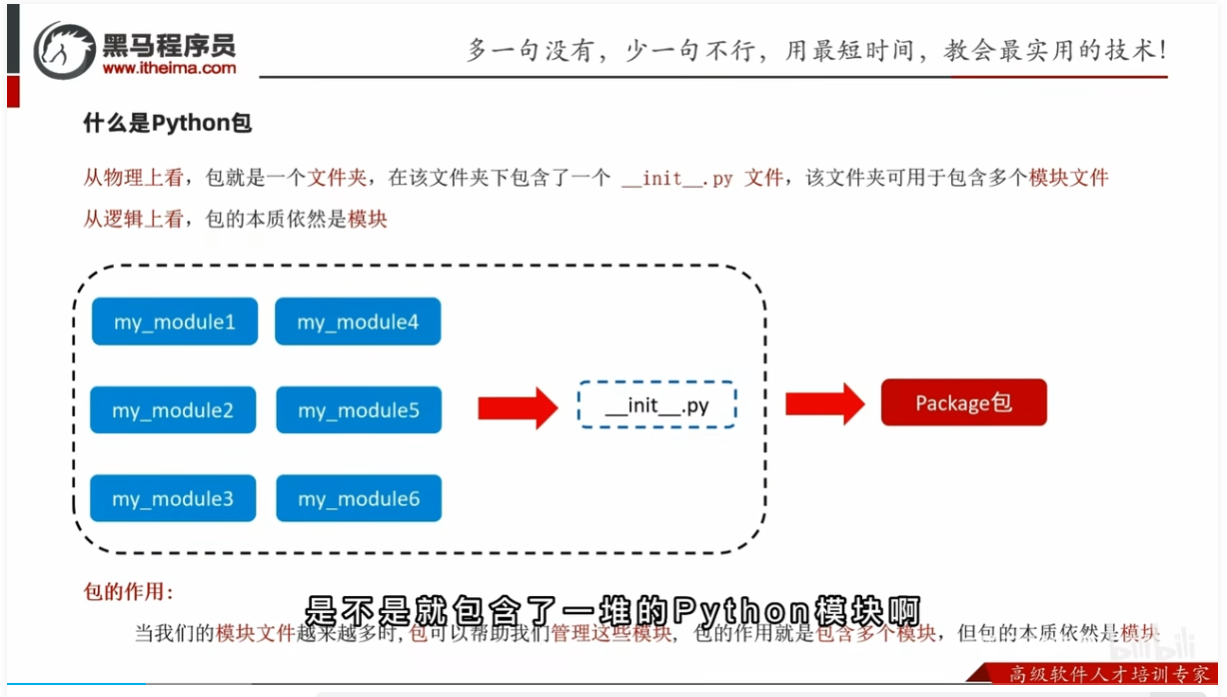
自定义python包
自定义包
只要有__init__.py这个文件
步骤
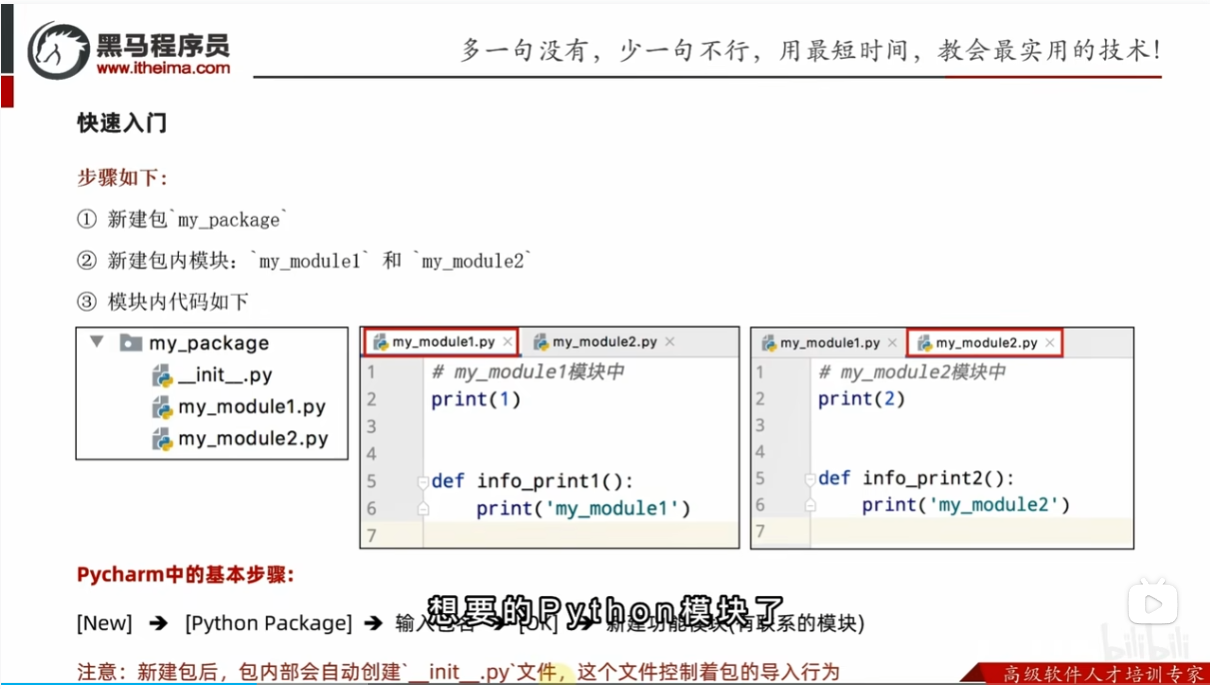
导入包
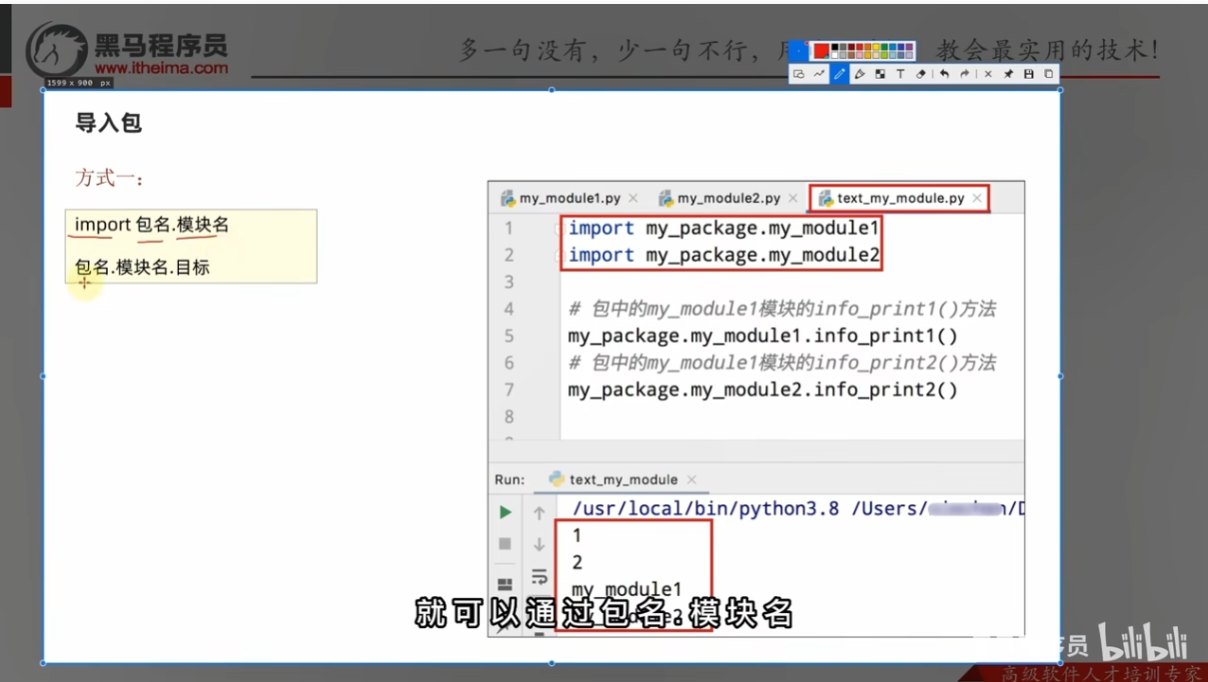
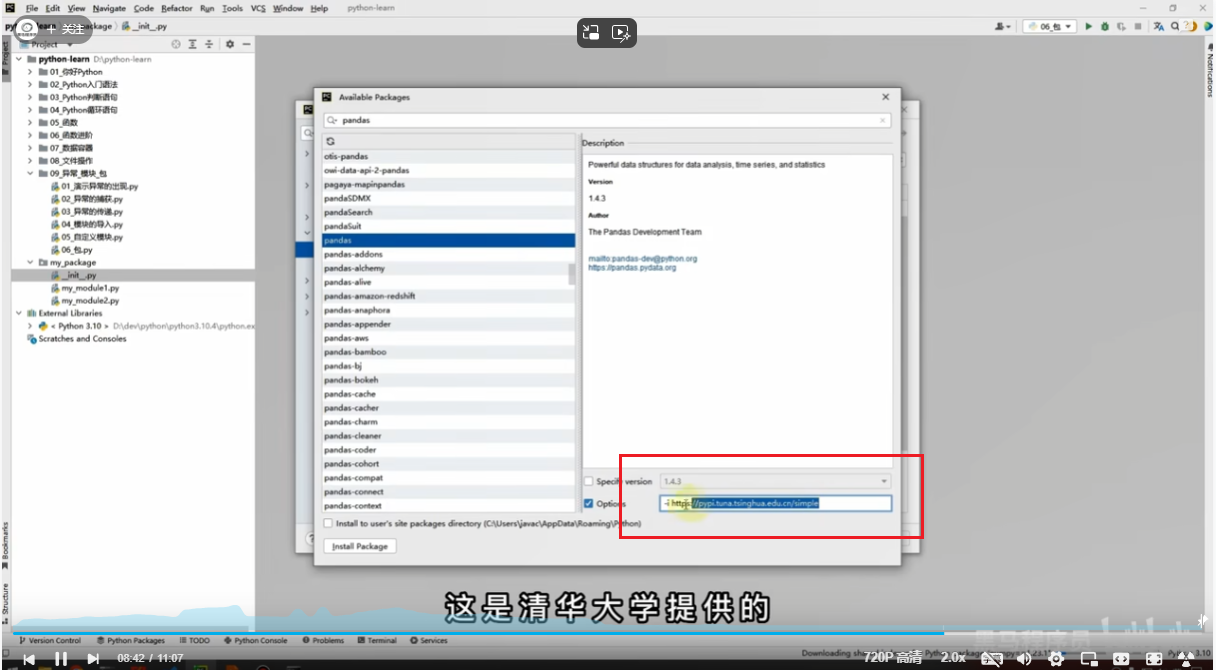
安装第三方包
一个包,就是一堆同类型功能的几何体

安装第三方包

pip install numpy
可通过清华大学提供的链接下载包(以下载numpy包为例)
pip inatall-i http://pypi.tuna.tsinghua.edu.cn/simple numpy
也可通过pycharm安装
安装步骤:
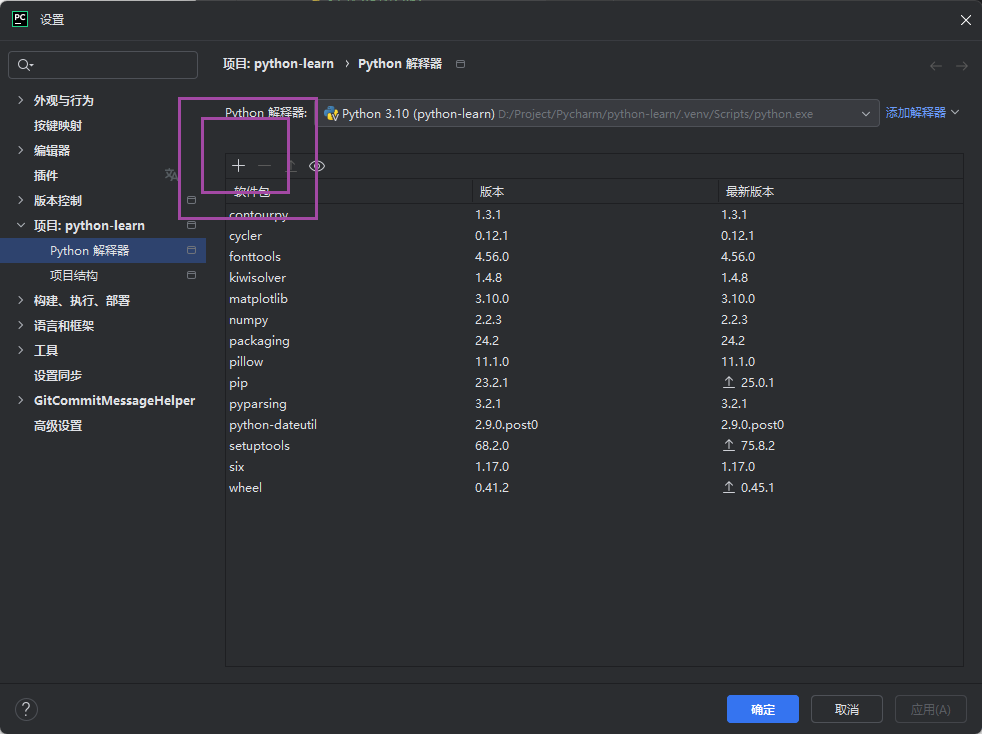
总结
异常-模块-包-综合案例讲解
案例
建议多看看这部分内容
python基础综合案例-数据可视化
折线图开发
JSON数据格式的转化
定义
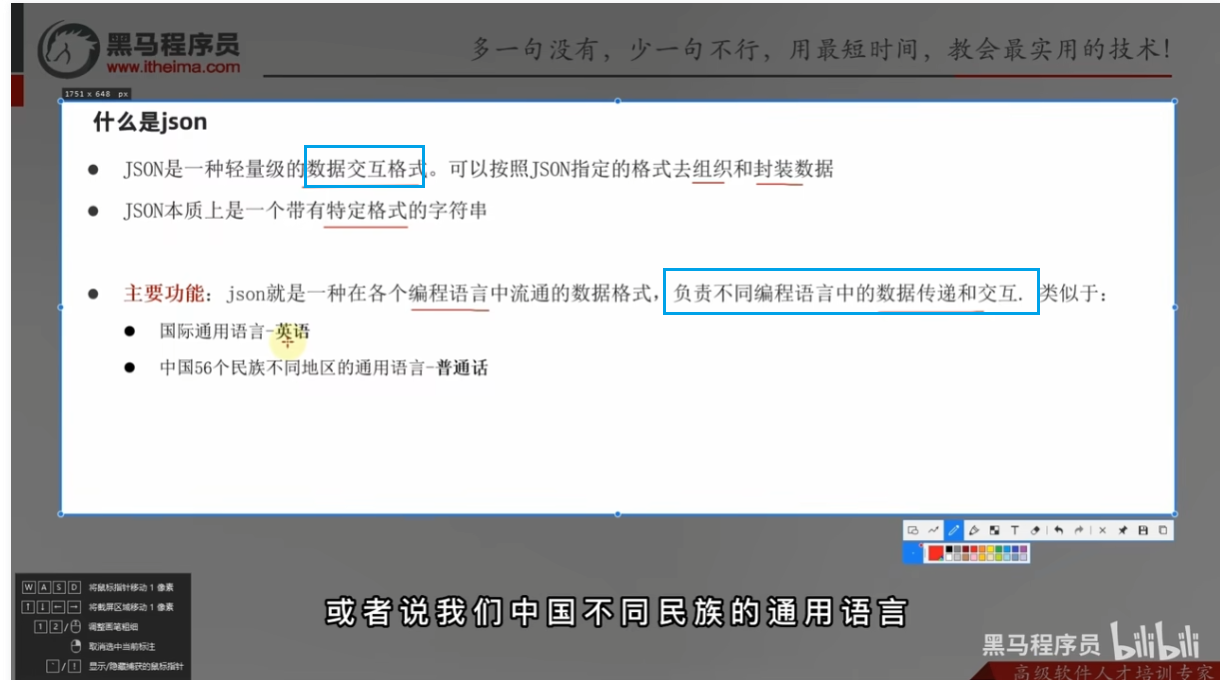
作用
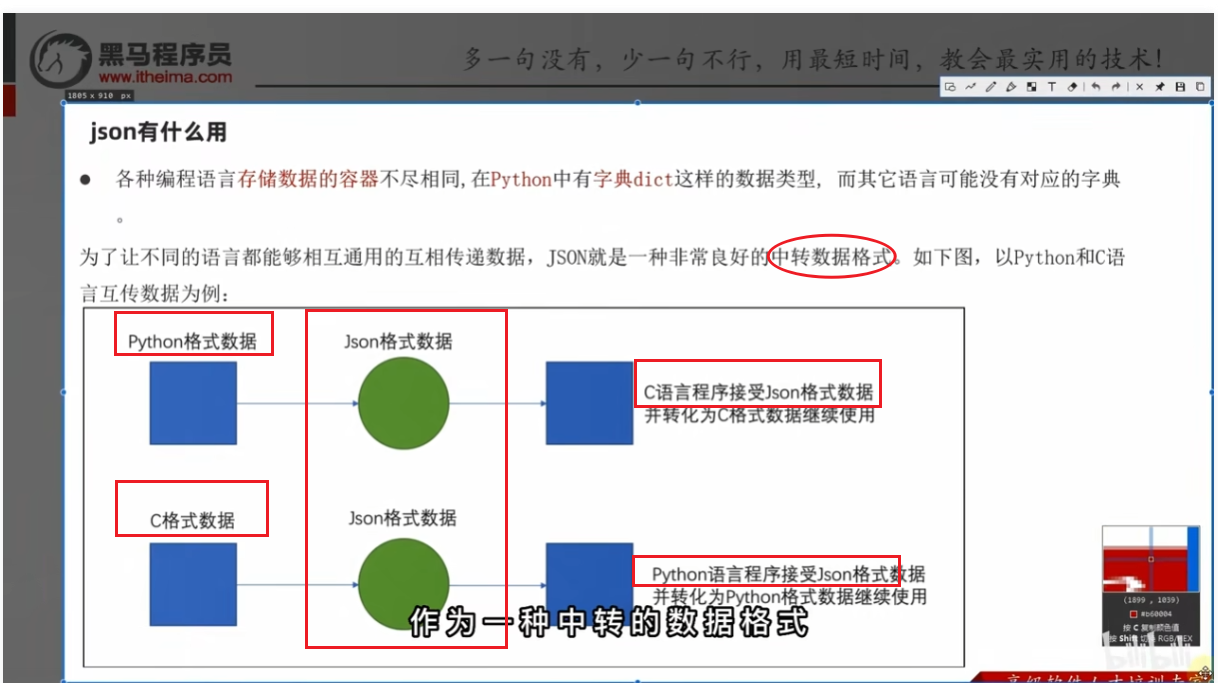
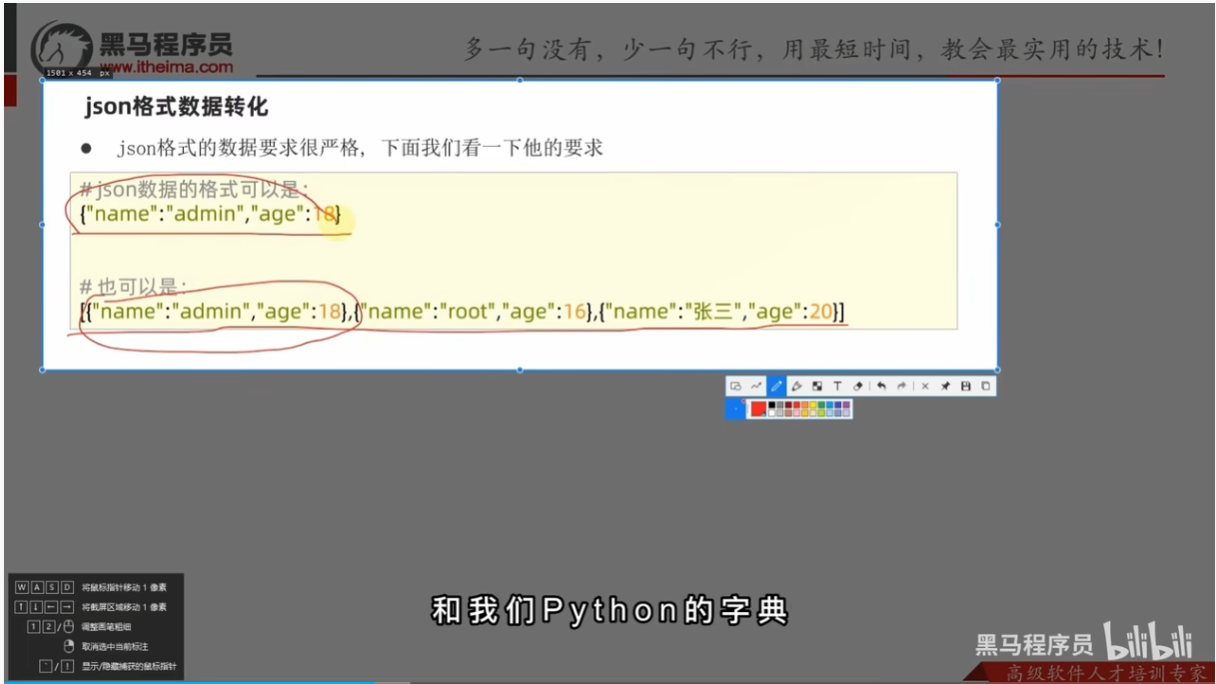
json格式数据格式
就是python语言中的字典,或者是列表(里面是字典格式)
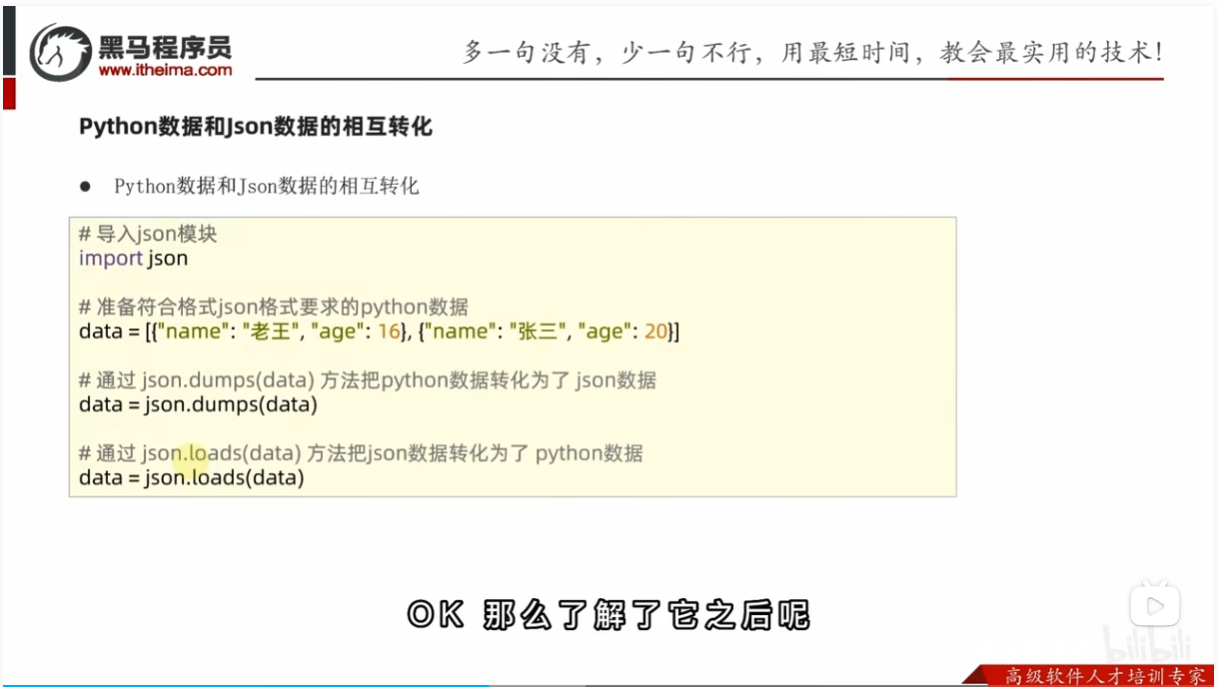
python数据和json数据的相互转化
示例
"""
演示JSON格式的转换
"""
import json
# 准备一个列表,列表内的元素都是字典,将其转换为JSON
data = [{"name":"张大山", "age":11}, {"name":"王大锤", "age":13}, {"name":"赵小虎", "age":16}]
json_str = json.dumps(data, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 准备字典,将字典转换为JSON
d = {"name":"周杰伦", "addr":"台北"}
json_str = json.dumps(d, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 将JSON字符串转化为python数据类型[{k: v, k: v},{k: v, k: v}] ,加单引号是因为json格式本身被看做是一种特殊的字符串格式,只不过之前输出时被省略了
s = '[{"name":"张大山", "age":11}, {"name":"王大锤", "age":13}, {"name":"赵小虎", "age":16}]' # 注意要把列表转换为字符串
l = json.loads(s)
print(type(l))
print(l)
# 将json字符串转化为python数据类型 {k: v, k: v}
s = '{"name":"周杰伦", "addr":"台北"}'
d = json.loads(s)
print(type(d))
print(d)
总结

pyecharts模块简介
pyecharts:pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库。
画廊:pyecharts – A Python Echarts Plotting Library built with love.
安装pyecharts包
总结

pyecharts的入门使用
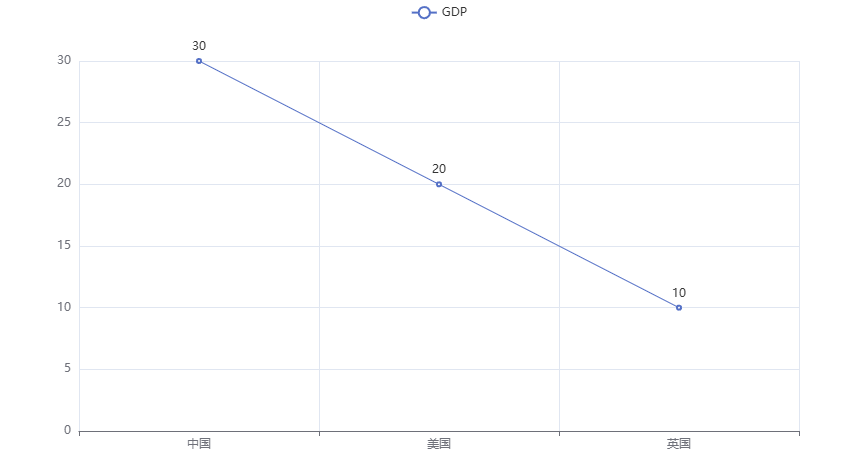
"""
演示pyecharts的基础入门
"""
# 导包
from pyecharts.charts import Line
# 创建一个折线图对象
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "美国", "英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("GDP", [30, 20, 10])
# 通过render方法,将代码生成图像
line.render()
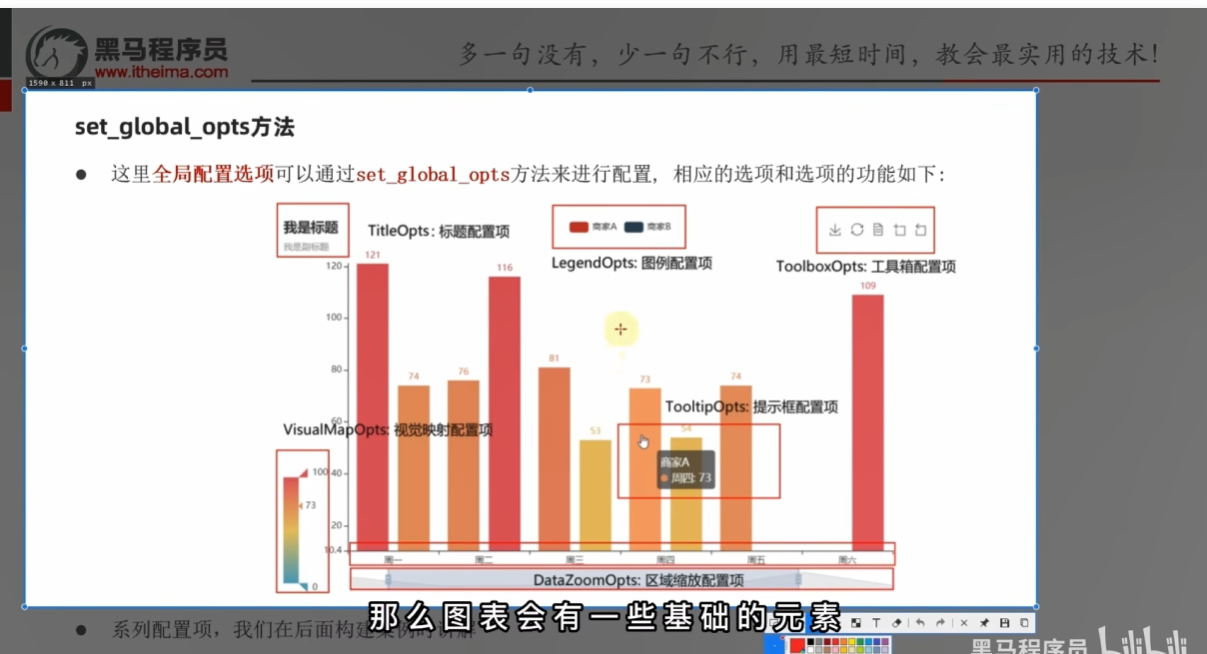
# 设置全局配置项
pyecharts配置选项
- 全局配置
python
# 设置全局配置项
line.set_global_opts(
title_opts=TitleOpts(title="GDP显示", pos_left="center", pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True),
)
- 系列配置
总结
全局配置不只以下部分,共有十几个
数据处理(通过json模块对数据进行处理)
复制数据-粘贴到下面网站-简单梳理出数据的层次
https://www.bejson.com/jsonviewernew/#google_vignette
难点在于该数据层级过多,获取数据较为复杂
"""
演示可视化需求1:折线图开发
"""
import json
# 数据准备
f_us = open("E:/document/资料/资料/可视化案例数据/折线图数据/美国.txt", "r", encoding="utf-8")
us_data = f_us.read() # 读取美国的全部内容
# 去掉文件中不符合json规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
# 去掉末尾不符合json规范的结尾,序列的切片
us_data = us_data[:-2]
# JSON转python字典 语法:json.loads(数据)
us_dict = json.loads(us_data)
print(type(us_dict))
print(us_dict)
# 获取trend
trend_data = us_dict['data'][0]['trend']
print(trend_data)
# 获取日期数据,用于x轴,取2020年(到314下标结束数据切片:[:314])
x_data = trend_data['updateDate'][:314]
print(x_data)
# 获取确认数据,用于u轴,取2020年(到314结束)
y_data = trend_data['list'][0]['data'][:314]
print(y_data)
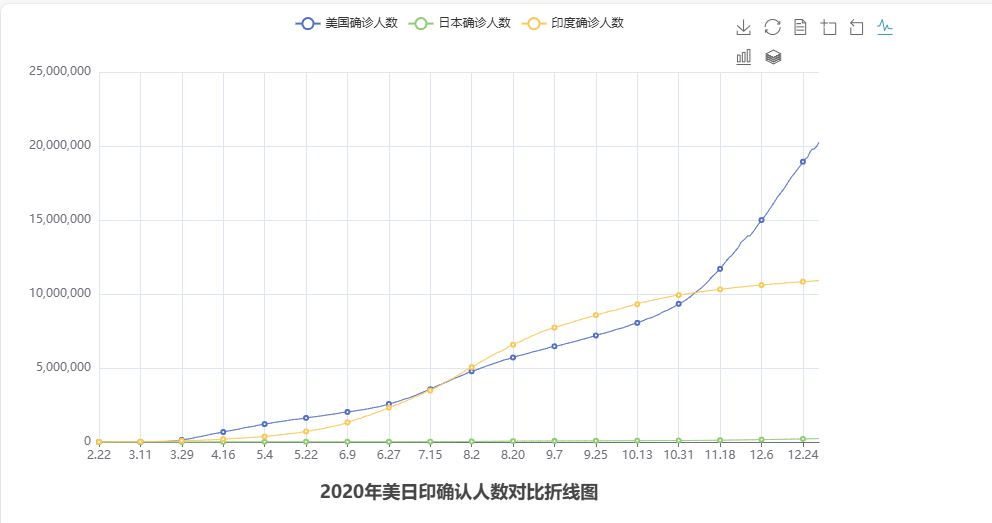
生成折线图(通过pyecharts完成疫情折线图)
"""
演示可视化需求1:折线图开发
"""
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts
# 数据准备
f_us = open("E:/document/资料/资料/可视化案例数据/折线图数据/美国.txt", "r", encoding="utf-8")
us_data = f_us.read() # 读取美国的全部内容
f_jp = open("E:/document/资料/资料/可视化案例数据/折线图数据/日本.txt", "r", encoding="utf-8")
jp_data = f_jp.read() # 读取日本的全部内容
f_in = open("E:/document/资料/资料/可视化案例数据/折线图数据/印度.txt", "r", encoding="utf-8")
in_data = f_in.read() # 读取印度的全部内容
# 去掉文件中不符合json规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
in_data = in_data.replace("jsonp_1629350745930_63180(", "")
# 去掉末尾不符合json规范的结尾,序列的切片
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
print(jp_data[:200]) # 打印前200个字符
print(jp_data[-200:]) # 打印后200个字符
# JSON转python字典 语法:json.loads(数据)
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取trend key(也就是字典的键值对的 键)
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年(到314下标结束数据切片:[:314])
us_x_data = us_trend_data['updateDate'][:314]
print(us_x_data)
jp_x_data = jp_trend_data['updateDate'][:314]
print(jp_x_data)
in_x_data = in_trend_data['updateDate'][:314]
print(in_x_data)
# 获取确认数据,用于u轴,取2020年(到314结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
print(us_y_data)
jp_y_data = jp_trend_data['list'][0]['data'][:314]
print(jp_y_data)
in_y_data = in_trend_data['list'][0]['data'][:314]
print(in_y_data)
# 生成图表
line = Line()
# 添加x轴,共用一个就可以了
line.add_xaxis(us_x_data)
# 添加y轴数据
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
# 设置全局变量
line.set_global_opts(
# 标题设置
title_opts=TitleOpts(title="2020年美日印确认人数对比折线图",pos_left="center",pos_bottom="1%"),
)
# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()
运行结果
地图可视化
基础地图使用
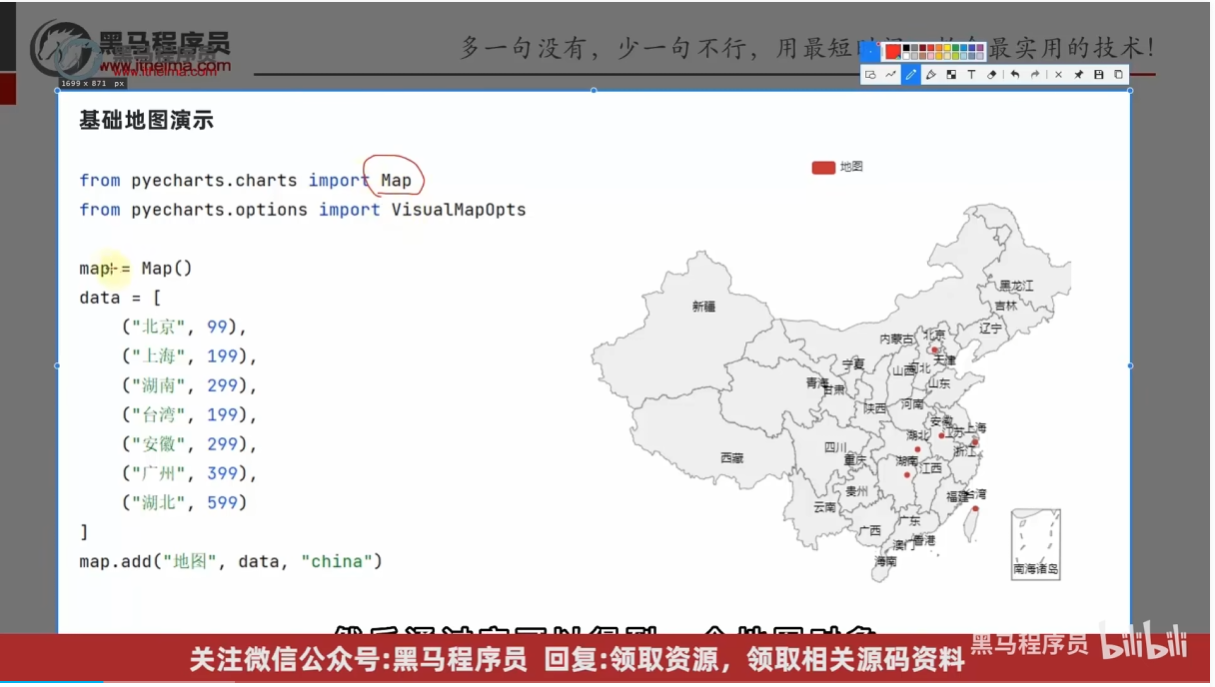
"""
地图可视化的基本使用
"""
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
# 准备地图对象
map = Map()
# 准备数据
data = [
("北京市", 99),
("上海市", 199),
("湖南省", 299),
("台湾省", 399),
("广东省", 499)
]
map.add("测试地图", data, "china")
# 设置全局选项
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True, # 开启手动校准范围
pieces=[
{"min": 1, "max": 9,"label":"1-9", "color": "#CCFFFF"},
{"min": 10, "max": 99,"label":"10-99", "color": "#FFFF99"},
{"min": 100, "max":199 ,"label":"100-199", "color": "#FF9966"},
{"min": 200, "max": 299,"label":"200-299", "color": "#FF6666"},
{"min": 300, "max": 399,"label":"300-399", "color": "#CC3333"},
{"min": 400, "max": 499,"label":"400-499", "color": "#990033"},
]
# 具体的范围是多少了
)
)
# 绘图
map.render()
疫情地图-国内疫情地图
注意如何取得数据,利用json数据网站,获得数据层级(清楚元组和列表如何获取数据)
在线JSON校检格式化工具网站:https://www.bejson.com/
"""
演示全国疫情可视化地图开发
"""
import json
from pyecharts.charts import Map # 导包,引入...功能
from pyecharts.options import *
# 读取数据文件
f = open("E:/document/资料/资料/可视化案例数据/地图数据/疫情.txt", "r", encoding="UTF-8")
data = f.read() # 读取全部数据
# 关闭文件
f.close()
# 取到各省数据
# 将字符串json转换为python的字典
data_dict = json.loads(data) # 基础数据字典
# 从字典中取出省份的数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
data_list = [] # 绘图需要用的数据列表
for province_data in province_data_list:
province_name = province_data["name"] # 得到省份名称
# 确保每个省份名称都加上 "省" 字符
if province_name == "新疆":
province_name = "新疆维吾尔自治区"
elif province_name == "西藏":
province_name = "西藏自治区"
elif province_name == "内蒙古":
province_name = "内蒙古自治区"
elif province_name == "宁夏":
province_name = "宁夏回族自治区"
elif province_name == "广西":
province_name = "广西壮族自治区"
elif province_name == "北京":
province_name = "北京市"
elif province_name == "上海":
province_name = "上海市"
elif province_name == "天津":
province_name = "天津市"
elif province_name == "重庆":
province_name = "重庆市"
elif "省" not in province_name and province_name not in ["澳门", "香港",]:
province_name += "省"
province_confirm = province_data["total"]["confirm"] # 确诊人数
data_list.append((province_name, province_confirm)) # 封装到列表中,此时定义一个画图要用的列表
print(province_name)
# 创建地图对象
map = Map()
# 添加数据 map.add()
map.add("各省份确诊人数", data_list, "china")
# 设置全局配置,定制分段的视觉映射
map.set_global_opts(
title_opts=TitleOpts(title="全国疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces=[
{"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"},
{"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"},
{"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"},
{"min": 100000, "lable": "100000+", "color": "#990033"},
] # lable:表示名字
)
)
# 绘图
map.render("全国疫情地图.html") # 可以设置生成文件名字
疫情地图-省级疫情地图
"""
演示河南省疫情地图开发
"""
import json
from pyecharts.charts import Map
from pyecharts.options import *
# 读取文件
f = open("E:/document/资料/资料/可视化案例数据/地图数据/疫情.txt", "r", encoding="UTF-8")
data = f.read()
# 关闭文件
f.close()
# 获取河南省数据
# json数据转换为python字典
data_dict = json.loads(data)
# 取到河南省数据
cities_data = data_dict["areaTree"][0]["children"][3]["children"]
# 准备数据为元组并放入list
data_list = []
for city_data in cities_data:
city_name = city_data["name"] + "市"
city_confirm = city_data["total"]["confirm"]
data_list.append((city_name, city_confirm))
# 手动添加济源市的数据
data_list.append(("济源市", 5)) #.append() 是 Python 中 列表(list) 的一个方法,用来将一个元素添加到列表的末尾。
# 构建地图
map = Map()
map.add("河南省疫情分布", data_list, "河南")
# 设置全局选项
map.set_global_opts(
title_opts=TitleOpts(title="河南省疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces=[
{"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"},
{"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"},
{"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"},
{"min": 100000, "lable": "100000+", "color": "#990033"},
]
)
)
# 绘图
map.render("河南省疫情地图.html")
动态柱状图
基础柱状图
"""
演示基础柱状图的开发
"""
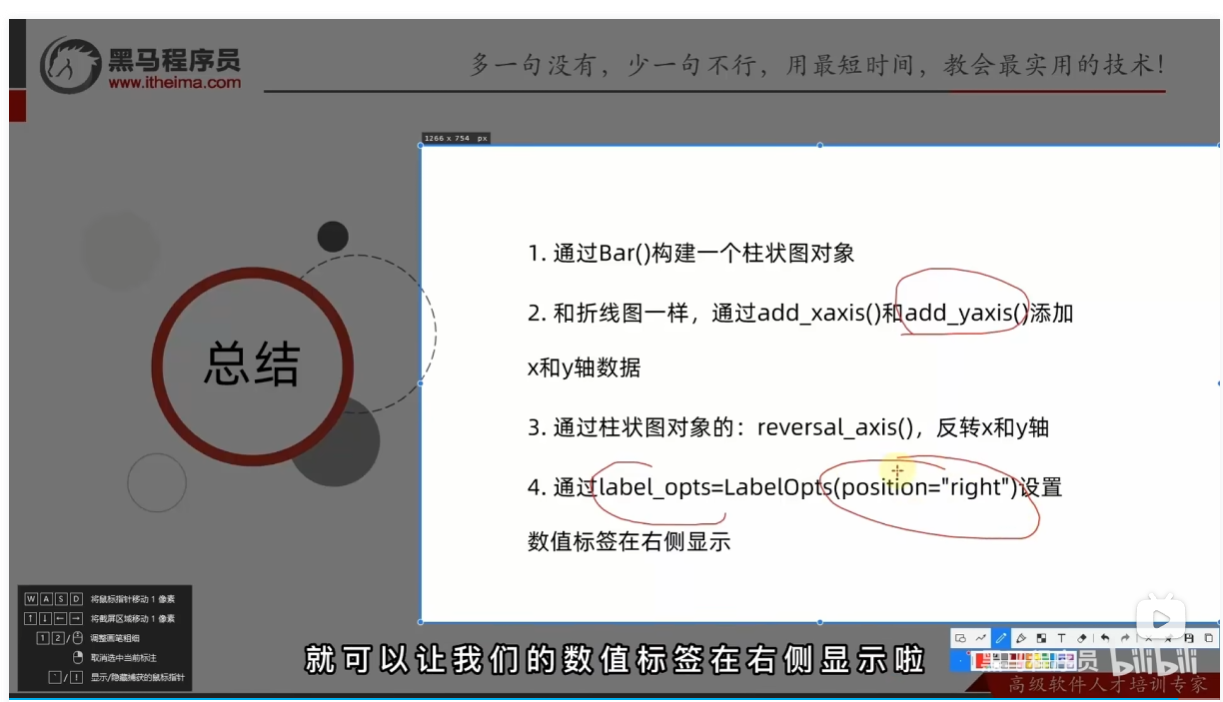
from pyecharts.charts import Bar
from pyecharts.options import LabelOpts
# 使用Bar构建基础柱状图
bar = Bar()
# 添加x轴的数据
bar.add_xaxis(["中国", "美国", "英国"])
# 添加y轴数据
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
# 反转x和y轴 可以通过调用reversal调用这个方法
bar.reversal_axis()
# 绘图
bar.render("基础柱状图.html")
# 设置数值标签在右侧 label_opts=LabelOpts(position="right")
总结
基础时间线柱状图
创建时间线
动态图:实际就是在一个x轴上有非常多的点,每一个点都对应一个图,连起来就像是动图一样。

"""
演示带有时间线的柱状图开发
"""
from pyecharts.charts import Bar, Timeline
from pyecharts.options import LabelOpts
from pyecharts.globals import ThemeType
bar1 = Bar()
bar1.add_xaxis(["中国", "美国", "英国"])
bar1.add_yaxis("GDP", [30, 30, 20], label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国", "美国", "英国"])
bar2.add_yaxis("GDP", [50, 50, 50], label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
bar3 = Bar()
bar3.add_xaxis(["中国", "美国", "英国"])
bar3.add_yaxis("GDP", [70, 60, 60], label_opts=LabelOpts(position="right"))
bar3.reversal_axis()
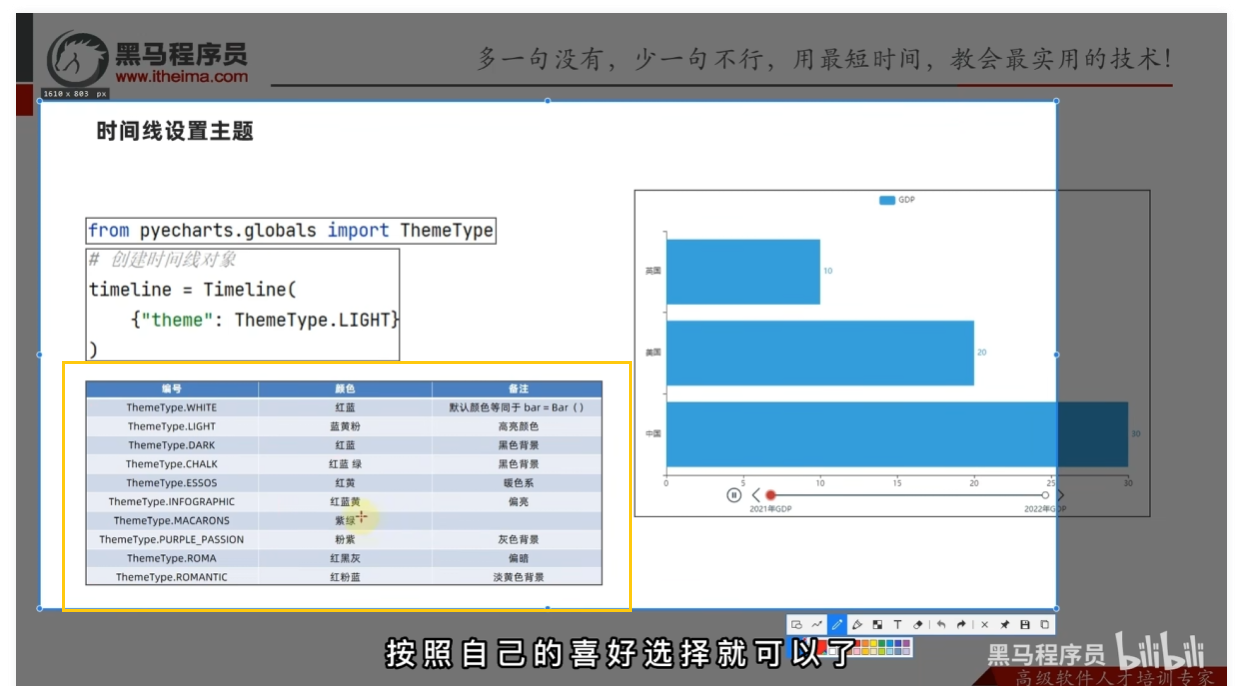
# 构建时间线对象,设置一个主题,也就是可以设置主题颜色
timeline = Timeline({"theme": ThemeType.LIGHT})
# 在时间线内添加柱状图对象,就是添加对应的点
timeline.add(bar1, "点1")
timeline.add(bar2, "点2")
timeline.add(bar3, "点3")
# 自动播放设置
timeline.add_schema(
play_interval=1000, # 自动播放时间间隔,单位毫秒
is_timeline_show=True, # 是否在自动播放的时候,显示时间线
is_auto_play=True, # 是否自动播放
is_loop_play=True # 是否循环自动播放
)
# 绘图是用时间线对象绘图,而不是bar对象了,因此就是timeline.render()
timeline.render("基础时间线柱状图.html")
总结
GDP动态柱状图绘制
1.补充列表的sort方法

- 定义一个函数,choose_sort_key(element) 把列表中的每个元素传进来,然后取1
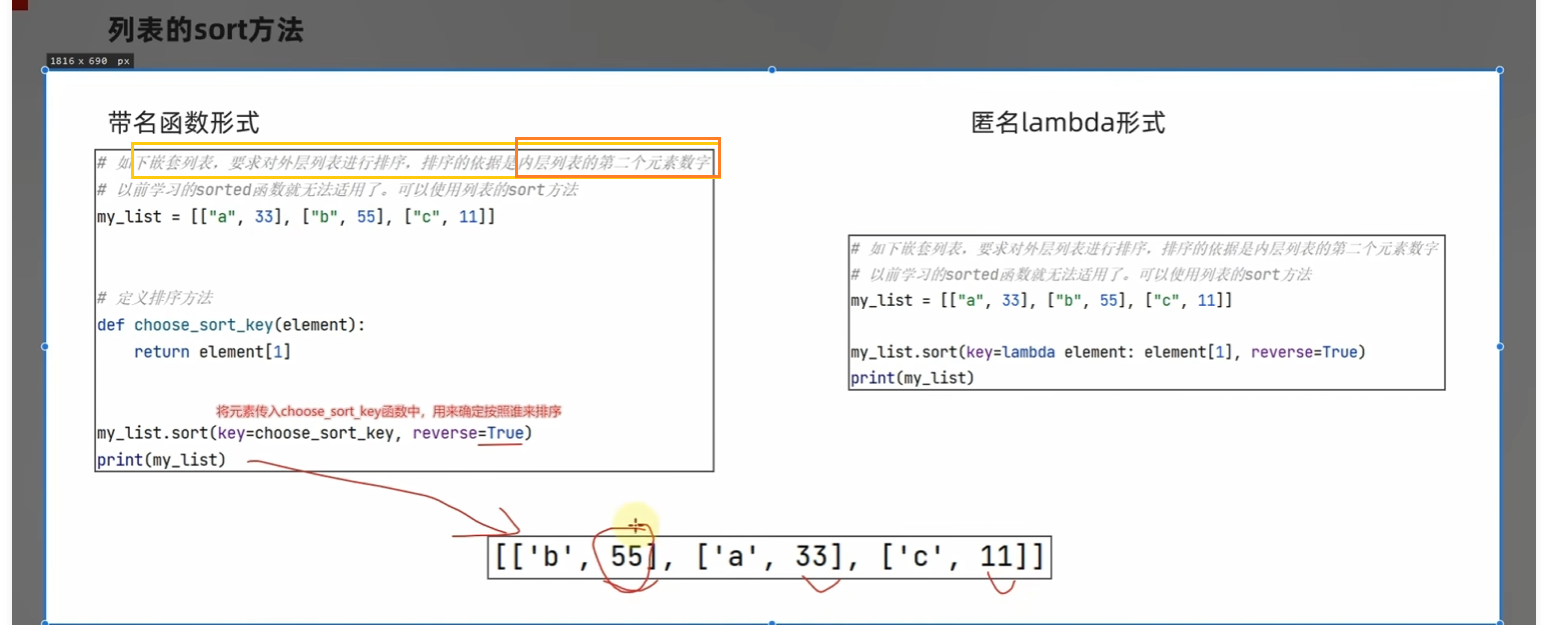
- 匿名lambda函数(上图右边)
2.需求分析(分块进行,共分为5块)
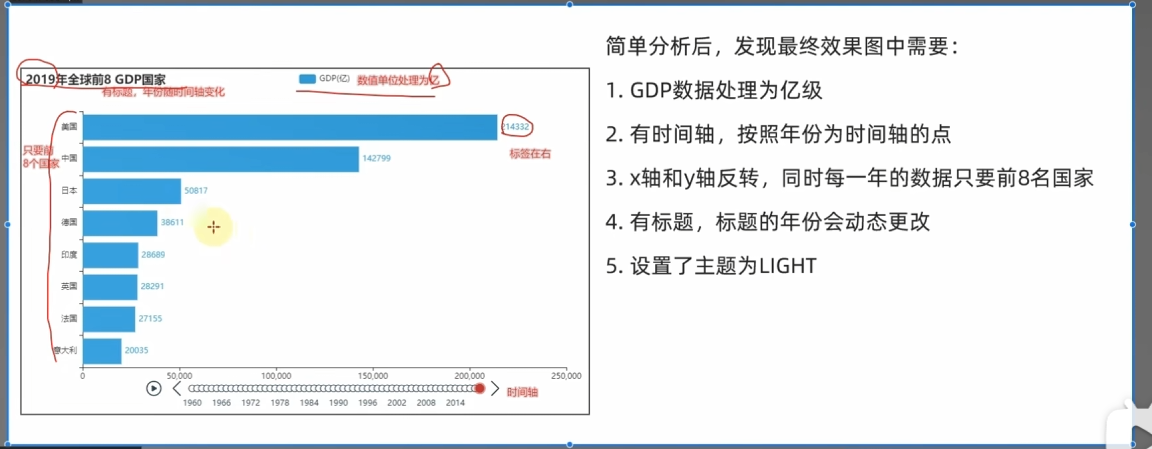
3.处理数据
- 读取数据
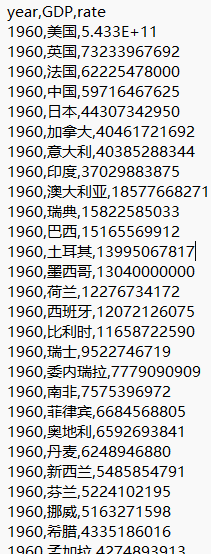
- 把需要的数据转换为所需要的格式
“`python
from pyecharts.charts import Bar, Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType
# 读取文件,注意文件的编码格式不是utf-8
f = open(“E:/document/资料/资料/可视化案例数据/动态柱状图数据/1960-2019全球GDP数据.csv”, “r”, encoding=”GB2312″)
data_lines = f.readlines() # f.readlines()方法会读取文件的所有行,并返回一个列表
# 关闭文件
f.close()
# 删除第一条数据
data_lines.pop(0)
# 将数据转换为字典存储
# 先定义一个字典对象
data_dict = {}
for line in data_lines:
year = int(line.split(“,”)[0]) # 转换为数字了→年份
country = line.split(“,”)[1] # 国家
gdp = float(line.split(“,”)[2]) # gdp,用float强制将科学计数法转换
# 如何判断字典里面有没有指定的key
try:
data_dict[year].append([country,gdp]) #第一次追加没有年份,所以要捕获异常
except KeyError:
data_dict[year] = [] # 构建一个新的列表,直接给这个赋值 但是这个year不是key吗?赋值后变成什么了呢
data_dict[year].append([country,gdp])
timeline = Timeline(({“theme”: ThemeType.LIGHT}))
# 排序年份
sorted_year_list = sorted(data_dict.keys()) # 把所有的年份拿出来,按照顺序
# print(sorted_year_list)
for year in sorted_year_list:
data_dict[year].sort(key = lambda element: element[1],reverse = True)
# print(data_dict[year])
# 取出前8名的国家
year_data = data_dict[year][0:8]
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0]) # x轴追加国家
y_data.append(country_gdp[1]/100000000) # y追加GDP数据
# 构建柱状图
bar = Bar()
bar.add_xaxis(x_data)
x_data.reverse() # 反转一下
y_data.reverse() # 反转一下让美国在上
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right")) # 标签都在最右边
# 反转x轴和y轴
bar.reversal_axis()
# 设置每一年的图表标题
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前8GDP数据")
)
timeline.add(bar, str(year))
# 设置时间线自动播放
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=False
)
# 绘图
timeline.render(“1960-2019全球GDP前8国家2.html”)
“`
第二阶段
面向对象
初识对象
目标:理解使用对象完成数据组织的思路

总结
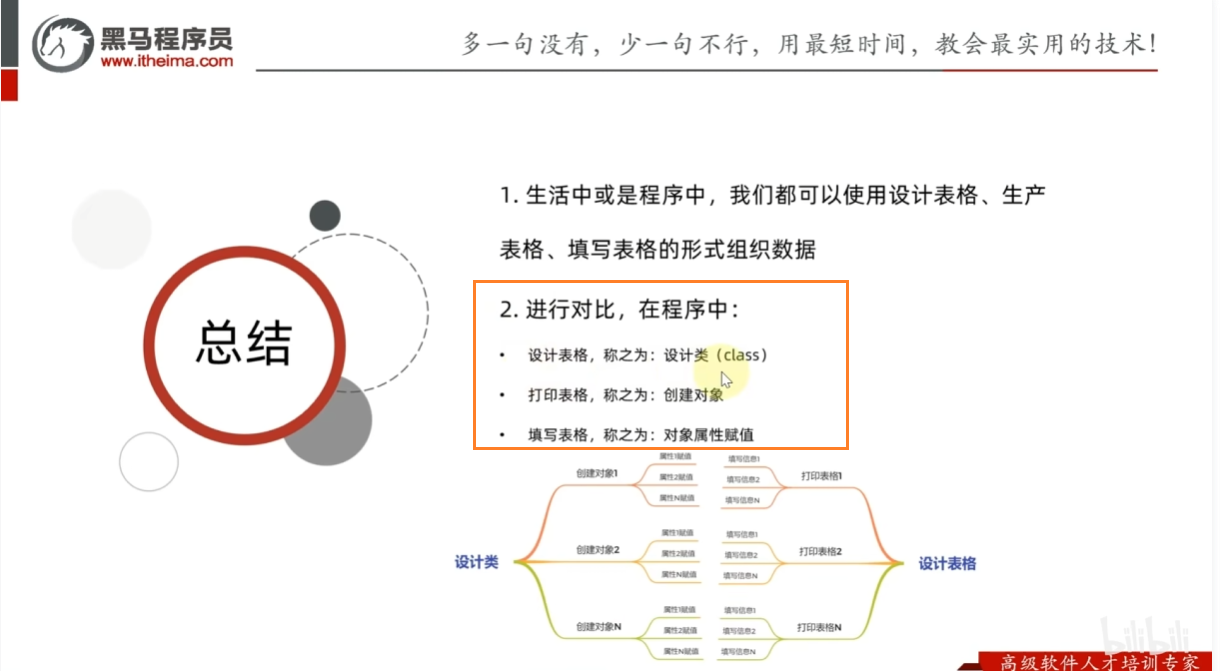
成员方法
学习目标

类的定义和使用
可以用类去封装属性,并基于类创建出一个个的对象来使用

类中定义的属性(变量),称之为成员变量
类中定义的行为(函数),称之为成员方法
总结

类和对象
学习目标

现实世界的物和类 归结为两大特征 属性和行为
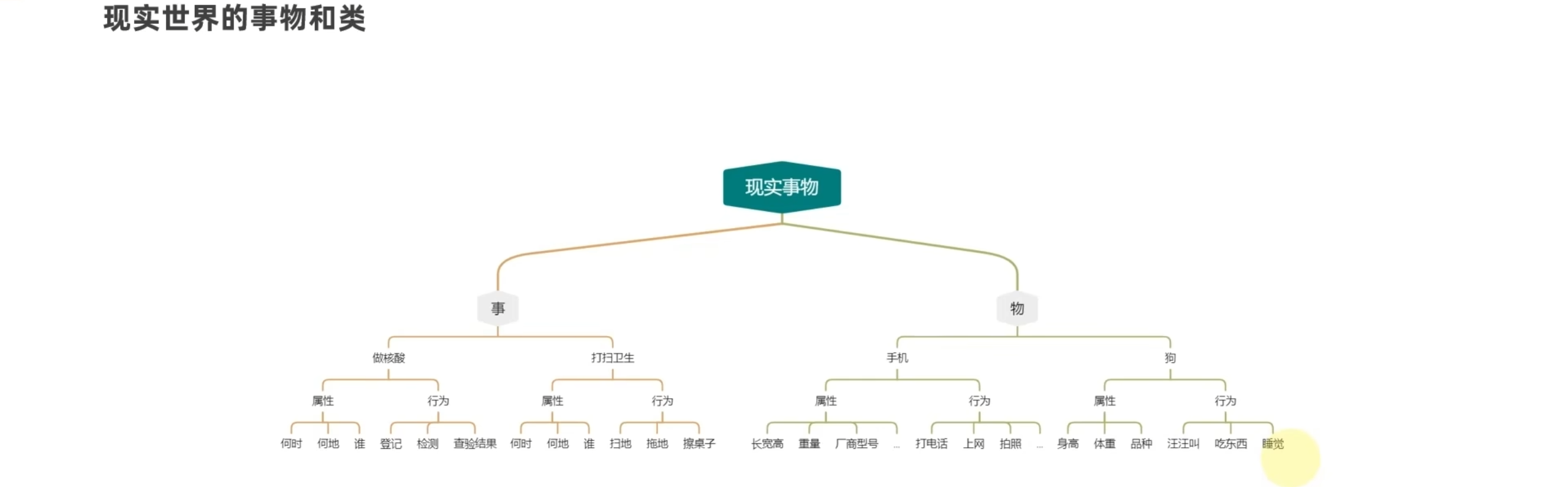
既然类已经能够描述所有现实事物,那为什么还要创造对象呢?
因为类只是程序内的“设计图纸”,还需要基于图纸生产实体(对象),才能正常工作→面向对象编程
代码演示
"""
演示类和对象的关系,即面向对象的变成套路
"""
# 设计一个闹钟类
class Clock:
id = None
price = None
def ring(self):
import winsound
winsound.Beep(2000, 3000)
# 构建2个闹钟对象(clock1、clock2)并让其工作
clock1 = Clock()
clock1.id = "003032"
clock1.price = 19.99
print(f"闹钟ID:{clock1.id},价格:{clock1.price}")
clock1.ring()
clock2 = Clock()
clock2.id = "003033"
clock2.price = 21.99
print(f"闹钟ID:{clock2.id},价格:{clock2.price}")
clock2.ring()
总结

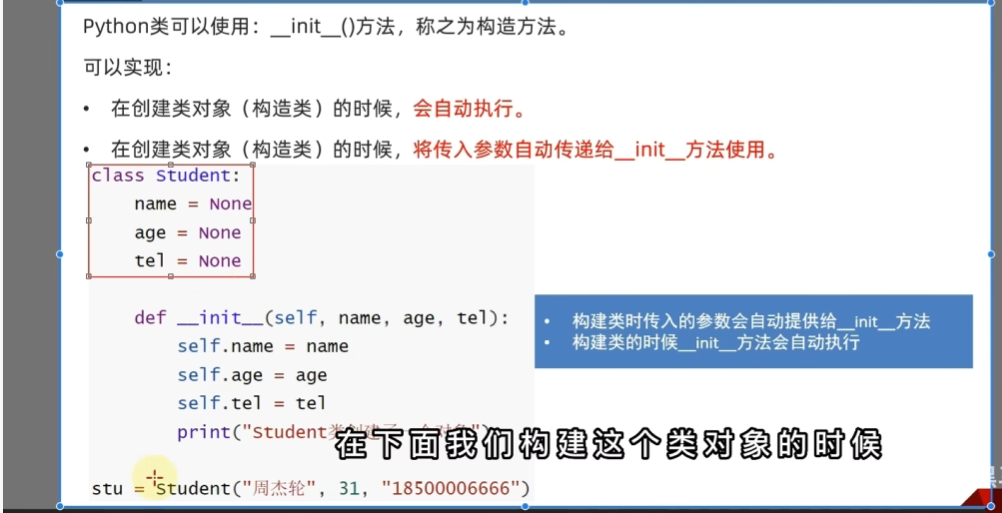
构造方法
属性(成员变量)的赋值
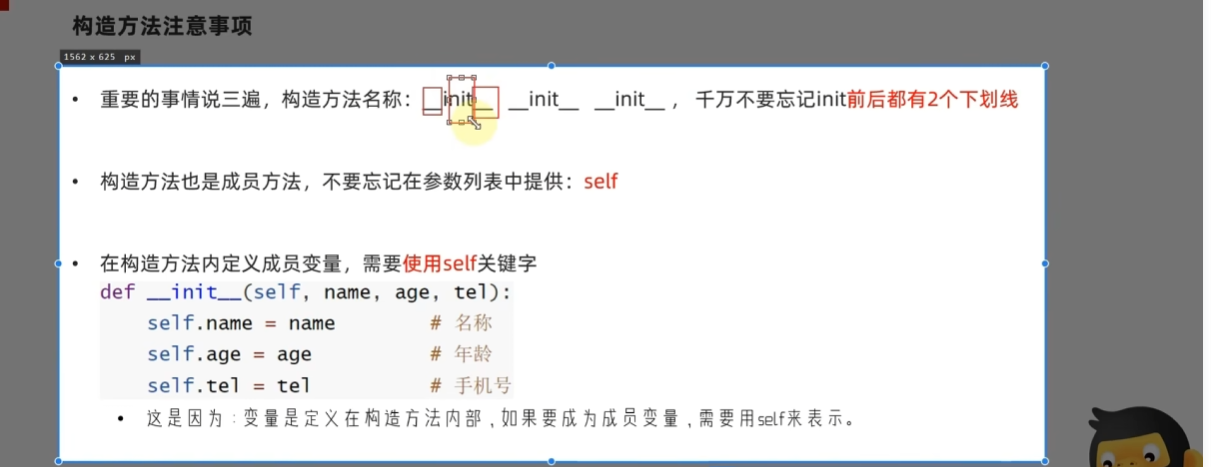
构造方法注意事项(3条)
总结

课后作业
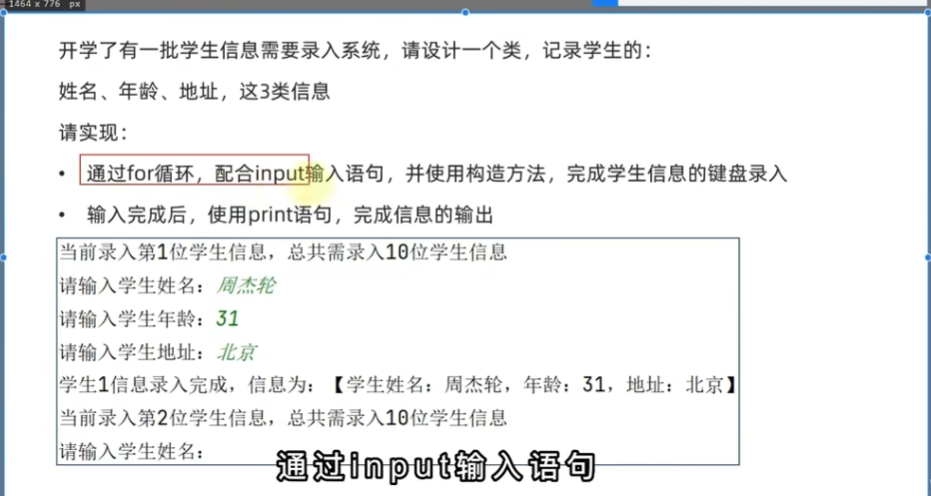
"""
学生信息录入
"""
class Student:
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
def main():
students = []
total_students = 10
for i in range(total_students):
print(f"当前录入第{i+1}位学生信息,总共需要录入{total_students}位学生信息")
name = input("请输入学生姓名")
age = input("请输入学生年龄:")
address = input("请输入学生地址:")
student = Student(name, age, address) # 构建一个对象
students.append(student)
print(f"学生{i+1}信息录入完成,信息为:学生姓名:{name}, 年龄:{31}, 地址{address}")
if __name__ == '__main__':
main()
忘记for循环怎么使用了
作业知识点:
for 循环在 Python 中非常灵活,不仅可以遍历已经存在的数据集(如列表、元组、字典、集合等),还可以通过 range() 函数或其他生成器来控制循环的执行次数,从而实现特定的逻辑。
结合 input() 函数,for 循环可以用来实现用户交互,收集用户输入的信息,并根据这些信息执行相应的操作。这种模式在需要从用户那里获取多个输入或执行重复任务时非常有用。例如:
- 数据录入:录入多条学生信息。
- 菜单选择:显示一个菜单,让用户选择不同的选项,然后根据选择执行不同的操作。
- 重复任务:执行需要重复多次的任务,如文件处理、数据处理等。
### 其他内置方法
